
AAAI 2024
还没有release code
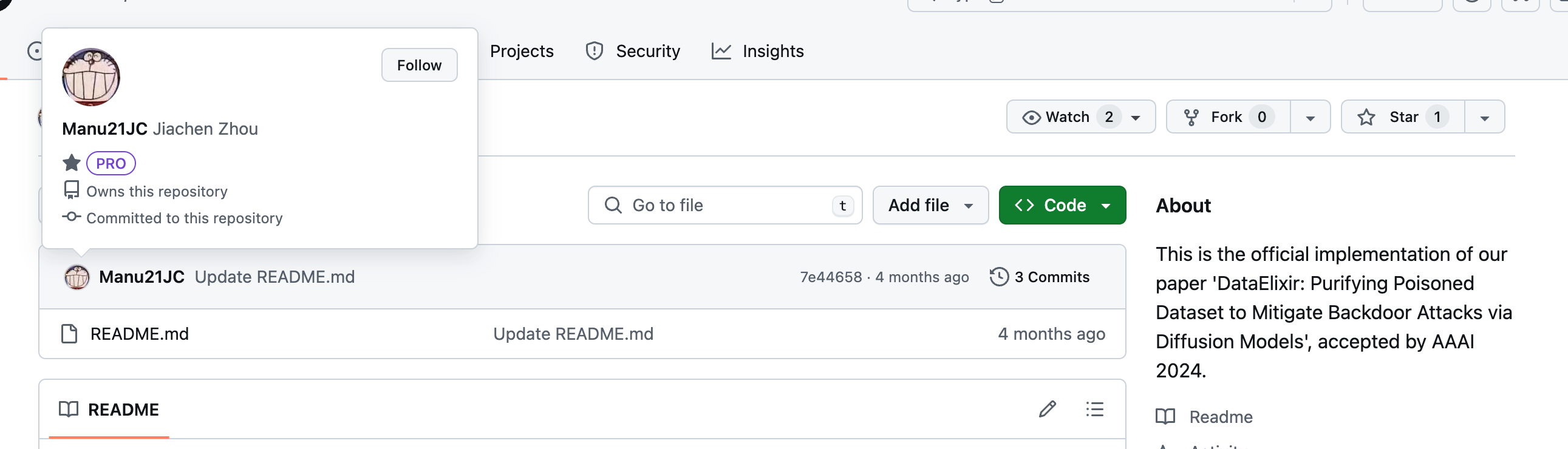
本文提出了一种数据消毒方法,也是使用扩散模型来消除触发器特征,重构良性特征。
方法
威胁模型
本文处于防御者的视角,对于攻击者的目标标签、投毒率等不可访问。
防御者:
- 假设防御者可以访问和当前任务类似分布的预训练扩散模型。
- 训练扩散模型的数据集是干净的
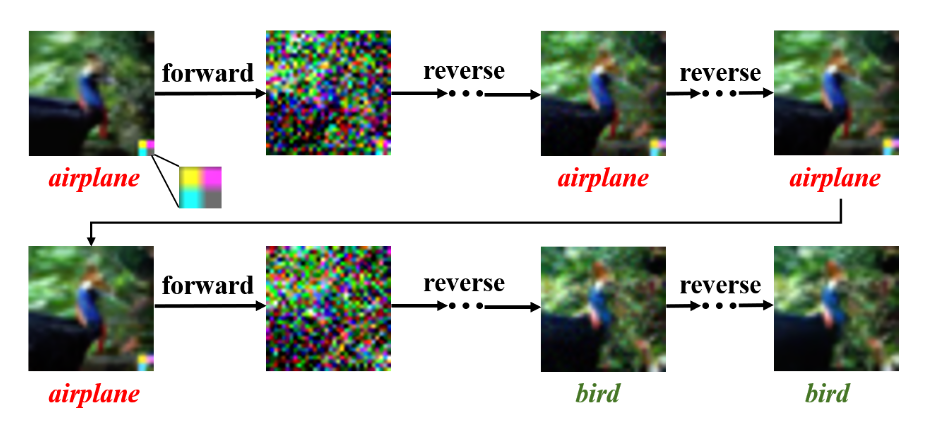
候选集合构建
 、
、
本文采取的方法是,对于某张图片,进行n轮前向&反向过程,每一轮的最后m次反向,收集重构的图片,作为候选集合,若是候选集合中的标签发生了变化,证明图片很可能被投毒。
$$
C_{(x_i,y_i)}={(x_j,y_j)}^{n\times m}_{j=1}
$$
异常样本识别
对于每一个候选集合,都有一个转换系数$\eta$,表示第二高的标签的计数,若是超过了阈值$\tau$,那么代表这个样本可能是毒化样本。
进一步,对于一个良性的样本,其候选集合的分布应该是单值的,也就是全部是一个标签;对于异常样本,则是双值,分布上表现为两个波峰,这代表着样本标签从目标标签到正常标签的转换(触发器特征被逐步模糊)。
更具体的,作者将整个数据集划分为三部分:良性、毒化、可疑
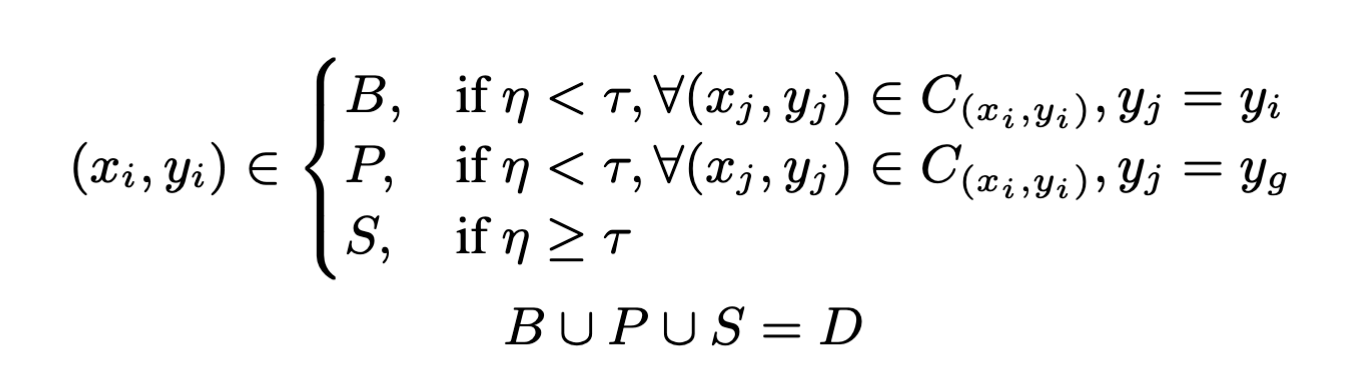
- 若是在整个扩散模型的评估过程中,数据的标签都没发生偏移,代表样本是良性的,归类为$B$;
- 若是数据的标签发生偏移,从目标标签转移为真实标签$y_g$,代表这是毒化数据,归类为$P$,选取经过扩散模型净化后的样本,加入到清洗后的数据集中。
- 造成第三种情况的有两种可能性:
- 在后期迭代之前,可能无法有效地消除中毒图像上的触发特征,导致标签表现出从目标标签到真实标签的转换时已经在迭代的末期。
- 样本上的良性标签特征在通过扩散模型时被摧毁了。
目标标签检测
直觉:在$P\cup S$中,标签为目标标签的样本和标签正常的样本之间的分布是有差异的。
构造一个集合:
$$
C_y=\bigcup_{(x_i,y_i)\in P\cup S}{C_{(x_i,y_i)}|y_i=y}
$$
这样后,将集合分为几个小集合,另外一个直觉:含有目标标签的集合的分布比正常的分布混乱的多。
因此,计算这几个分布的KL散度,和正常样本集合对应标签的分布之间的差别,就能判断出$y_t$了。
净化数据集
对于$B$中的数据,都是良性数据,可以直接加入净化数据集;
对于$P$中的数据,若是其标签为目标标签,修改其标签为正常标签后,即可加入到正常数据集;
对于$C_y$的其余部分,若是经过扩散模型前后的输入输出图片有显著不同,考虑这种情况:扩散模型将触发器移除掉了,而不是毁掉了良性特征,通过下面的式子判断二者之间的距离:
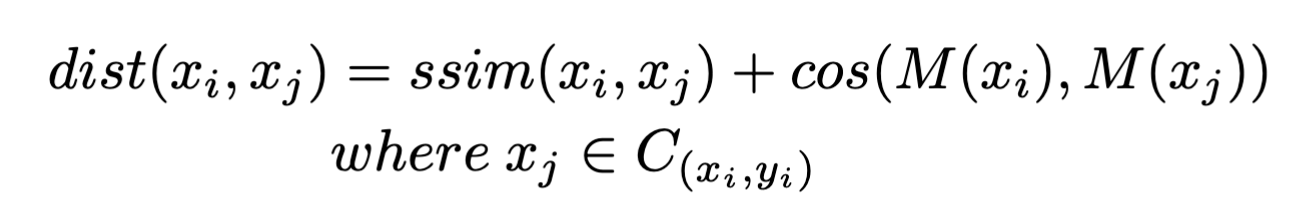
$M$选取的是受害者模型,计算出这个距离后,选取前80%,作为良性数据。
对于在$S$中具有目标标签的样本,本文选择使用干净的数据集($B$,纠正了标签的$P$,通过距离判断的$P\cup S$),训练出干净模型$M^{‘}$,来判断剩下的样本的正确标签。
由于$M^{‘}$训练时没有学习触发器的特征,所以能够通过样本中的原始标签特征来做判断,而不是触发器特征。
