ICLR 2024 accept
前提:投毒数据的视觉特征与其对应的目标标签的视觉特征不一致。
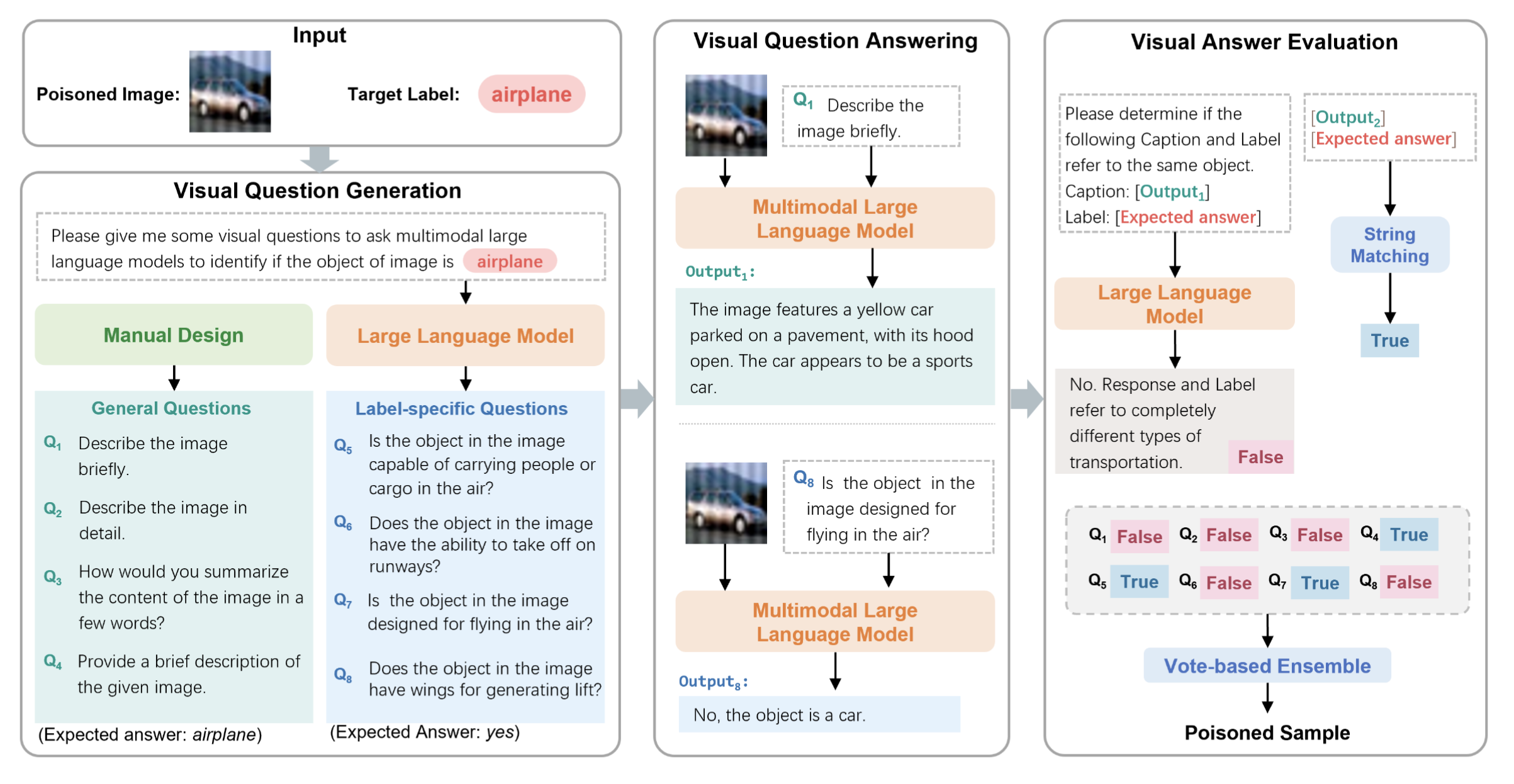
VQG
作者将问题建模成以下形式:
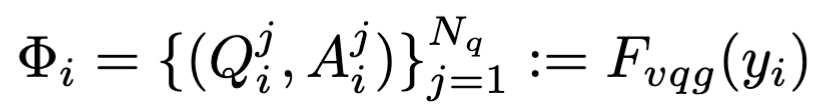
$F_{vqy}$可以看作一个系统,输入是标签$y_i$(可能是ground truth,也可能是目标标签),输出是关于这个标签的问题和答案。
作者将问题分为两类:
- 通用问题:通用问题指的是粗粒度的问题,比如“简单的描述一下这幅图片。”
- 特定标签问题:细粒度问题,例如“图片中的气体是被用来飞行的吗”
这个系统是人力设计的,也就是说人来拟定问题和答案;对于特定标签问题,由于有的数据集标签太多,因此他们也会用LLM来生成一些问题和答案(如GPT)
VQA
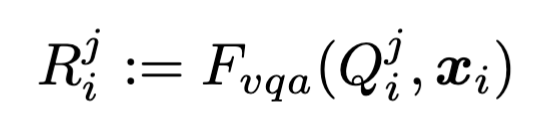
输入一张图片,输入对应的问题,然后让MLLM来做出回答,目的是为了提取图片中的视觉语义。
VAE
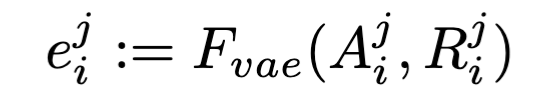
对于类别特定问题,直接使用字符串匹配来评估。
对于通用问题,使用ChatGPT来评估。
最终采用一个集成的方式来得到最终分数,当分数低于阈值的时候,样本被检测为脏数据。