
ch2 内存地址
内存地址
程序员可以随意的指定内存地址,就好像直接访问内存单元中的内容一样。但是当处理器是8086系列时,需要讨论一下下面的三种地址:
- 逻辑地址,包含在机器语言指令中,用来特别制定操作数或者指令的地址。这类地址体现了众所周知的8086分段架构,这种架构能够使得WIndows程序员将他们的程序分成段(segment)。每个逻辑地址由段和偏移组成,偏移代表的是里段首的距离。
- 线性地址/虚拟地址,直观的例子,STM32的虚拟地址是4GB。
- 物理地址,用来访问实际内存芯片中的内存单元。物理地址指的是一类电子信号,能够被发送,从微处理器的地址引脚到内存总线。物理地址表现为32位或者36位的无符号整数。
内存管理单元(MMU)能够把逻辑地址转换成线性地址,通过一个被称为分段单元(segment unit)的物理电路。随后,一个二级电路,被称为分页单元(paging unit),将线性地址转为物理地址。

在多处理器系统,所有的CPU共享同一片内存。这意味着不同的CPU可以同时访问RAM芯片。由于对RAM的读写操作必须被有序的执行,名为内存仲裁器(memory arbiter)的硬件电路,被插入在RAM和总线之间。内存仲裁的作用是:如果内存芯片空闲,批准CPU的访问请求;如果内存芯片忙(被其他CPU占用),则延迟这个请求。
即使是在单处理器系统中,也存在内存仲裁硬件,原因是存在DMA控制器,能够同时和CPU访问RAM。
在多处理器系统中,内存仲裁的设计更加复杂,因为有着更加多的端口。例如,在双核的奔腾处理器中,维护着一个双端口的仲裁器(对于每一个内存单元),确保CPU使用内存前,和另一个CPU交换同步信息,然后再访问RAM CHIP。对于编程而言,仲裁是不可见的,因为这完全交给硬件电路实现。
PS:这里的CPU指的是core
Q:我在看Linux操作系统,告诉我,内存仲裁实际上是怎么样的?是每一根内存条一个memory arbiter,还是每一个字节一个memory arbiter,还是每一个字?
A:仲裁发生在内存控制器层级,一个控制器可以管理多根内存条,多通道系统中的每个通道有独立的仲裁逻辑。现代内存系统以缓存行(通常64字节)为最小传输单位,仲裁器处理的是内存事务,不是单个字节或字。
硬件分段
从80286模式开始,Intel微处理器开始以两种不同的方式执行地址转换,分别是:实模式(real mode)和保护模式(protected mode)。下一节讲述,当保护模式开启时,地址转换是如何进行的。大多数情况下,启用实模式的原因是为了保证处理器和旧型号的兼容性,同时允许操作系统启动(bootstrap)
段选择符和分段寄存器
逻辑地址由段标识符和偏移两部分组成。段标识符标识这个地址在哪个段里面,偏移则是告诉相对段首的距离。段标识符是一个16-bit的字段,也被称作段选择符。偏移是一个32-bit的字段。这里只简要介绍,后面会详细介绍的。

为了便于CPU取回段描述符,处理器一共了分段寄存器,用于暂存段描述符。尽管分段寄存器只有六个(cs, ss, ds, es, fs, gs),程序可以复用这些寄存器,通过将他们原本的内容暂存到内存中(稍后会恢复)。这六个寄存器,有三个有特殊作用:
- cs,代码分段寄存器,指向的是包含程序指令的分段
- ss,堆栈分段寄存器,指向的是含有当前程序堆栈的分段
- ds,数据分段寄存器,指向的是含有全局变量和静态数据的分段
剩余的三个分段寄存器是通用的,可以指向任意的数据分段。
特别地,cs寄存器有另外的重要的作用:它包含一个2-bit的字段,能够特别指出当前CPU的特权级别(Current Privilege Level,CPL):
- CPL=0,代表最高级别,Linux中的内核级
- CPL=3,代表用户界别
Linux只用了这两个级别。
段描述符
每一个分段都可以被一个8-byte的段描述符来表示,用来描述分段的属性。(PS:这个按照RTOS里的TCB来理解,用来描述每个Task的属性)。段描述符要么存在全局描述符表(Global Descriptor Table,GDT),或者局部描述符表(Local Descriptor Table,LDT)中。
通常,只定义一个GDT,然而,如果处理器需要创建额外的分段(不同于GDT中的那些段描述符指向的分段),处理器也可以创建他们自己的LDT。GDT在主存储器中的地址和大小被存储在gdtr这个控制寄存器中,同时LDT的地址和大小被存在ldtr控制寄存器中。
关于段描述符,下面有个表格解释了其中不同的字段:

这里存个档,对后面出现的重要字段进行解释:
- S标志,如果是空的,代表指向的是系统分段,里面可能存储有重要的数据结构,例如LDT;否则,就是普通的代码或者数据分段
- Type字段,描述分段类型,以及其访问权限,
- 。。。
由于有不同的分段(代码分段,数据分段,堆栈分段),因此也有不同的段描述符,如下:
- 代码分段描述符,表示这个分段描述符指向的是一个代码分段;代码分段描述符既可以存在于GDT中,也可以存在于LDT中。这个分段描述符设置了S标志,表示指向的分段不是系统分段。
- 数据分段描述符,表示指向数据分段;可以被存在于GDT或者LDT中。这个描述符含有S标志。堆栈分段就是通过通用数据分段来实现的。
- 任务状态分段描述符(TSSD),指向任务状态分段(TSS)。TSS是用来保存处理器的寄存器的(上下文保存)。TSSD只能被存储在GDT中。TSSD的type被设置成11或者9,取决于相应的进程是否正在被处理器执行(A:这样可以避免任务的递归调用)。S标志被设置为0.
- LDT描述符(LDTD),指向包含LDT的分段;LDTD只能出现在GDT中。Type字段被设置为2,S标志设置为0。

下一节会讲一个段描述符是应该被存在GDT还是LDT中。
快速访问段描述符
回顾一下,读逻辑地址由两部分组成:16-bit的段标识符(选择符)和32-bit的段内偏移。并且,分段寄存器中仅仅只保存了段标识符。
为了加速逻辑地址到线性地址的转换,8086处理器提供了一个额外的不可编程寄存器(不可以被程序员设置的)。对于那六个可编程的分段寄存器(cs,ds,ss…),都各自含有一个不可编程的寄存器(CPU resister)。每个不可编程寄存器包含一个8-byte的段描述符(这个段描述符指向的就是分段寄存器中的段标识符对应的分段,晕@.@)。每次段标识符被加载到分段寄存器中时,相应的段描述符也会被从内存家在到相应的不可编程寄存器。然后,逻辑地址到线性地址的翻译就不需要通过额外一次访存来取出GDT或LDT中的段描述符。CPU可以直接从不可编程寄存器中取出相应的段描述符。当分段寄存器中的内容改变时,才需要重新访存GDT和LDT。
两种取段描述符的方法如下:
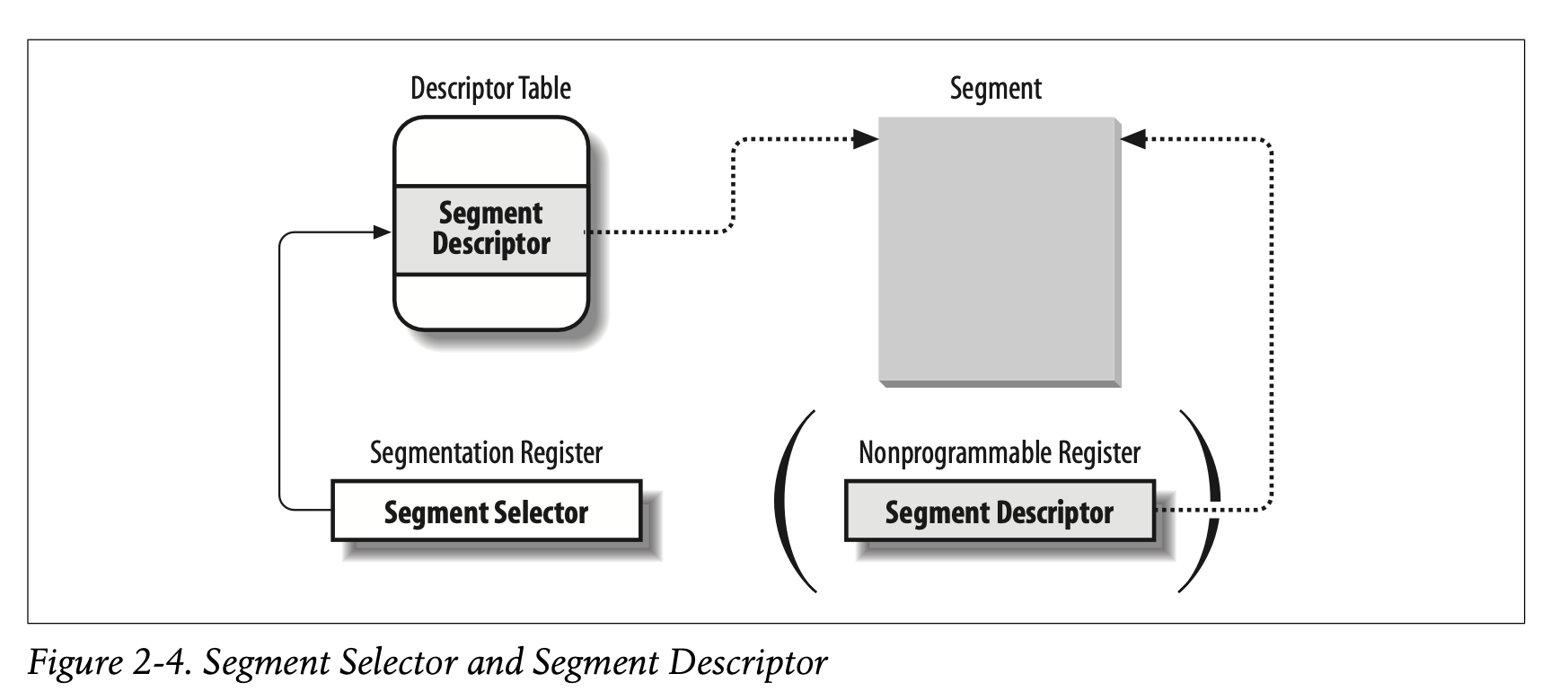
段标识符中有三个字段,如下:

由于段描述符是8字节,其在GDT或LDT中的相对地址是通过将段标识符的13位索引字段乘以8来获得的。例如,GDT的地址是0X0002,0000(这个地址存储在gdtr里),段标识符里的index是2,那么段描述符的地址就是0X0002,0000+(2 * 8)=0X0002,0010。
GDT中的第一个条目始终设置为0。这样可以保证:如果一个逻辑地址的段标识符是NULL,那么这个地址被认定非法,然后导致异常。GDT中能够存储的最大的段描述符的数目为$2^{13}-1$。
分段单元
分段单元是用来将逻辑地址转为线性地址的,具体操作如下:
- 检查TI字段,判断是在哪一个描述符表(GDT or LDT)中存放着分段描述符。如果GDT,那么就从gdtr中取出GDT的线性基地址;如果是ldtr,也是如此。
- 根据段选择符中的index字段,计算段描述符的地址。index字段会乘以8(段描述符的长度8-byte),然后结果会加上gdtr或者ldtr中的基地址。
- 在段描述符里找到Base字段,然后加上段内偏移offset,这样就得到了线性地址。
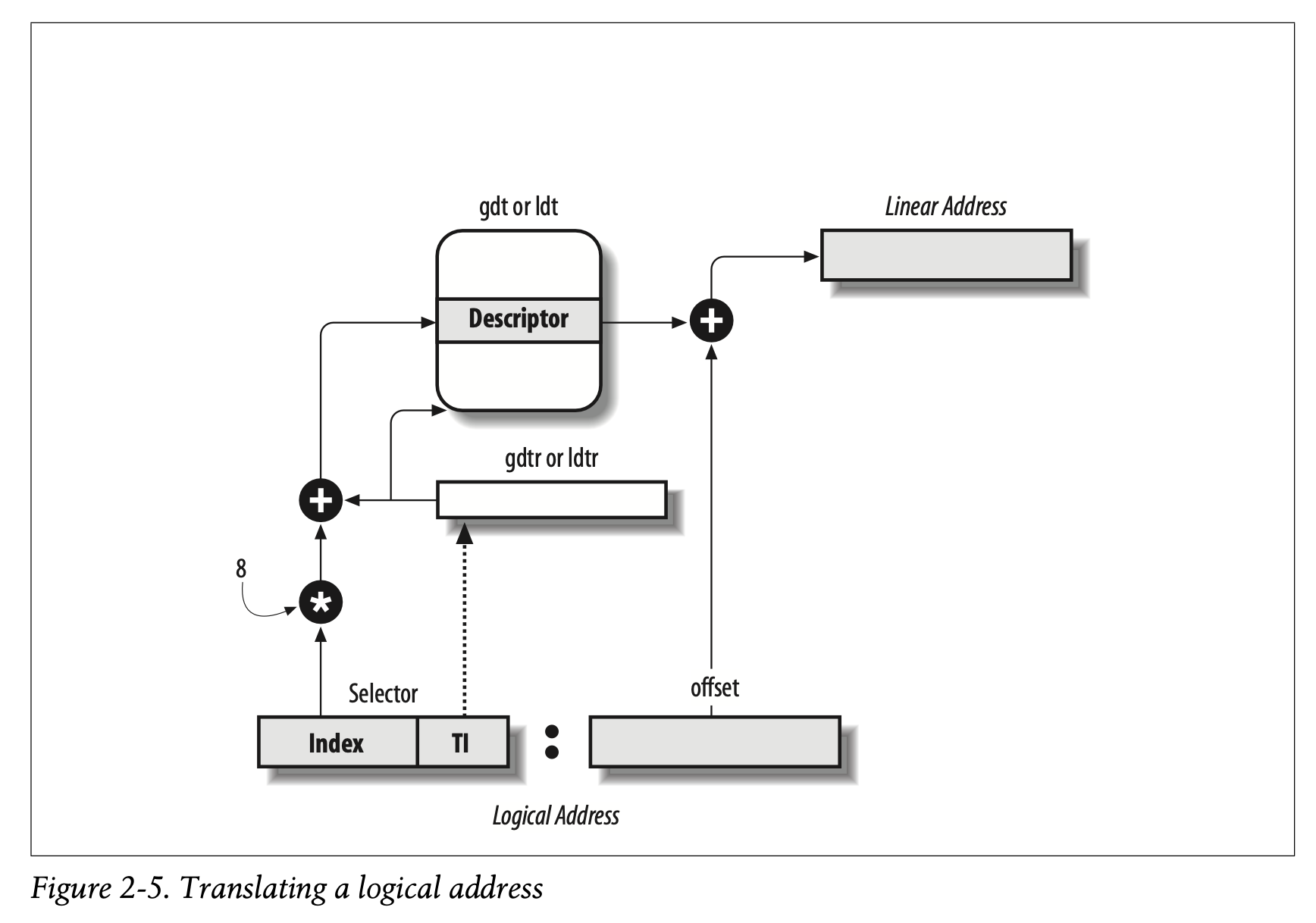
需要注意的是,多亏了不可编程寄存器和分段寄存器关联,只有当分段寄存器不得不改变时,才会执行前两个操作。
Linux中的分段
分段机制已经被包括在8086系处理器里,为的是鼓励程序员将他们的应用程序拆分为逻辑上相邻的实体,例如:子程序、全局or局部数据区域。然而,Linux很有限地使用分段机制。事实上,分段和分页机制在某种程度上是冗余的,因为这两者都能够被用来拆分进程的物理地址空间。例如:1. 分段能够分配不同的线性地址空间给每个进程;2. 分页能够将相同的线性地址空间映射到不同的物理地址空间。Linux偏好分页而不是分段,原因如下:
- 当所有进程共享相同的线性地址集合时,内存管理机制变得更加简单
- Linux的设计目标之一是尽可能的兼容各种不同的架构。其中,RISC架构对分段的支持特别有限。
Linux 2.6版本仅仅在8086架构需要时,才会使用分段。
所有运行在用户级的Linux进程使用相同的分段对(pair of segments)来寻址指令和数据。分别地,这些分段被称作用户代码段(user code segment)和用户数据段(user data segment),下表展示了这四个关键段的分段描述符的字段:
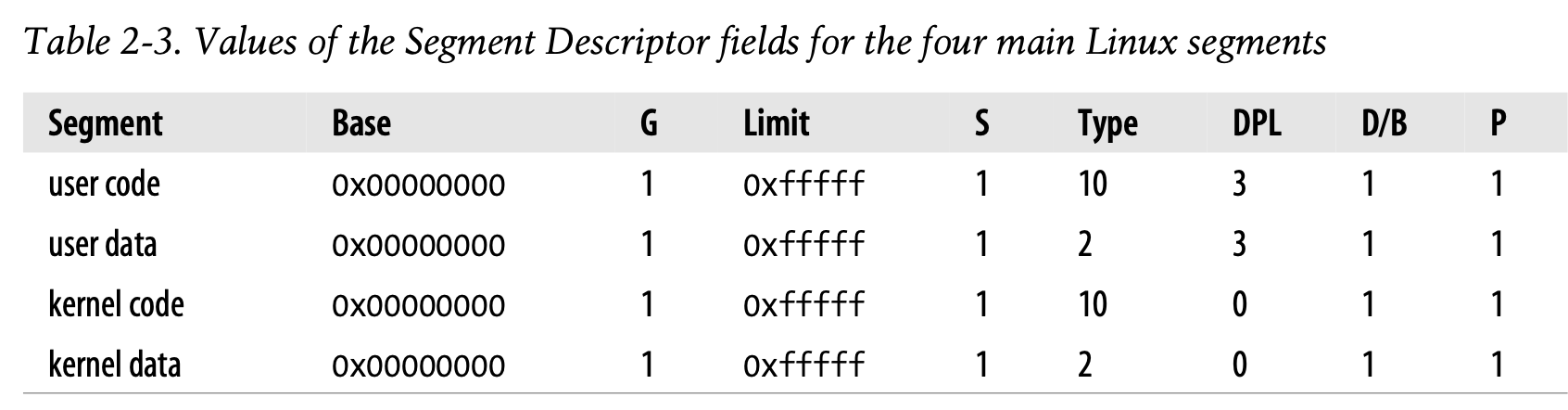
分别地,相应的分段选择符被这些macros所定义:__USER_CS, __USER_DS, __KERNEL_CS, __KERNEL_DS。为了对内核代码段进行寻址,例如,内核仅仅将__KERNEL_CS macro产生的值加载到cs分段寄存器中。
需要注意的是,和这些段相关的线性地址都是从0开始的,直到到达地址的限制值$2^{32}-1$。这意味着,无论是用户态还是内核态的进程,可能会使用同一个逻辑地址。
让所有段从0X0000,0000开的的另一个很重要的结果是,逻辑地址和线性地址保持一致。即,逻辑地址和线性地址的偏移量永远保持一致。
如前所述,CPU的当前特权级别表示,处理器是否处于用户态或者内核态。并且,CPL被cs寄存器中的段选择符的RPL字段所指定。无论何时CPL改变,某些段寄存器肯定会更新。例如,当CPL=3,表示用户态,ds寄存器一定持有用户数据段的段选择符;然而, 当CPL=0时,ds寄存器存放的肯定是内核数据段的数据选择符。
另一个很相似的例子是,对于ss寄存器(堆栈分段寄存器),当CPL=3时,指向的一定是用户态堆栈(用用户数据段实现的);当CPL=0时,ss寄存器指向的一定是内核态堆栈(有内核数据段实现)。当处理器从用户态切换到内核态时,Linux始终要确认:ss寄存器持有内核数据段的段选择符。
当保存一个指针到一条指令或者一个数据结构时,内核不需要保存逻辑地址的段选择符,因为ss寄存器中已经包含了当前的段选择符。例如,当内核调用一个函数,内核会执行一个call汇编语言指令,这个指令仅仅指定它逻辑地址的偏移量;段选择符被隐式地选择了,因为cs寄存器中持有的就是段选择符。由于只有一种类型的段,能够在内核态下执行,也就是在__KERNEL_CS中标识的代码段,无论何时CPU切换到内核态,内核都会将__KERNEL_CS加载到cs寄存器。另一个很相似的例子就是,指向内核数据结构的指针(隐式被ds寄存器加载),指向用户数据结构时,内核则会显式使用es寄存器。
除了上面讨论的四种分段,Linux还使用了一些其他特殊的段,将会在下一节讨论。
Linux中的全局描述符表
在单核系统中,只有一个GDT,而在多核系统中,每个CPU都有一个GDT。所有的GDT都被保存在名为cpu_gdt_table数组里,而这些GDT的地址和大小(被用来初始化gtdr寄存器)被存储在名为cpu_gdt_descr的数组里。如果你越过Linux源代码的索引,你会发现这些符号被定义在名为arch/i386/kernel/head.S放入文件里。这本书里列举的每一个宏、函数、符号,都可在源文件索引里找到。
GDT的布局如下:

每个GDT包含18个段描述符,14个null、没使用的、或者保留的条目。没使用的条目的作用是:当段描述符被访问时,可以被遗弃保留在32-byte的硬件缓存中。
18个包含在每个GDT中的段描述符指向下面描述的这些段:
- 用户/内核 代码/数据段
- 一个任务状态段(TSS),系统中每个处理器的TSS都不同。指向TSS的线性地址空间,是,指向内核数据段线性地址空间,的一个子集(这句话的意思大概是TSS是内核数据段的子集?)。TSS被顺序的存储在
init_tss数组里;特别地,第n个CPU的TSS的Base字段,指向的是init_tss的第n个元素(也就是说,有几个CPU,init_tss的长度就是多少)。G字段被清除了(置零),Limit字段被设置为了0xeb(TSS段长236-byte)。Type字段被设置为9或者11,DPL字段被设置为0,因为处于用户态的处理器不被允许去访问TSS段。 - 包含所有默认局部描述符表(LDT)的段,通常所有处理器共享一个。
- 三个线程局部存储段(TLS),这个机制允许多线程程序来充分利用至多三个段,来持有每个线程局部的数据(本地数据)。两个系统调用:
set_thread-area(), get_thread_area(),分别表示为正在执行的进程创建和释放TLS段。 - 三个有关高级电源管理(APM)的段,BIOS代码使用这些段,当Linux APM驱动调用BIOS函数来获取或者设置APM驱动的状态。这些段可能会用到常规的代码或者数据分段。
- 五个和“即插即用”(Plug and Play, PnP)BIOS服务相关的分段。当PnP驱动调用BIOS函数来检测PnP设备使用的资源时,会用到这些段。这些段也是常规的代码或者数据分段。
- 一个特殊的TSS段(任务状态段),这个段被内核用来捕获异常。(”Double Fault” exceptions)
如前面所述。每个处理器都有GDT的一份拷贝。所有GDT的拷贝保存着相同的条目,除了某些少数情况。首先,每个处理器都有它独有的TSS段,因此GDT中相应的条目也会有所不同;更进一步,少数GDT中的条目可能取决于CPU正在运行的进程(例如LDT和TLS段描述符);最后,在某种情况下,处理器可能会短暂地更改GDT拷贝中的条目,例如,当调用APM BIOS过程时。
Linux中的局部描述符表
大部分Linux用户态的应用程序不回用到LDT,因此内核定义了一个默认的LDT,在所有进程中共享。默认的LDT被存在名为default_ldt的数组中。这个数组包含五个条目,然而只有两个条目能够被内核高效地使用:a call gate for iBCS executables, and a call gate for Solaris/x86 executables。调用门是8086处理器提供的一种机制,当CPU执行预先定义好的函数时,用来改变当前的特签级别。这本书不会过多讨论调用门,详细信息可以在Intel文档里找到。
然而,在某些特殊情况下,进程可能会需要设置他们自己的LDT。例如,当运行Wine时,Wine执行Windows下的面向分段应用程序(意思应该就是使用分段),进程设置自己的LDT就很有用。系统调用modify_ldt()允许进程设置自己的LDT。
任何通过modify_ldt()创建的自定义LDT,也需要它自己独有的分段。当一个处理器开始运行有自定义LDT的进程时,这个处理器对应的GDT拷贝中的LDT条目也会改变。
用户态的应用程序也能够通过modify_ldt()来分配新的分段。然而,内核永远不会使用这些分段,并且,也不回去追踪相应的段描述符,因为他们被包含在进程定制化的LDT中。
硬件分页原理
分页单元将线性地址转换成物理地址。分页单元的关键任务之一是检查访问类型是否超出了线性地址的访问权限(就是检查权限吧??)。如果访存是非法的,分页单元会产生一个分页异常(Page Fault exception)。
为了效率,线性地址被划分为组,以固定的长度,称为分页。在一个分页内的连续线性地址,会被同样映射到连续的一块物理地址。通过这种方式,内核可以指定分页的物理地址和访问权限,而不是线性地址。根据这个,我们应该使用分页来代指一束线性地址以及其中包含的数据。
分页单元认为RAM是被分成了定长的页帧(Page Frames,好像也被称为页框,有时候也会指为物理分页Physical Pages)每个页帧包含一个分页,页帧和分页长度保持一致。页框是主存的主要构成成分,因此页框是一块存储区域。对分页和页框进行区分十分重要,前者只是一块数据,可能被存储在任何一个页框内,甚至是磁盘上(swap
将线性地址映射到物理地址的数据结构被称为页表(page table)页表被存储在主存当中,并且,在使用页表之前,必须由Linux内核进行正确的初始化。
从80386开始,所有的8086处理器都支持分页,通过设置控制寄存器cr0的 PG标志,能够开启分页,当设置PG=0时,线性地址将会被直接解释为物理地址(不作任何转换)
常规分页
从80386开始,Intel处理器的分页单元处理4KB的分页。
将32-bit的线性地址拆成三部分:
- 目录(Directory),10-bit,是最重要的部分
- 表(Table),中间的10-bit
- 偏移(offset),最后的12-bit
线性地址的翻译通过两步完成,每一步都包含一种类型的翻译表(translation table)。第一个翻译表是页目录(Page Directory),第二个是页表(Page Table)
二级表的目的是为了减少处理页表所消耗的内存。假如简单使用一级页表来进行翻译,将需要最多$2^{20}$的条目来表示每个进程的页表(一个条目4-byte,一共就是4-MB内存),如果一个进程申请了4GB的虚拟内存,但是其实大部分没用到,那么页表开销依然是4MB。二级页表这样做的好处是,仅仅只有虚拟地址区域确实被使用了,才会建立对应的页表。
任何一个运行的进程一定有页目录。然而,没有必要对进程的所有页表都分配内存(这样和一级页表没有区别),只有当进程确实需要页表的时候,再给对应的页表分配内存,这样更加高效。
PS:Page Directory,页目录,感觉叫页表目录更加合适,因为页目录其实是页表的索引。
正在使用的页目录的物理地址被存储在名为cr3的控制寄存器中。线性地址的Directory字段决定了页目录中的条目,这个条目指向的是正确的页表。更进一步,线性地址的Table字段决定怎么在页表中找到正确的条目,这个条目持有的是包含page的page frame的物理地址。最后,offset字段决定了page frame的的相对偏移。因为offset是12-bit,按byte寻址,那么每一个含有$2^{12}$,也就是4096-byte。
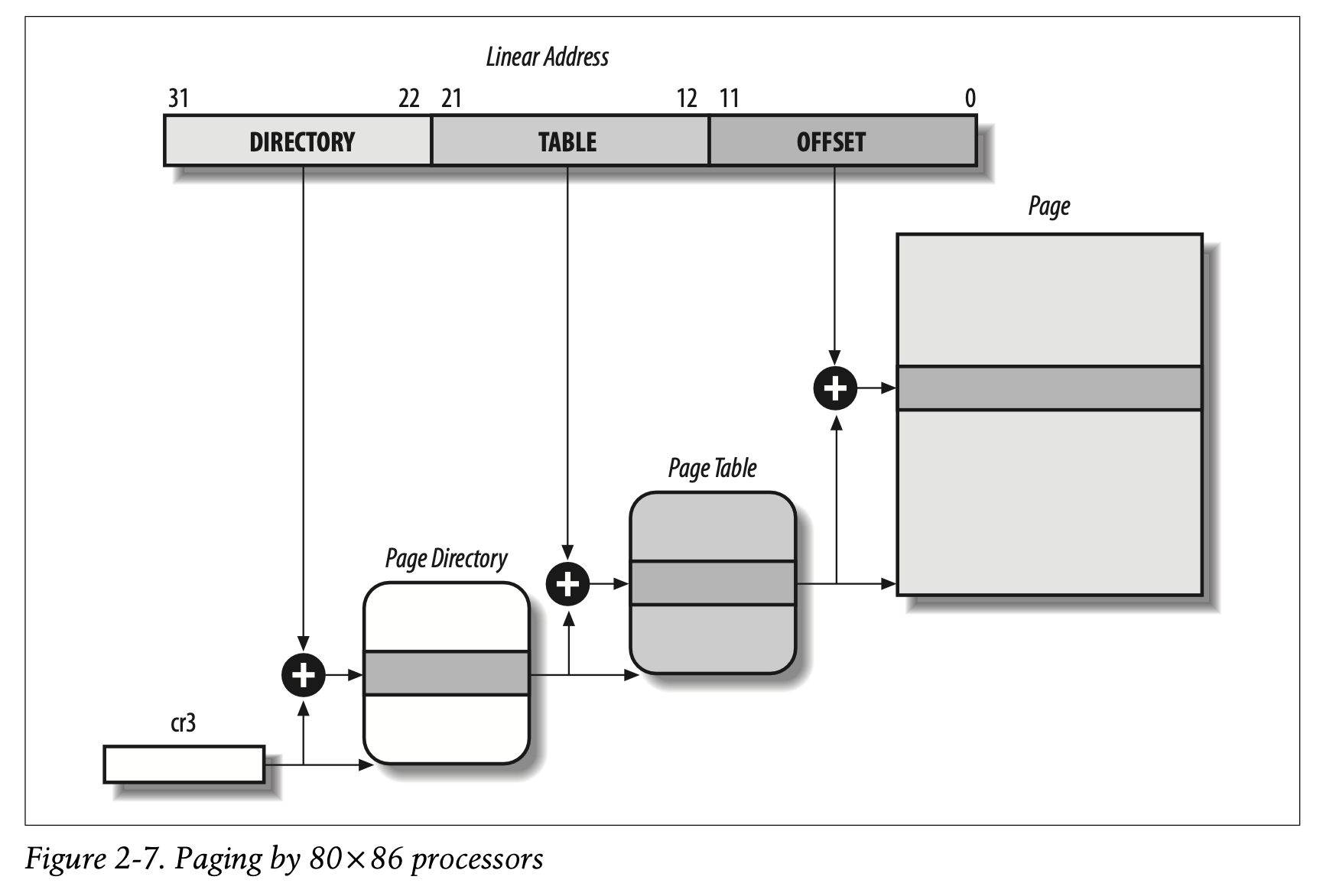
页目录和页表的长度都是10-bit,因此,最多1024条目。所以虚拟内存的最大值是$1024\times 1024\times 4096B$,也就是4GB,刚好cover所有的memory cell。
页目录和页表中的条目含有相同的结构,每一个条目包含下面的字段:
- 。。。略
扩展分页
从奔腾型号开始,8086位处理器引入了扩展分页,可以将页帧大小从4KB提升到4MB。扩展分页用于将大段连续的线性地址范围转换到相应的物理部分。在这种情况下,内核可以不依赖中间页表来进行地址翻译,更加节省TLB条目的空间(后面会讲)
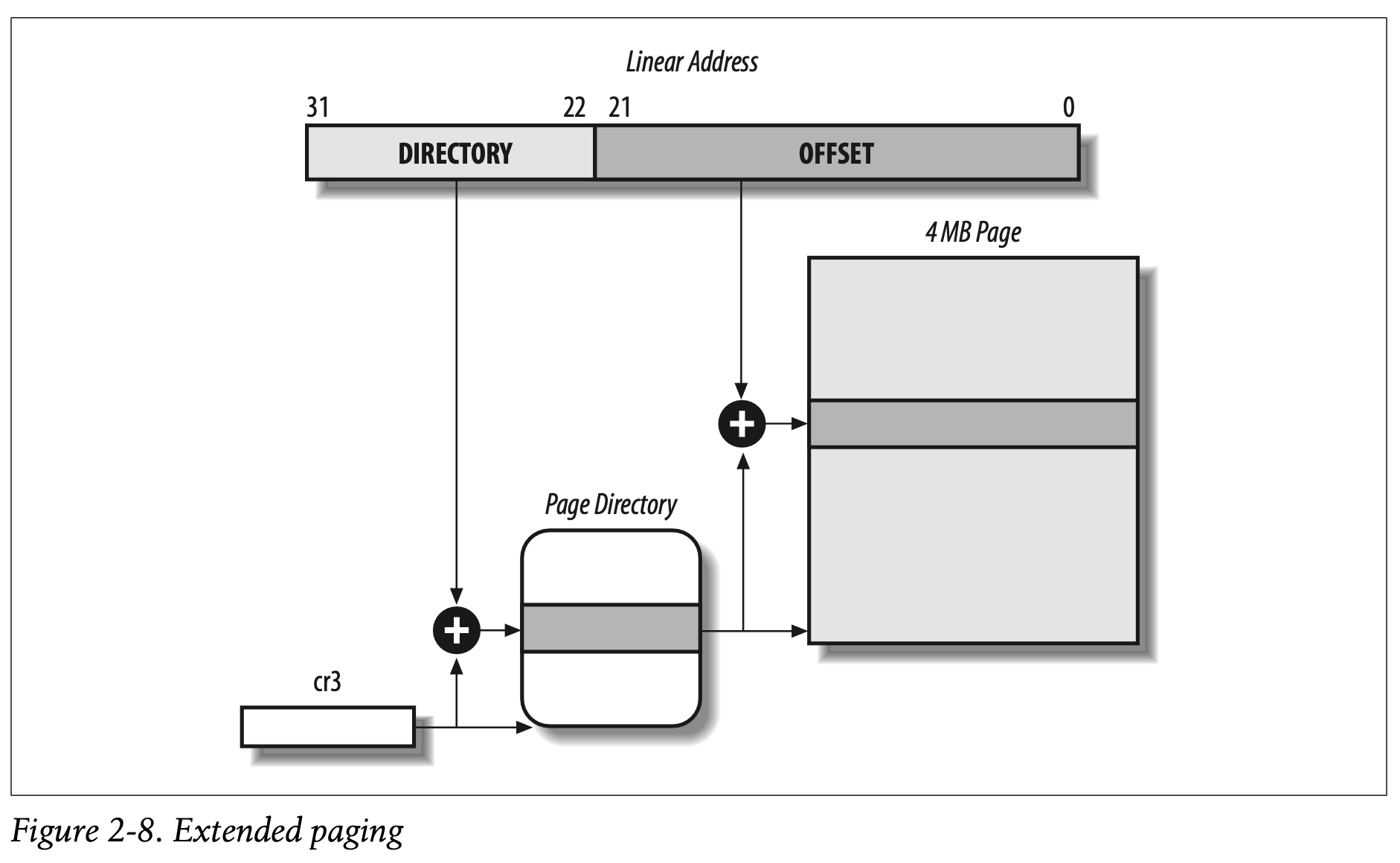
通过设置页目录里的Page Size标志来开启扩展分页。进而,线性地址被划分为两部分:10位的目录和22位的偏移(对应4MB的页帧)
扩展分页的页目录和常规分页的页目录相同,除了下面几点:
Page Size标志必须被设置- 20位的物理地址中,只有前10位是有效的,因为每一个物理地址都是按照4MB的边界对齐的,因此后22位全部是0.
扩展分页和常规分页共存。通过设置处理器的cr4寄存器中的PSE标志即可。
硬件保护方案
分页单元使用了一个和分段单元不同的保护方案。尽管8086处理器允许四种可能的优先级来分段,只有两种特权级别和分页以及页表相关,因为优先级被User/Supervisor标志所控制。当这个标志为0时,相应的页只有在CPL(当前特权级别)小于3时(对Linux而言,也就是内核态下),才能够被访存。当标志为1时,相应的页可以在任何状态下被访存。
此外,不像分段那样有三种访问权限(读,写,执行),分页只有两种访问权限(读和写)。当页目录或者页表项中的Read/Write标志为0时,相对应的页表只有读权限;反之,则拥有读写权限。
常规分页的一个例子
举个简单的例子,帮助我们理解常规分页是如何工作的。假设,操作系统内核为一个正在运行的进程分配的线性地址空间是0x2000,0000-0x2003,ffff。这块线性地址区域包含了64个分页。在这里,我们并不关心这64个分页对应的物理页帧是什么,事实上,有些页帧可能甚至不在主存中。在这里,我们只对页表项中的保留字段感兴趣。
这篇空间的前十位是相同的,代表的正是页表目录,我们从这里开始。取出前十位:
1 | 0b0010 0000 00=0b00,1000,0000=0x0b0=128 |
也就是说,这个页表目录,指向的索引是整张页表目录的第129个条目,这个条目中存放的就是这个进程对应的页表的物理地址,如果这个进程没有被分配其他的线性地址,其他1023个条目中存放的就都是0.
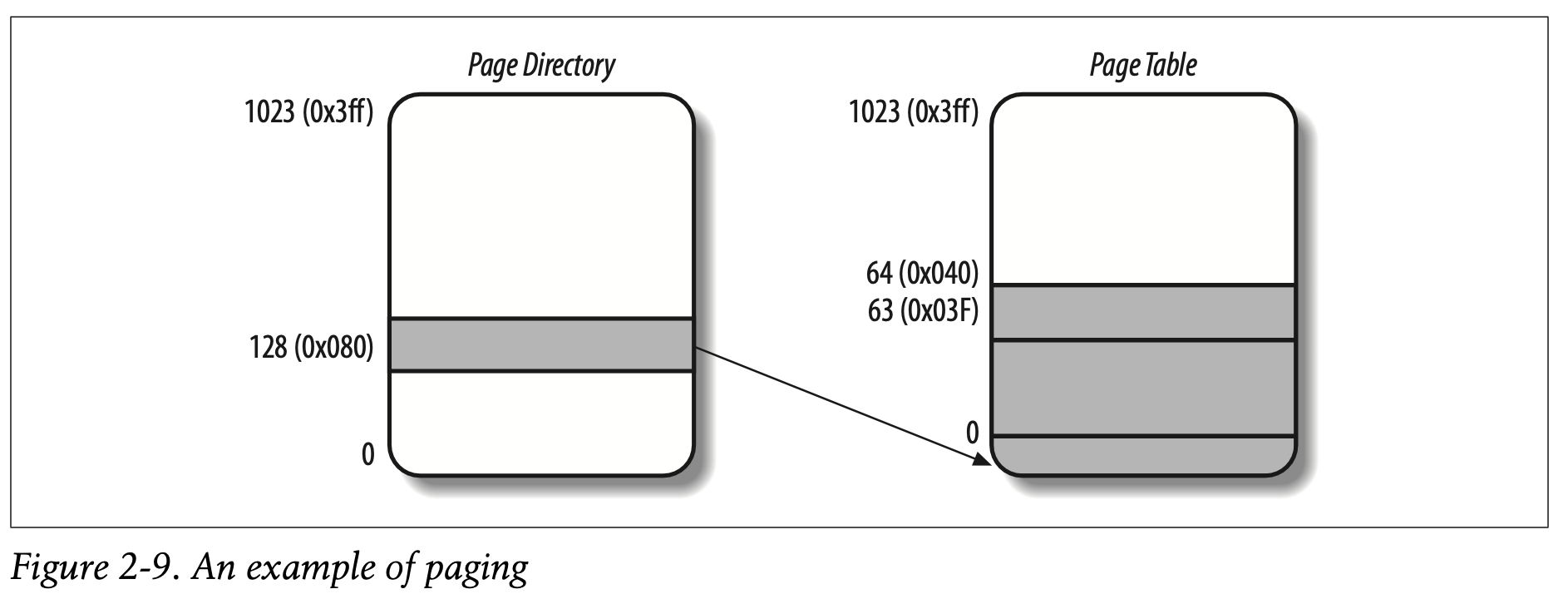
在上述的假设中,页表目录中只有一个条目是有效的,其余全是0,也就是说这个进程只有一张页表。更进一步,操作系统分配的页表是0x000-0x3f,换算成十进制就是0到63。也就是说,这张唯一的页表里,只有前64个条目里存放着物理地址,其余的条目里全是0。这里已经体现出二级页表的好处了,虽然操作系统分配的是64张页表,但其实进程只用到了一张页表,极大地节省了内存空间(维护64张页表->维护一张页表目录表+一张页表)
假设这个进程需要读取一个字节,对应的线性地址是0x2002,1406。这个地址会被分页单元捕获,然后按照下面步骤进行翻译:
- 首先取出最大的10位,页表目录索引字段,也就是
0x80,来找到相应的页表的物理地址 - 其次,取出中间的十位,也就是
0x21,来找到页表中哪一项条目是这个字节的物理地址对应的页帧。 - 最终,取出最后12位
0x406,和取出的页帧concat,得到最终这个页帧中的字节所在的位置。
如果页表的第0x21个条目的Present标志被清除,那么就代表这个页表不在主存(页帧)中,在这种情况下,分页单元会报告一个Page Fault异常,当转换这个线性地址时。同样,下面这种情况也会报告异常,当进程尝试去访问超出操作系统分配的线性空间的地址(也就是超出0x2000,0000-0x2003,ffff了),访问没有分配的线性地址,最后得到的页表条目会是0,当然,他们的Present标志也是被清除的。
物理地址扩展分页机制
处理器能够使用的RAM总量被连接在地址总线上的地址引脚所限制。从旧的80386 Intel处理器奔腾处理器,使用的都是32位的物理地址。理论上,这类系统最多支持4GB的RAM。实际上,由于用户态处理器对线性地址的需求,内核不能直接分配超过1GB的RAM。
然而,有些大型服务器需要同时运行成百上千的线程,需要的RAM超出了4GB,推动了Intel扩展32-bit的8086架构的地址总数。
为了解决内存不够的挑战,Intel将内存引脚数从32提升到36。从奔腾pro处理器开始,所有的Intel处理器能够以36位的方式寻址,寻址空间大小为$2^{36}=64GB$。然而,只有引入新的分页机制,将32-bit的线性地址转换成36-bit的物理地址,才能够利用增加的物理地址。
在奔腾pro处理器上,Intel引入了一种被称为物理地址扩展(Physical Address extension, PAE)的机制。
PAE开启的条件是:设置控制寄存器cr4的PAE标志。
PS:36-bit没啥意思,这里直接jump到64-bit了,fxxk intel
64-bit架构的分页机制
前面讲述了32-bit架构下,使用二级分页能够很好地工作。然而,在64-bit下,这样使用不合适,原因如下:
一般的分页大小是4KB,需要消耗12位地址,因此还剩余52位。如果我们只使用64位中的48位来寻址(寻址空间256TB),有12位分配给页内偏移,36位分配给页目录和页表。平均分的话,页目录和页表都是18位,那么,操作系统中对应的页表目录表和页表有$2^{18}$个条目。
PS:以页表目录表举例,里面存放的是页表的物理地址,64-bit,那么一张页表目录表的大小就是$2^{24}bit=16Mbit=2MB$。
因此,所有硬件上支持分页的系统,对于64-bit的处理器,都会使用额外的分页级别。具体使用几级分页取决于特定的处理器类型,平台架构。
硬件缓存
现代微处理器的时钟率都是以GHz为单位的,而DRAM的访存时间通常在数百时钟周期。这意味着,当执行的指令需要从RAM中取操作数,或者是存结果到RAM中时,CPU会被限制很多,因为数百的时钟周期被用于访存。
硬件缓存引入的目的是减少CPU和RAM速度不匹配的问题。硬件缓存是基于局部性原则,这对于程序和数据都成立。这是由于程序中的循环结构和线性数组中的相近的数据,近期使用最多的地址有很高概率在未来被再次访问。因此,引入一种更快更小的存储空间,来存放这些代码和数据,是有意义的。出于这个目的,一种被称为line的单元被引入到8086架构中。这些单元由几行连续的字节组成,这些字节以突发模式传输,在低速的DRAM中和高速的猜测板载SRAM中(SRAM被用于实现cache)
cache又被划分为了几个子集。在极端情况下,如果主存中的某一行永远被存储在cache中确定的同样的位置,那么cache能够被直接映射(direct mapped)。另一种极端情况下,cache是全关联的(fully associative),这意味着主存中的任意一行可以被存储在cache中的任意位置。但是,大部分的cache都是N路组关联的(N-way set associative),主存中的任意一行能够被存储在N行缓存中的任意一行。例如,内存中的一行能够被存储在2路组关联中的两个不同行。
缓存单元被插入在分页单元和主存之间。不仅于此,缓存单元包含硬件缓存和缓存控制器。硬件缓存里存放的就是实际的内存行;缓存控制器里存放的是数组,数组中的每一个条目,包含了tag字段和其他用于描述这个缓存行的标志。tag由几个bit组成,缓存控制器通过tag来识别当前缓存行具体映射到内存的哪个位置。另外,物理地址通常被拆分为三部分,首先的就是tag,中间部分是缓存控制器的子集索引(?),最后是行内偏移。
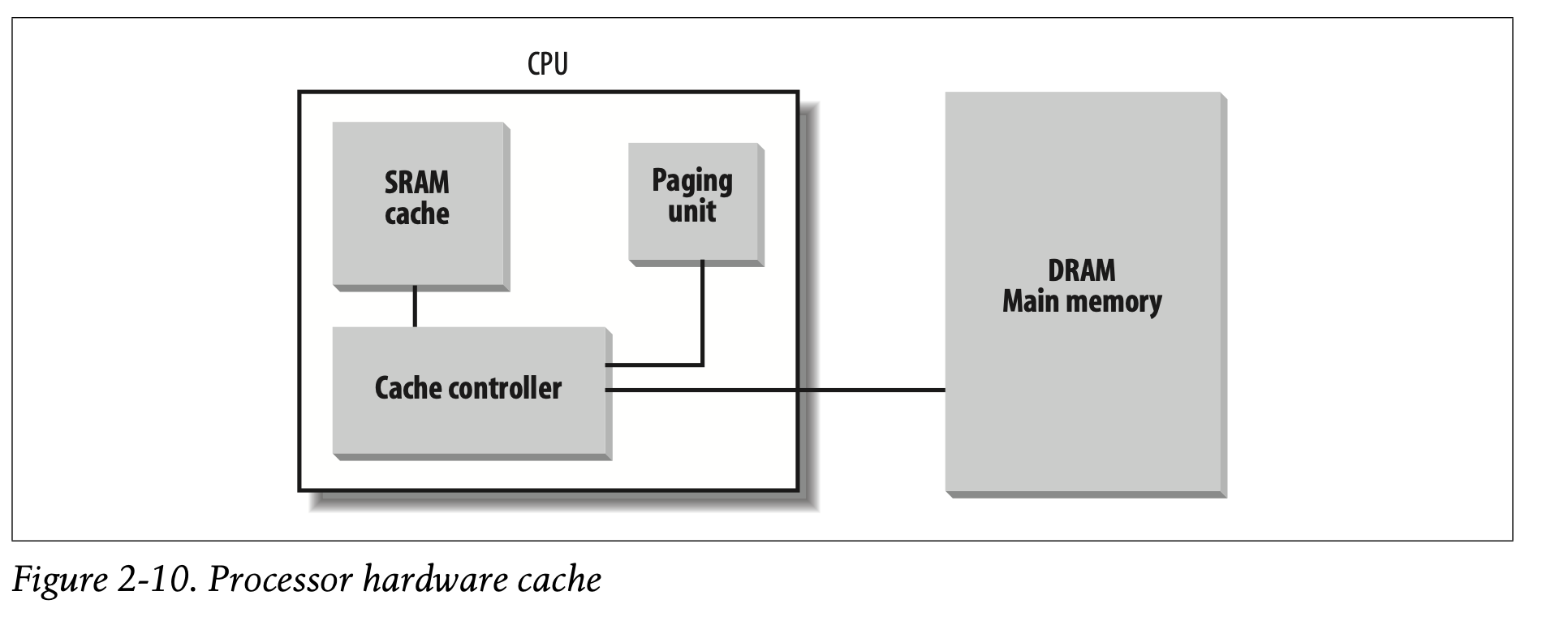
当CPU访存时,首先从物理地址中提取出子集索引,然后比较子集中的tag,如果tag匹配成功,cache命中;反之,cache miss
当cache hit时,根据访问权限的不同,缓存控制器有两种不同的表现。对于read操作,控制器选择cache line中的数据,然后传输到CPU的寄存器中即可,无需访存,从这里可以看出缓存机制的优势。对于write操作,控制器会执行两种不同的策略:write-through和write-back。对于write-through策略,控制器会对RAM和缓存行同时执行write操作。对于write-back策略,更加高效,只有cache line被更新,而memory line不被更新。当然,最终memory line肯定被被更新的,只有当这些操作出现时:CPU执行了刷新cache entries的操作,或者是硬件刷新信号,通常是在cache miss后发生,cache controller才会将cache line写回RAM的memory line中。
当cache miss时,cache line被写会到内存中,如果有必要的话,正确的memory line会被从RAM加载到cache。
多处理器系统中,每个处理器都有各自的硬件缓存,因此,需要额外的硬件电路来对不同CPU的cache进行同步。每个CPU都有各自的本地缓存,因此缓存更新变得更加费时。无论什么时候,CPU进行缓存更新,他必须要检查相同的数据是否被存放在其他处理器的硬件缓存中。如果有,那么该CPU需要提醒其他CPU相关的cache line进行更新。这种操作通常被称为缓存探测(cache snooping)。幸运的事,缓存探测是硬件级别的操作,内核不需要关心这个怎么实现。
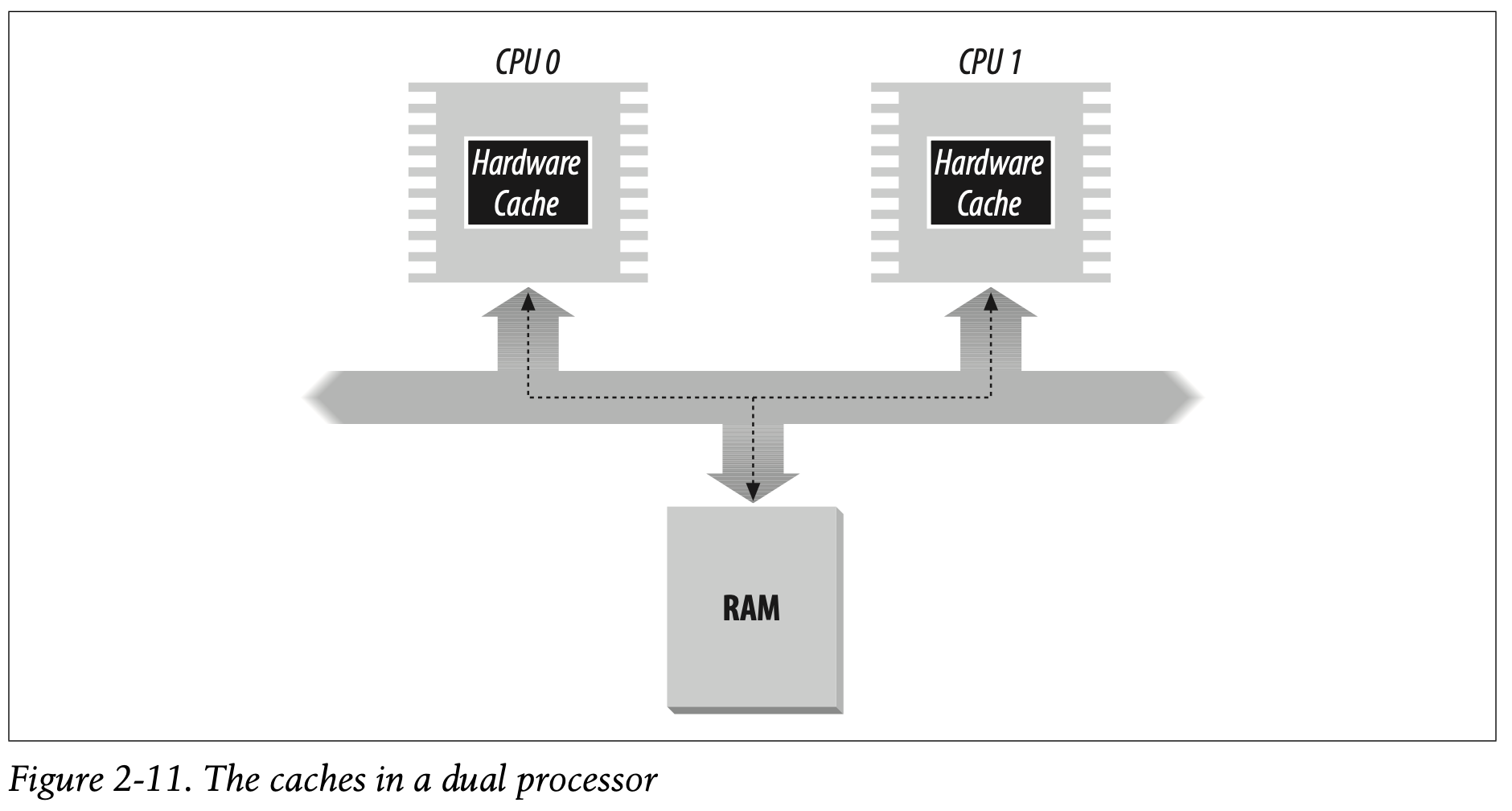
缓存技术进步十分快。例如,第一代的奔腾型号包含了单独的板载缓存L1-cache。往后更先进的型号包含了更大,略慢的板载缓存L2-cache, L3-cache等等。不同级别之间的缓存一致性是通过硬件来实现的,Linux忽略了这些硬件细节,并且假定只有一个cache level。
cr0寄存器中的CD标志用于开启或者关闭缓存电路。NW标志则是用于指定write-through或write-back策略。
关于奔腾处理器的缓存机制,另一个比较有意思的特性是,它可以让不同的page frame有不同的缓存管理策略。为了达到这个目的,Page Directory和Page Table中的每一个条目包含了两个标志:PCD(Page Cache Disable),这个标志具体说明了:当访问这个page中的数据时,是否要启用cache;PWT(Page Wtite-Through),这个标志指明了,当需要对某一页中的数据执行写操作时,用write-through还是write-back策略。Linux清楚了Page Directory和Page Table中的所有PCD和PWT标志,这意味着,cache永远启用,并且对于write操作,永远使用write-back策略。
翻译查找缓冲区(TLB)
除了通用目的的硬件缓存(memory line -> cache line),8086处理器还包含额外的缓存TLB,来加速线性地址的转录。当首次翻译一个线性地址时,CPU是通过一种很慢的方式(访问内存中的Page Table,Page Directory)来计算,得到物理地址的。这个物理地址随后会被存储在TLB的条目中,方便后续访问同一个线性地址时,能够被快速的访问。
在多处理器系统中,每一个CPU都有它自己的TLB,被称为本地TLB(local TLB)。和硬件缓存相反,TLB中的相应的条目不需要同步,因为正在运行的不同进程,可能是相同的线性地址映射到不同的物理地址。
当cr3的控制寄存器被修改了,硬件会自动将local TLB中的所有条目无效化(置0),因为新的页表正在被使用,TLB中的条目指向的是旧数据。
Linux中的分页
Linux采用了一个常规的分页模型,能够同时适配32-bit和64-bit的架构。之前解释过,对于64-bit的架构,需要更高级别的page level。到Linux 2.6.10,Linux分页模型支持三级分页;从Linux 2.6.11开始,采用了四级分页模型。线性地址被分成四份:
- Page Global Directory
- Page Upper Directory
- Page Middle Directory
- Page Table
Page n Directory里存放的是Page n-1 Directories的物理地址。Page Table中每一个实体指向Page Frame。因此,线性地址被拆分为五部分。下图中没有显示每一个部分有多少位,因为这取决于具体的架构。
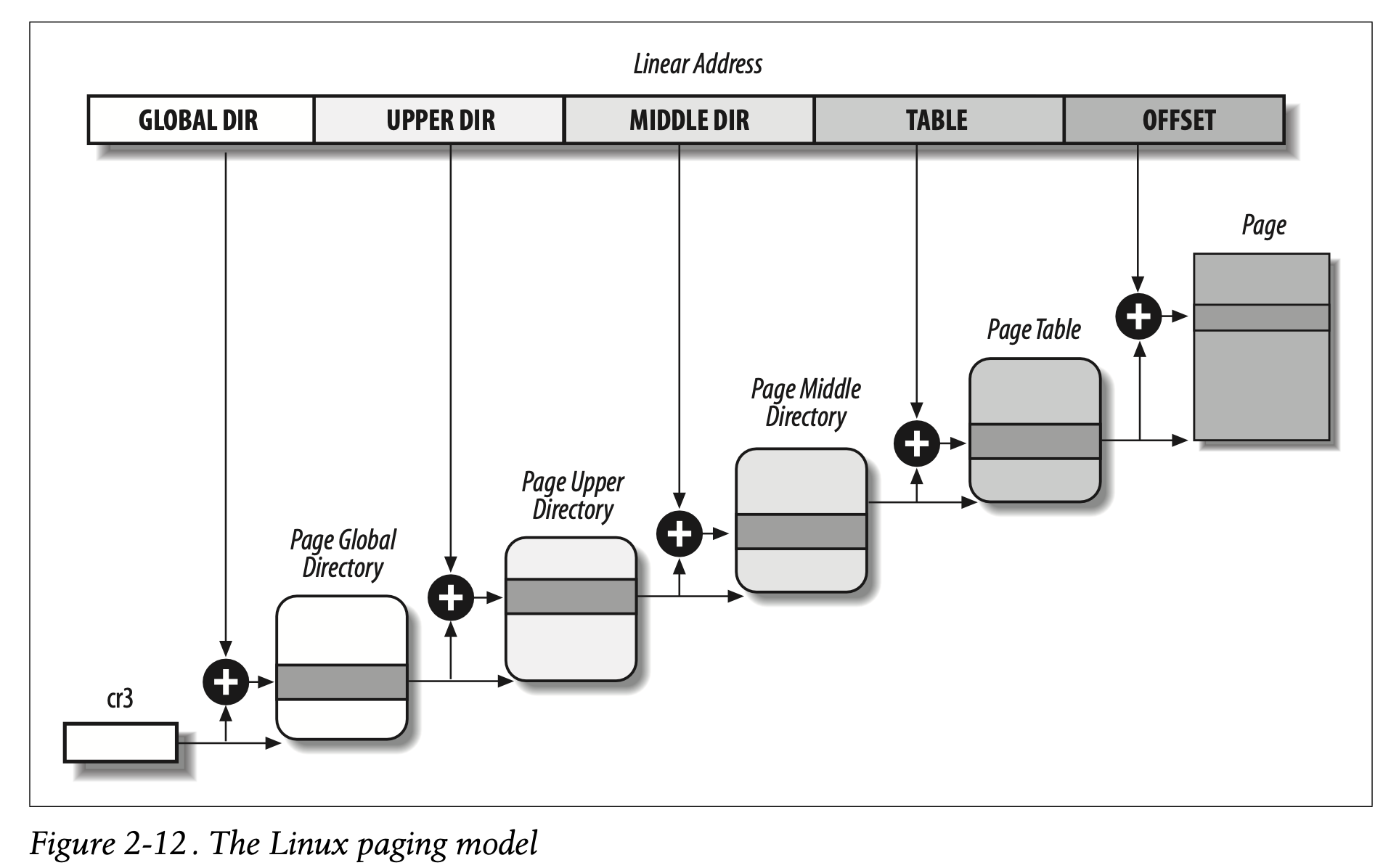
对于没有扩展到36-bit的32-bit架构,二级分页已经足够了,因此,Linux通过将Page Upper Directory和Page Middle Directory设置成0来消除这些表。然而,Page Upper Directory和Page Middle Directory的位置(指针序列中)被保留,这样能让相同的代码能够同时工作在32-bit和64-bit的架构上。内核通过将Page Upper Directory和Page Middle Directory的长度设置为1来保留这两个表的位置,并且,确保相应的条目指向正确。
对于使用了物理地址扩展的32-bit架构。。。。。略
最后,对于64-bit架构而言,使用三级还是四级分页,取决于硬件(Paging Unit),取决于系统架构。
Linux处理进程主要依赖于分页,事实上,线性地址到物理地址的自动翻译使用了下述的设计目标:
- 为每个进程分配不同的物理地址空间,确保足够的保护来防止地址错误
- 对pages(一组数据)和page frames(主存中的物理地址)进行区分。这允许相同的page被存在page frame中,然后被存储在磁盘上,或者从page frame中重新加载。这是虚拟地址机制的基本组成成分。
略,这一节有大量的宏和函数,先略过。。。
ch3 进程
进程是多任务操作系统中的一个基础的 概念。一个进程通常被这样定义:一个正在执行中程序的实例。在Linux源码中,进程通常也被称为任务或者线程。
进程、轻量化进程、线程
process这个词有众多不同的意思,在本文中,进程按照通常操作系统书籍中的定义:一个process是正在运行程序的实例。读者可能认为进程是一堆数据结构的集合,这些数据结构用来描述程序执行的进度。
进程像人类一样,可以创造进程,进程有着重要的或者不重要的生活,进程也可以产生一个或者多个子进程,一个不同点是进程没有性别,每个进程只有一个双亲(父进程)
在内核看来,进程的目的就是扮演一个可以分配系统资源(CPU时间,内存等)的实体。
当进程被创建完毕,他和他的父进程几乎没什么区别。子进程接受父进程地址空间的一个拷贝,执行相同的代码,从进程创建的系统调用开始,开始下一条指令的执行。尽管子进程和父进程有着相同的程序代码空间,他们的数据空间是分离的(stack & heap),所以子进程对内存的改变操作对父进程而言是不可见的。
早期的unix内核采用的是简单的模型,现代的unix内核则不是。现代的unix系统支持多线程应用,用户程序可以有许多相关而又独立的程序执行流,共享着同一片程序数据结构(线程)。在这个模型中,一个进程是由多个用户线程组成的,每一个线程代表着进程一部分的执行流,如今,大多数多线程应用是使用库函数中的标准集编写的,也被称为pthread (POSIX thread) libraries.
旧版本的Linux内核并不支持多线程应用,在内核的角度,多线程应用仅仅只是一个普通的进程。在用户态下,多线程应用中的多个执行流被创建,执行,调度,通过满足POSIX pthread库的标准。
然而,这种多线程应用的实现并不是很让人满意。例如,假定一个象棋进程使用了两个线程,一个控制绘制棋盘,另一个负责用户输入下一步棋的移动。当地一个线程等待玩家的移动时,第二个线程应该持续运行,持续运行的时间时玩家思考下一步棋的时间。然而,如果这个象棋程序时单进程的,那么第一个线程不能简单的使用阻塞的系统调用(会阻塞整个进程)来等待用户行动,不然,第二个线程也会被阻塞。取而代之的是,第一个进程应该采用复杂的非阻塞技术来确保进程持续在运行,而不是阻塞。
Linux使用轻量化的进程来为多线程应用提供更好的支持。最基本的,两个轻量化的进程能够共享一些资源,例如地址空间、打开的文件等等。当他们中的一个修改了共享资源,另一个立马可以看到改动。当然,当访问共享资源时,这两个进程必须要进行同步。
为了实现多线程程序,一个简单的方法是为每个线程分配一个轻量化的进程。通过这种方式,线程能访问相同的应用数据结构,通过共享相同的内存地址空间,相同的打开文件等等。同时,每一个线程都能够被内核调度。满足POSIX瞄准的pthread库,并使用了Linux轻量化线程的有:LinuxThreads, Native POSIX Thread Library (NPTL)...。
满足POSIX标准的多线程应用能够完美滴被支持线程组的Linux kernel所处理。在这类Linux系统中,thread group是一组基本的轻量级进程的集合,并且作为一个整体考虑,实现了一些系统调用:getpid(), kill(), _exit()。
进程描述符
为了管理进程,kernel必须要清楚地知道每一个进程正在做什么。例如,进程的优先级,进程是否上CPU运行,进程是否阻塞等待事件发生,进程的地址空间,进程被分配了哪些文件,等等。进程描述符process descriptor记录这些事情。process descriptor是一个task_struct类型的数据结构,它里面的字段包含着一个进程所有的信息。由于存储着这么多的信息,process descriptor更加复杂一点。除了大量包含进程属性的字段,process descriptor还报刊了一些指向其他数据结构的指针。
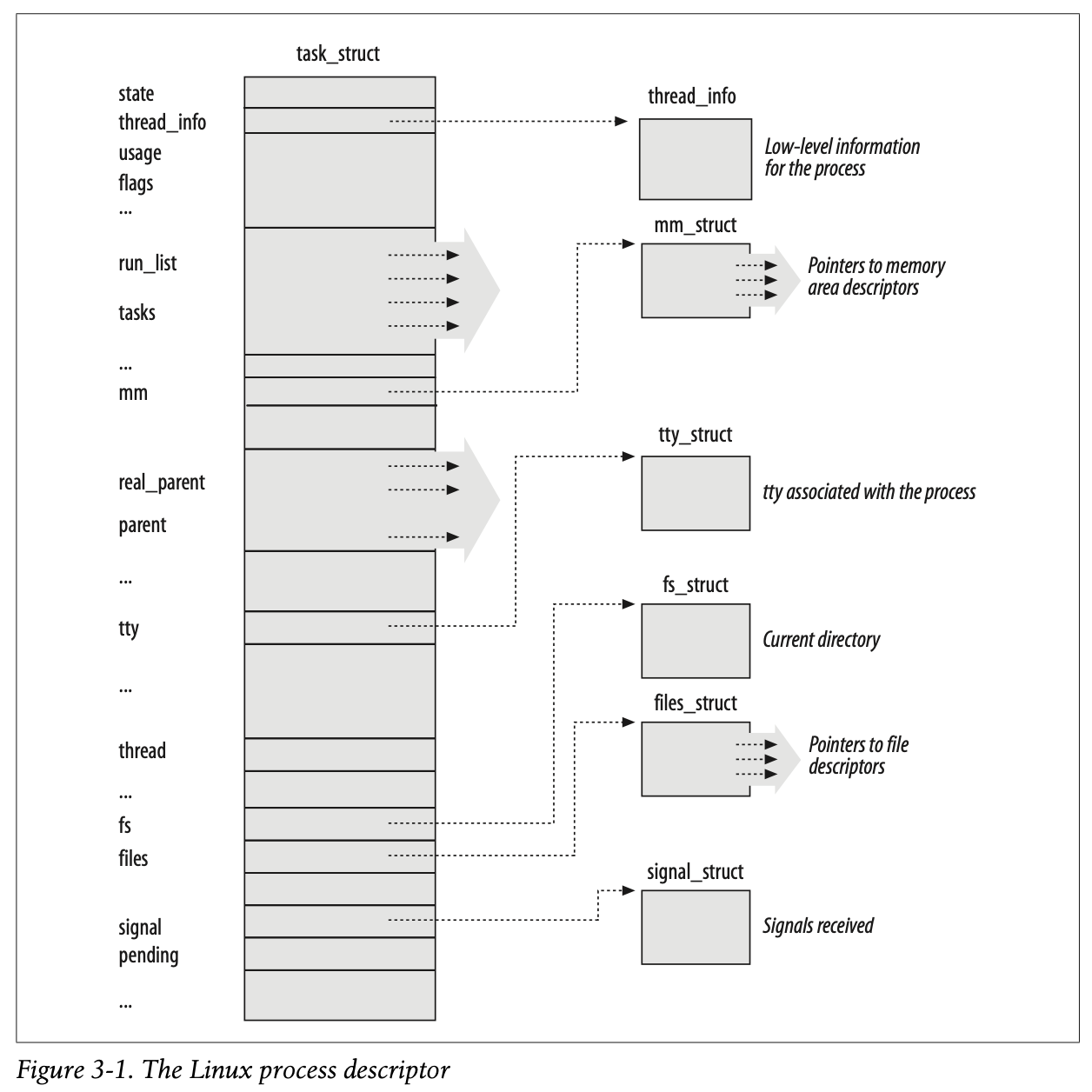
进程状态
如名字暗示的那样,process descriptor的state字段描述了当前进程的状态。它包含了一组标志组成的数组,每一个标志都是当下进程可能的状态。在当前的Linux系统中,这些状态是互斥的,因此其实只有一个状态被设置,其他的状态都是被清除的。进程的状态如下:
TASK_RUNING:进程要么正在被CPU执行,要么等待被执行。TASK_INTERRUPTIBLE:进程被阻塞了(睡眠),直到某些条件满足:唤起硬件中断、发布进程正在等待的系统资源、发布信号量TASK_UNINTERRUPTIBLE:和TASK_INTERRUPTIBLE状态相类似,除了一点:发送信号量到一个sleep的进程,不会改变他的状态。这个进程状态很少被用到。下面是用到这个状态的一个例子:一个进程打开一个驱动文件,相应的设备驱动开始探测相应的硬件设备。设备驱动不能够被打断,直到探测结束,或者是硬件设备以一种不可预测的状态结束。TASK_STOPPED:进程的执行被停止了;通过接收到以下信号SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU,进程进入停止状态。TASK_TRACED:进程的执行被debugger停止了。当进程被其他进程监控时(例如debugger通过系统调用ptrace()来监测测试程序)
两个额外的状态,既可以被存储在process descriptor的state字段里,也可以被存储在exit_state字段里。因为这两个状态代表着进程运行的终止。
EXIT_ZOMBIE:进程的执行被终止了,但是父进程没有发布系统调用wait4() or waitpid()来返回死掉进程的信息。在发布waitxx()系统调用前,kernel不能丢弃死掉进程的process descriptor,因为父进程可能还需要这些信息。EXIT_DEAD:最终状态,进程被kernel移除了,因为父进程提交了waitxx()系统调用。
state字段可以通过简单的赋值语句进行设置:
1 | p->state = TASK_RUNNING; |
内核也可以通过这两个宏set_task_state和set_current_state来设置状态。前者设置具体进程的状态,后者设置当前正在执行进程的状态。不仅如此,使用这些micro来更改state可以防止编译器或者CPU控制单元混淆某些指令,这可能会导致一些灾难性的后果。
标识一个进程
众所周知,每个能够被kernel调度的执行上下文(进程、线程)必须有它自己的descriptor。因此,即使是轻量化进程lightweight processes,他们仍然有自己的task_struct结构,即使他们共享了很多的kernel data structures。
process和process descriptor之间一一对应的限制,使得kernel识别processes很方便,原因在于task_struct是32-bit的地址。这些地址被process descriptor pointers所存储。kernel对大部分进程的引用是通过process descriptor pointers来完成的。
另一方面,Unix-like系统允许用户通过PID来标识进程,PID被存储在process descriptor的pid字段中。PIDs在数字上是有序的。新创建进程的PID是创建者进程PID自增1得到的。当然,PID有上限。当内核发现进程PID已经达到上限时,就会环绕到最低的、unused PID。默认情况下,PID的最大值是$2^{15}-1=32,7767$(早期的unix使用16位的short来存PID,然后取最大正数,负数用来标识进程组中的所有进程)。
1 | kill(1234, SIGTERM); // 杀掉 PID 为 1234 的进程 |
用户可以向*/proc/sys/kernel/pid_max*这个文件里写一个更小的值来修改 MAX PID:
1 | (base) ➜ ~ cat /proc/sys/kernel/pid_max |
/proc是一个被挂载的特殊的文件系统(CH12中有讲到)。在64-bit系统中,root可以将MAX PID修改为4194303.
当环绕PID时,kernel必须管理pidmap_array bitmap,这个bitmap是用来标识哪些PID已经被分配了,而哪些没有分配。在32-bit系统中,由于一个page frame是32768bits,小于MAX PID,所以bitmap被存储在一个单独的page frame中。而在64-bit架构下,需要更多的page frame来存储bitmap,这些page从来不会被释放。
Linux为不同的进程或者轻量化进程分配不同的PID。这种方法具有最大的灵活性,因为任何被执行的上下文都能够被唯一地标识。
另一方面,unix程序员希望同一组threads具有相同的PID。例如,可能会有这样的场景,指定一个PID,向所有组里的threads发送信号。事实上,POSIX 1003.1c标准规定,在多线程应用中,所有的threads都需要有相同的PID。
为了遵守这个标准,Linux提出了线程组thread groups。所有threads共享一个PID标识符,这个标识符是最开始的lightweight process的,也被称为thread group leader。这个共享的PID被存储在process descriptor的tgid字段中。系统调用getpid()返回当前process的descriptor里的tgid字段,而非pid字段,因此一个group里的所有threads都是反悔的同一个pid标识符。大部分processes都是属于一个由单个member组成的group中,因此他们也作为group leader,他们的pid和tgpid是相同的,因此*getpid()*系统调用也能够正常工作。
随后,会讲解如何高效地从一个PID导出其具体的process descriptor pointer。效率很关键,因为很多系统调用,例如*kill()*使用PID来代指一个进程。
处理进程描述符
进程是一类动态实体,生命周期从ms到months。因此,内核需要有能力一次处理多个进程。并且,进程描述符被存储在DRAM而不是永久分配给kernel的RAM里。Linux打包了两个不同的数据结构在每个进程单独的内存区域内:一个很小的链接到process descriptor的数据结构,也就是thread_info结构以及内核态进程堆栈(kernel mode process stack)。这片内存区域通常大小为8192字节,也就是两个page frame。出于效率考虑,Linux kernel将这8KB的内存区域存储在两个连续的page frame里,将第一个page fram以8KB($2^{13}$)对其。然而当启用动态内存时,这可能会导致一个问题:内存可能是高度碎片化的(CH8中会讲到)。因此,在8086架构下,kernel可以在编译时间被配置,使得包含了stack和thread_info结构跨越单独的一个page frame。(maybe不连续??)
在前面,我们了解到,在内核态下的process访问的stack包含kernel data segment,这不同于用户态下的process访问的stack。因为内核控制路径很少使用堆栈,因此仅仅需要几KB的内核堆栈。因此,对于stack和thread_info而言,8KB是一份充足的空间。然而,当stack和thread_info被包含在同一个page frame中,kernel使用了一些额外的堆栈来避免因为中断或者异常嵌套过深导致的overflow。
下图展示了stack和thread_info在两个page frame中是如何组织的。thread_info处于内存开始的区域,而stack是从最高位地址开始向下增长。下图也展示了这两页和process descriptor是如何相连的。
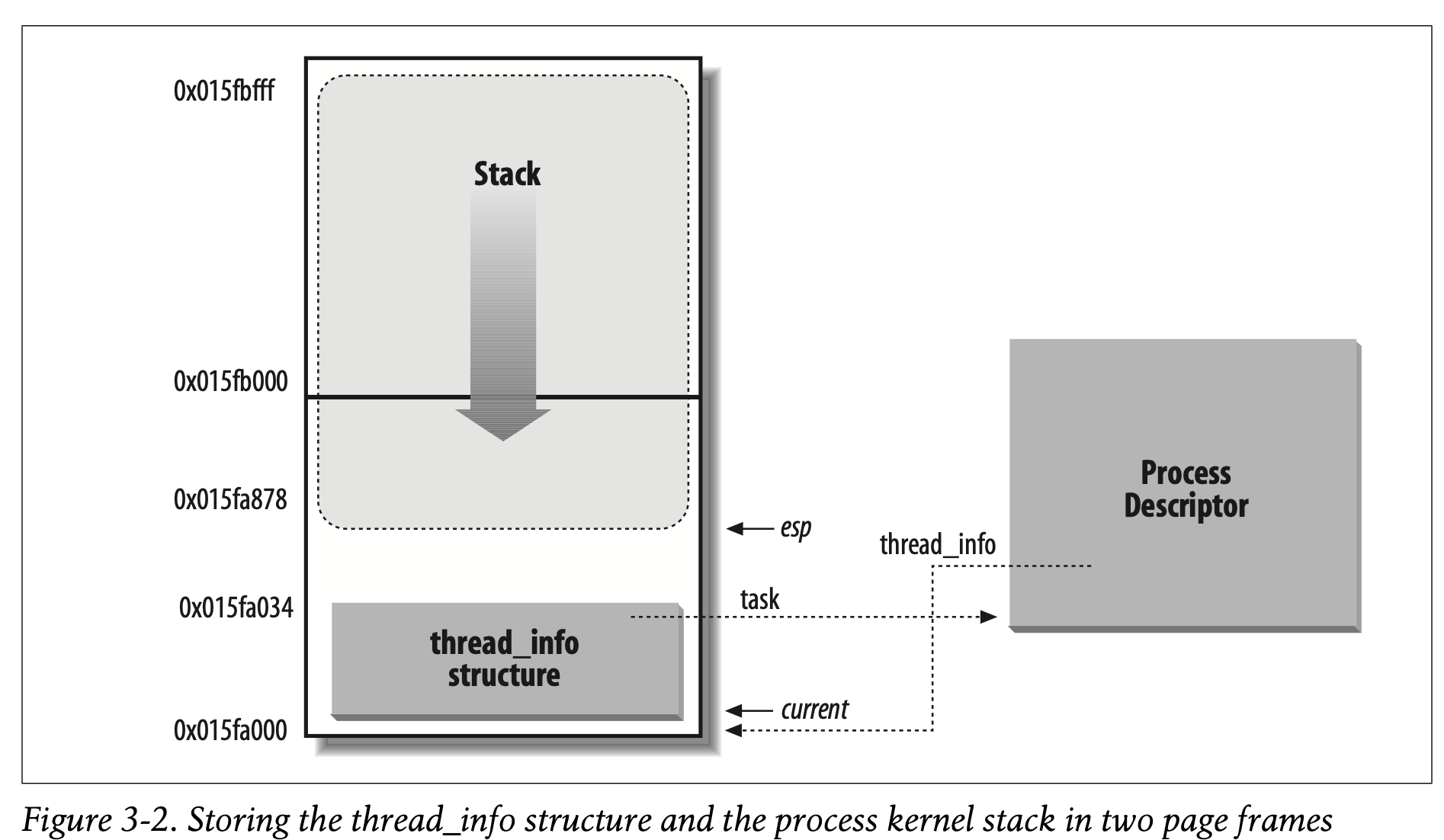
esp寄存器代表CPU的栈顶指针,用于寻址栈顶。在8086系统中,栈顶从最后开始,向下生长到内存区域最开始的地方。在进程刚刚从用户态切换到内核态时,kernel stack是空的,因此esp指向堆栈最上面的字节。
当数据被push到kernel stack中后,esp会递减,并且,由于thread_info的大小事52 bytes,因此kernel stack最多只能到8140 bytes
在C语言中,stack和thread_info能够被很方便的组织在一起,通过union数据结构:

kernel通过alloc_thread_info和free_thread_info这两个micro来分配和释放存储在thread_info和stack中的内存。
标识当前进程
thread_info和kernel mode stack的紧密联系,对效率有提升:内核可以很容易地获得当前运行进程的thread_info的地址,通过访问esp寄存器。事实上,假设thread_union的大小是8KB,kernel只需要mask低13位即可得到thread_info的基地址。另一方面,如果thread_union大小是4KB,那么只需要mask掉12位即可。这歌过程是通过*current-thread_info()*函数来完成的,通过汇编语言实现:

在执行完这三条指令后,p中就包含了当前正在CPU上运行的process的thread_info地址(指针)。
通常而言,kernel需要的是process descriptor的地址,而非thread_info的地址。为了达到这个目的,kernel利用current这个micro,和current_thread_info()->task是等价的,汇编上是这样实现:
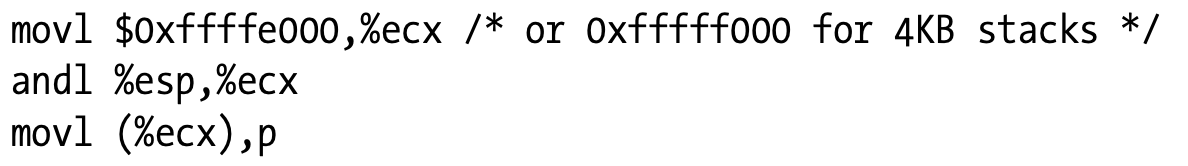
因为task字段是在thread_info的0号索引处,在执行这三条汇编之后,p中就包含了当前CPU运行进程的process descriptor的地址。
current micro经常作为字段的前缀出现在kernel code里,例如:current->pid返回的就是当前进程的PID。
另一个把thread_info和stack存放在一起的优点是,在多处理器系统中:通过上面的方法(current micro),可以直接找到不同CPU上运行的不同process。早期的Linux系统并没有这样做,取而代之的是,Linux强行引入了一个全聚德静态变量current来标识正在运行进程的process descriptor,若是在多处理器系统中,就需要定义一个全局静态数组,来标识每个进程的process descriptor。
双链表
在讨论内核如何跟踪系统中的不同进程前,县重点讨论一下双链表,这在许多特殊的数据结构里起作用。
对于每一个链表,一组原始操作需要被实现:初始化双链表、插入和删除元素、扫描列表等等。如果对于每个list,程序员都去实现这些原始操作,这是比较费时费力,浪费内存。
因此,Linux kernel定义了list_head这个数据结构,仅仅有两个字段next和prev,代表着forward pointer和back pointer,这些pointers指向的都是双链表的元素。然而,需要强调的是,list_head的字段里存着的是其他list_head的地址,而不是整个数据结构(整条链表)的地址。这里应该是为了和数组进行区分。
通过LIST_HEAD(lisy_name)这个micro来创建一个新的链表。这个micro声明了一个名为list_name类型为list_type的新变量。这是一个占位符,作为这个链表的表头占位符(里面可以不存放任何数据,只代表head),初始化两个指针next和prev,指向自身。
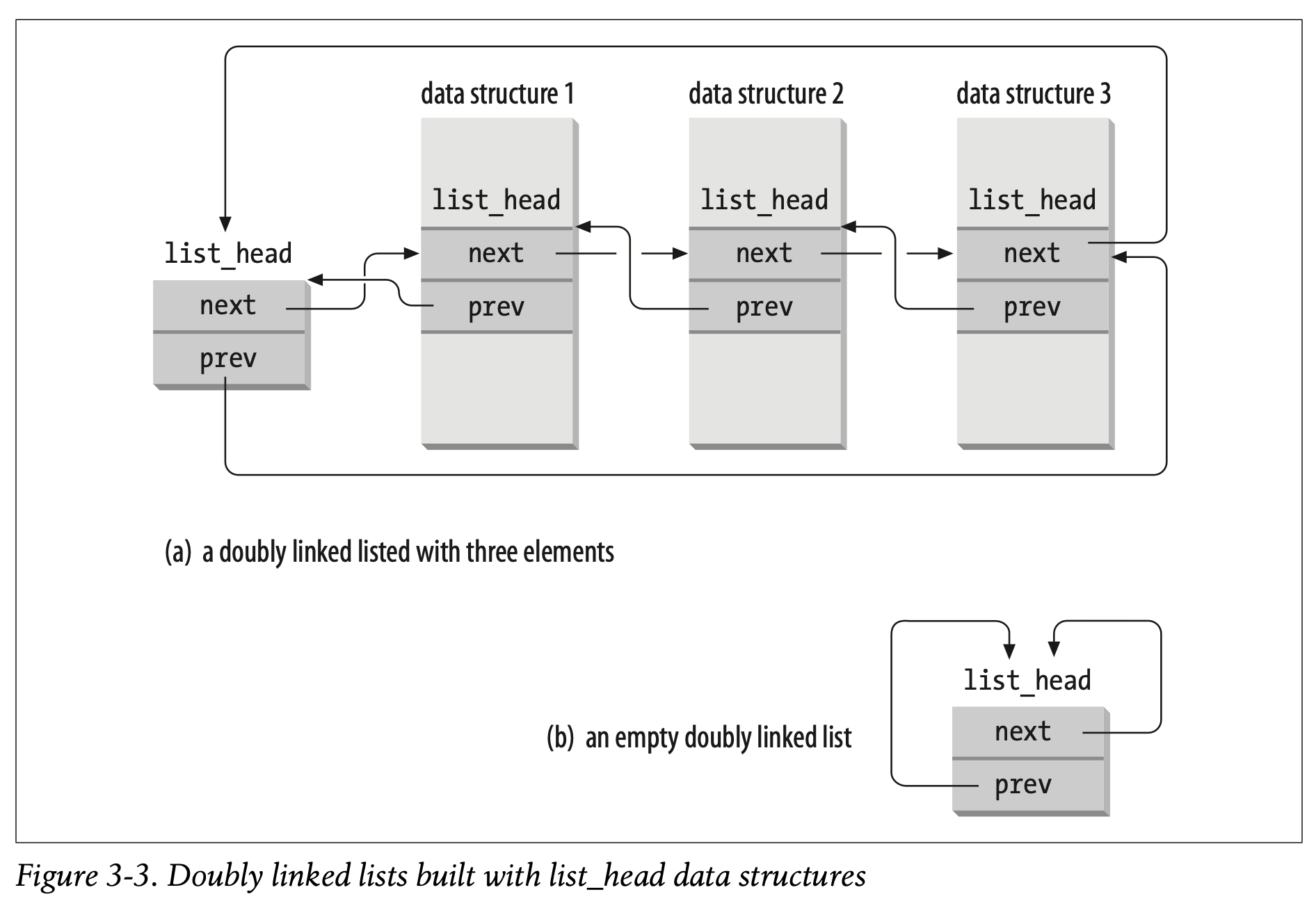
一些函数和micro已经被实现了,如下:

2.6版本的Linux kernel也支持另一种双链表,和list_head的主要区别在于list_head不是环绕的;这主要用于哈希表中(存储空间十分重要),以常数级别的时间复杂度找到最后一个元素。表头存储在hlist_head中。这个数据结构仅仅只是一个指针,指向第一个元素,若第一个元素不存在,那么指向NULL。链表中的每一个元素则是用hlist_node数据结构来表示,这个数据结构同样包含两个指针next和pprev。由于链表不是环绕的,第一个元素的pprev和最后一个元素的next都是指向NULL。这个数据结构也可以被一些micro和函数所处理,例如:

进程列表
我们要讨论的第一个双链表的例子是process list,进程列表,里面存放的是所有存在进程的process descriptor。每一个task_struct结构包含一个task字段,这个task字段的类型是list_head,其next和prev指向的是下一个或者前一个task_struct。
进程列表的表头是init_task的task_struct描述符。这是0号进程的process descriptor(process 0也被称为swapper)。init_task的task->prev指向的是最后一个process descriptor。
SET_LINKS和REMOVE_LINKS这两个micro被用作插入或者移除process descriptor。这些micro也会关心进程的父子关系。
另一个比较有用的micro是for_each_process,用来扫描进程列表:

这个micro是一个循环,由内核程序员提供。需要重点关注init_task进程描述符作为表头的作用。这个micro从init_task开始,当再次访问到init_task结束,从这里可以看出,循环列表的环绕效果起了作用。在每一轮迭代,micro作为参数传递的变量包含当前process descriptor的地址,通过*list_entry()*提供。
TASK_RUNNING进程列表
当kernel寻找新的进程上CPU运行时,内核只能考虑可运行的进程,也就是状态为TASK_RUNNING的。
早期的Linux版本中,将所有可运行的进程放到一个名为runqueue的列表里。因为保持这个列表有序(按照进程优先级)十分费时间,早起的schedulers被强迫去扫描整个list,以便找到最优的runnable process。
Linux 2.6以不同的形式实现了runqueue,目的是让scheduler以常数时间来选择最优的runnable process。关于runqueue,在CH7中会有更详细的讲述,这里只提供基本信息。
(核心思想和UCOSiii里的TCB很类似)加速调度器的技巧是将runqueue拆分为很多list,每个list一个优先级。每个task_struct descriptor包含一个run_list字段,类型为list_head。如果进程的优先级是k(在0到139之间),run_list字段连接process descriptor到第k个runnable processes list里。此外,在多处理器系统中,每个CPU有其单独的runqueue。这是一个很经典的例子,让数据结构更加复杂来换取性能:为了让scheduler操作更加高效,runqueue被拆分成140个不同的列表。
如我们所见,kernel需要为每一个runqueue都维持大量的数据。然而,runqueue的包含的主要数据结构是process descriptors的list,这些lists是通过prio_array_t数据结构实现的,字段描述如下:

将一个process descriptor插入到runqueue list的代码如下:

进程之间的关系
进程之间有父子关系。当一个进程创建很多歌子进程时,这些子进程互为sibling(兄弟姐妹关系)。为了代表这些关系,process descriptor中引入了一些字段,如下表所示。另外,Process 0和Process 1是kernel创建,process 1是init进程,是所有其他进程的祖先。至于process 0,是idle进程(**swapper**进程,闲逛进程)。

下图阐述了一组进程的父子关系,以及亲戚关系,P0创建P1-P3,然后P3创建P4.
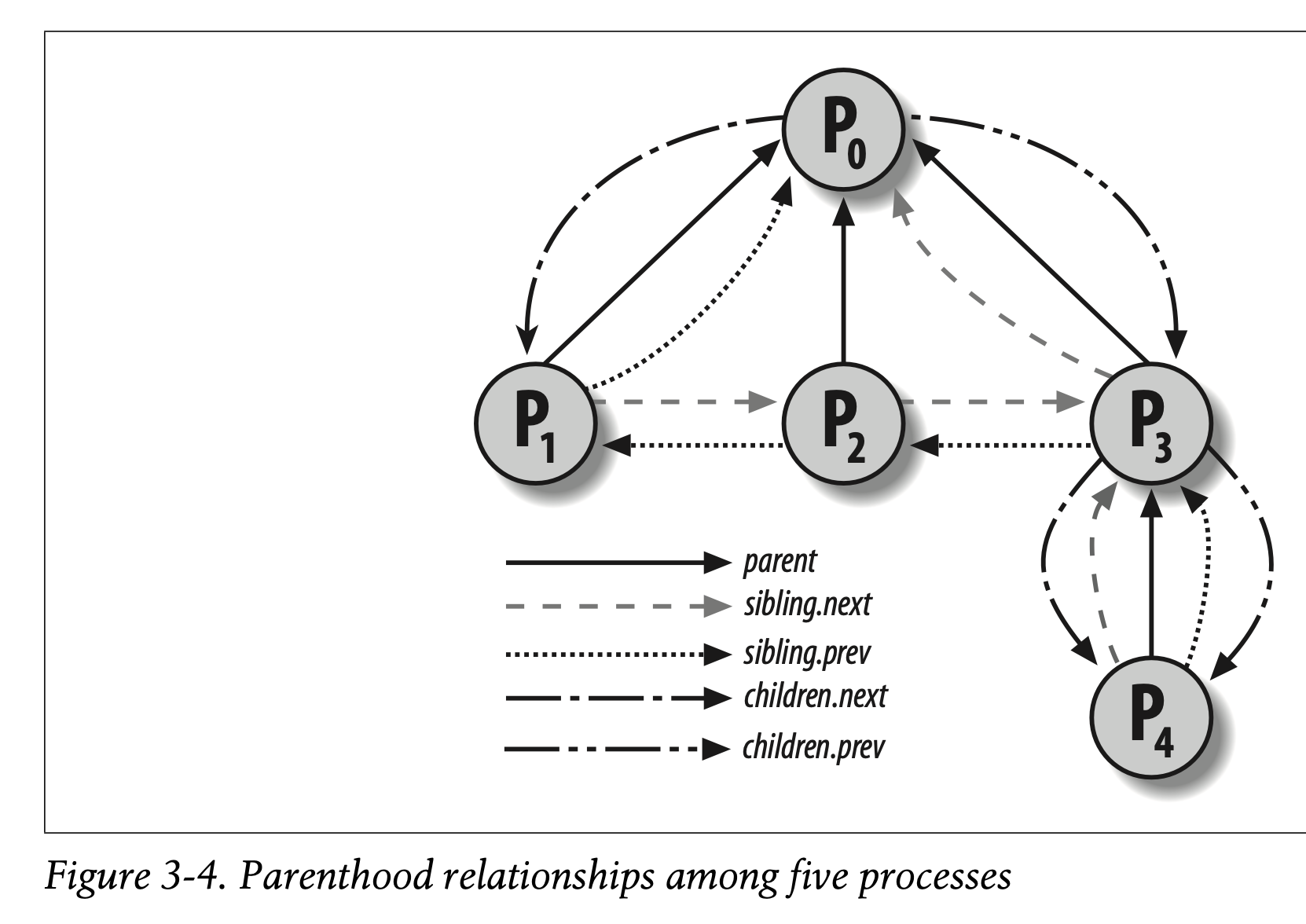
此外,进程之间也有其他的关系:进程可以是进程组的leader,或者是login session的leader,线程组的leader,追踪其他线程的执行。下表是descriptor中的一些字段,用来衡量进程P和其他进程之间的关系:

pidhash table & chained lists
在很多情况下,kernel需要啊根据PID来导出相应的process descriptor。例如,使用kill系统调用时,当进程P1希望发消息给进程P2时(杀死P2),P1调用kill系统调用,指定P2的PID。kernel根据PID导出对应的process descriptor,然后提取出记录pending signal的数据结构的指针,将signal加入进去。
直接扫process list来检查descriptor中的PID是否符合,效率不高。为了加速搜索,kernel引入了四个hash tables。使用四个哈希表的原因是,descriptor中有四种不同的PID,根据需求的不同,使用不同的哈希表来查process在process list中的索引。
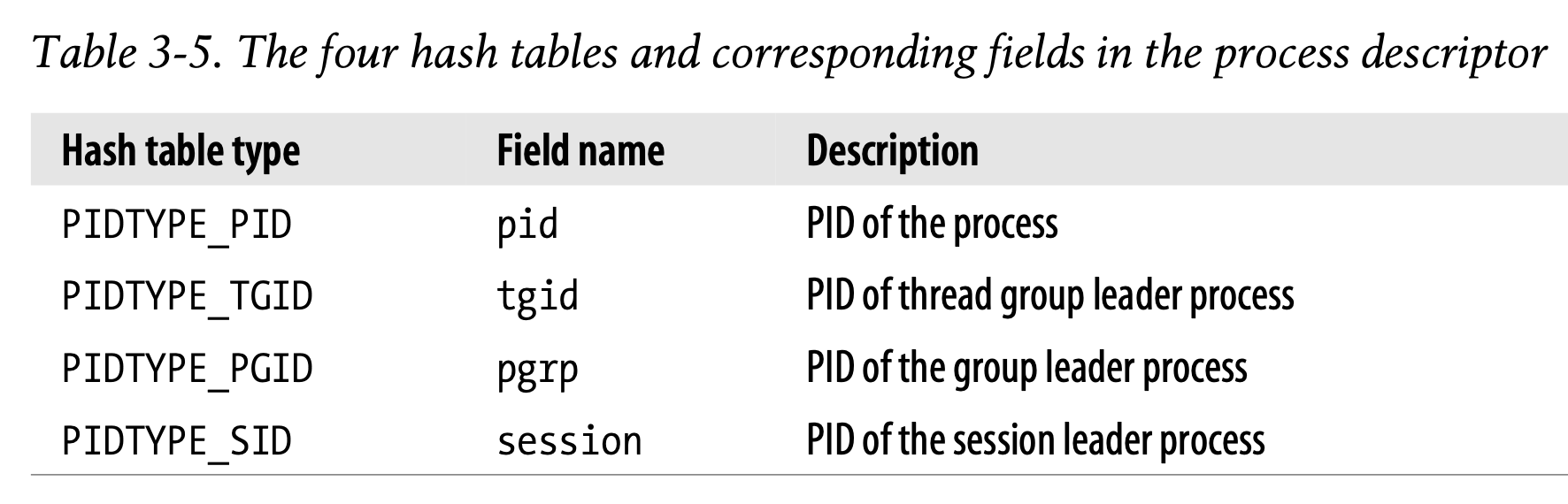
在kernel初始化阶段,四个哈希表动态分配内存,地址存储在ppid_hash中。单个哈希表的大小取决于可用的RAM。例如,对于RAM为512MB的系统,每个哈希表存储在4个page frame里,包含2048条目。
哈希表的映射实现大概如下:

由于哈希表有时并不一定是一一对应,会出现不同的PID映射到同一个哈希值上,称为哈希冲突colliding。Linux使用链表chaining来解决哈希冲突。
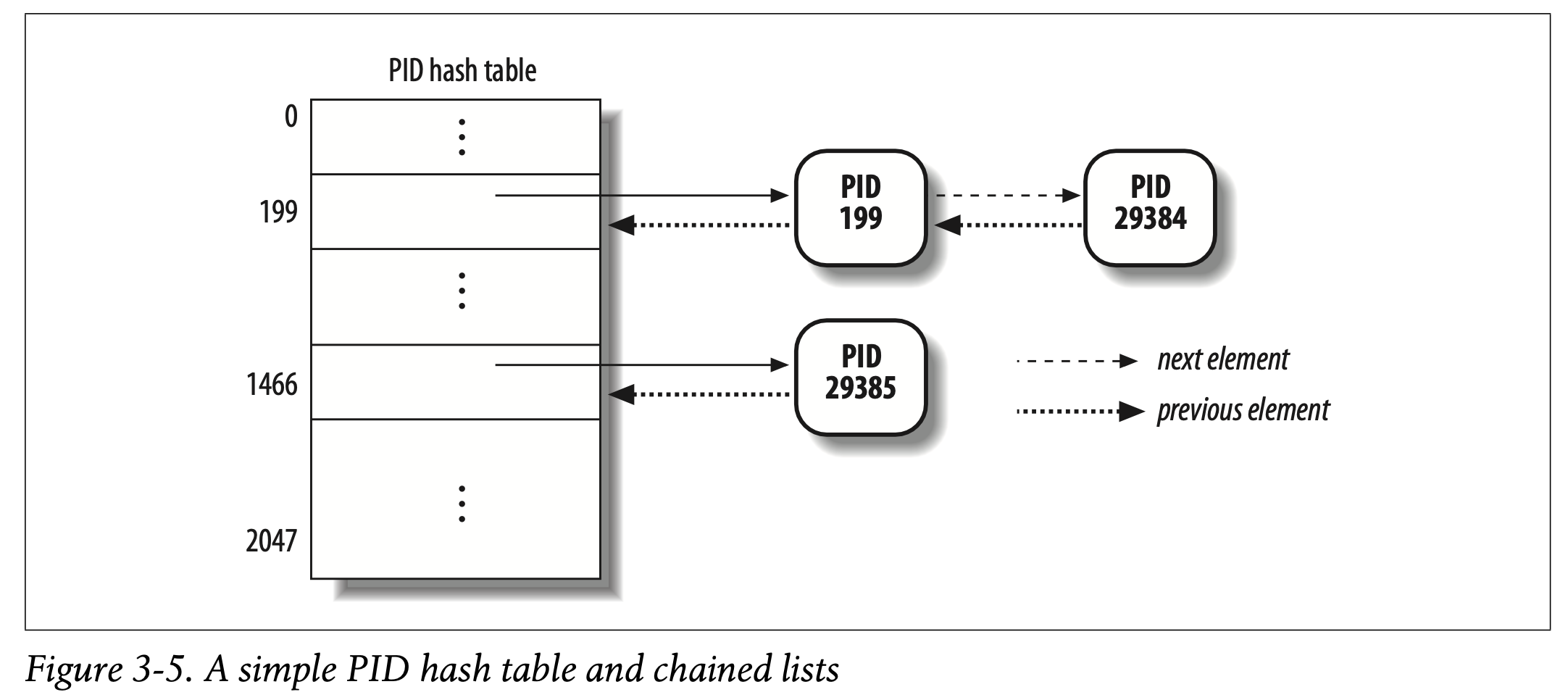
通过hash,以chaining的形式来将PID映射到process list index是极好的。系统中的进程数目通常是小于32768的,因此如果定义一个包含32768条目的table是非常占用空间的,并且大多都没使用到。
PID hash table中的数据结构十分复杂,因为需要追踪进程之间的关系。例如,kernel需要知道所有属于某一个thread group的进程。查询哈希表只会返回一个descriptor,也就是leader的descriptor。为了快速得到thread group里的其他进程,kernel会为每一个thread group维护一个list。同理,找到所有属于同一个login session的进程,找到一个process group里的所有进程,都是类似的思路。
PID hash table的数据结构解决了这些问题,因为该数据结构包含一个字段pid_list,存放进程列表。

