
ICLR2023
从输入到模型的图片中提取出“最小模式”,通过实验发现后门模型有一种认知模式(cognitive pattern),作者通过提取出来的最小模式,来对模型进行认知蒸馏(cognitive distillation)。
认知蒸馏和后门样本检测
认知蒸馏
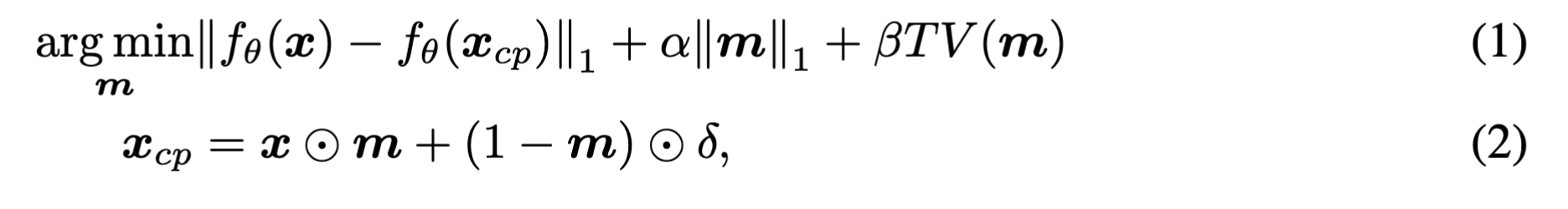
- $x_{cp}$:蒸馏掉的认知模式
- $m$:可学习的掩码,$[0,1]^{w\times h}$
- $\delta$:噪声,$[0,1]^c$
- $TV(.)$:总变化损失(?)
- $f_\theta (.)$:可以是最后一个全连接层的输出,也可以是最后一个卷积层的输出
公式1的目的是确保认知蒸馏后的输入$x_{cp}$和原始输入$x$输入到模型后,得到的输出基本是一样的。
公式2的目的是去除原始输入中不那么重要的特征。
掩码中1代表对应的像素很重要,0代表不重要。
提取掩码和认知模式有利于理解模型误分类的原因。认知模式中的某些像素很可能是增加了扰动的(因为模型中可能有后门)。
通过认知蒸馏来理解后门模型

- 第一行:干净图片和触发器样本的混合
- 第二行:通过上一节的公式,优化出来的掩码$m$
- 第三行:对原始图像进行蒸馏过得到的认知模式,也就是$x_{xp}$
- 第四行:简化后的后门图像
然后作者使用第四行和第一行(原始图片)来测试ASR,选取的baseline有badnet、blend等
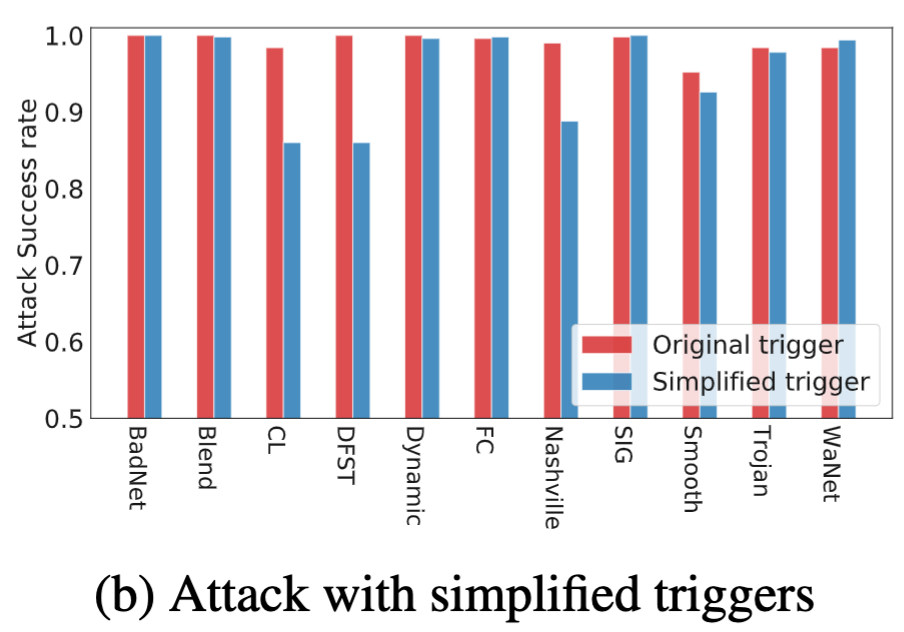
- 原始触发器:$x_{bd}$
- 简化后的触发器:$x_{bd}^{‘}=m\odot x_{bd}+(1-m)\odot x$
结论:无论触发器模式如何,后门模式的相关性比自然物体的相关性要简单得多。
后门样本检测
后门样本检测属于一种无监督的分类任务,因为没有先验知识,所以只能根据样本本身的特征信息来进行监督、聚类。
计算样本掩码的L1距离$\Vert m\Vert _1$,来判断输入进来的是否是后门样本:
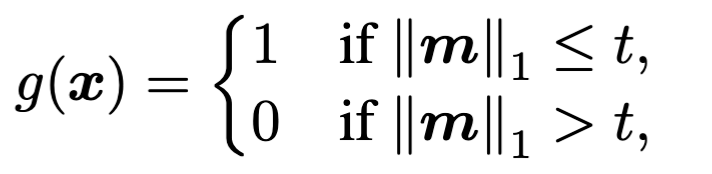
若是$g(.)=1$,则代表是后门样本,反之则不是。
对于测试期间,假设防御者受伤有一部分干净样本,那么可以计算出这些样本的分布:$\mu_{\Vert m\Vert 1},\sigma{\Vert m\Vert _1}$,然后可以这样得到阈值t:
$$
t=\mu _{\Vert m\Vert 1}-\gamma \sigma{\Vert m \Vert _ 1}
$$
$\gamma$是超参数,用来对控制阈值。
