
NIPS2023
摘要
本文的方法是基于微调的(FT, Fine-Tuning),微调并不能很好的解决触发器特征和样本特征联系紧密的问题,因此作者提出FST(Feature Shift Tuning)
微调提升模型的鲁棒性
实验观测
作者工作的重心在:当数据投毒率比较高(20%,10%等)时,可以使用微调来改变模型的决策边界(削弱触发器和目标标签之间的联系)。当数据投毒率比较低时,简单使用微调就无法解决问题了。这是经过实验观测得出的结论。
探索
作者对不同投毒率下微调方法效果出现不稳定这个问题进行了探索。
假设:在不同投毒率下,模型的特征提取器提取出的特征是不同的。
基于假设,开始做实验,利用T-SNE对不同投毒率下的模型提取的特征进行可视化。

实验1-特征转移能否提高微调性能
对于一个深度学习模型,将其特征提取部分的参数表示为$\Phi (\theta, x)$,将最后的线性层表示为$f(\omega)$。
作者通过固定好$f(\omega)$,将特征提取的参数进行微调,试图达到特征转移的效果。但是实验并没有达到期望的结果。固定的线性层仍然限制了模型进行特征转移。
因此,作者参考前人的工作,对线性层的参数$f(\omega ^{ori})$进行随机初始化,得到$f(\omega)$,然后再对特征提取的参数$\Phi(\theta)$进行微调。
架构:
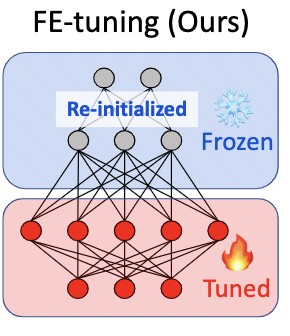
效果:
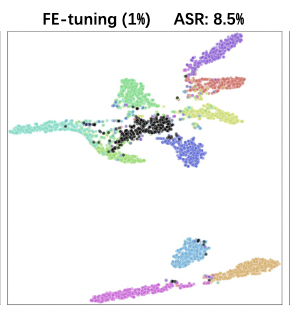
实验1-评估
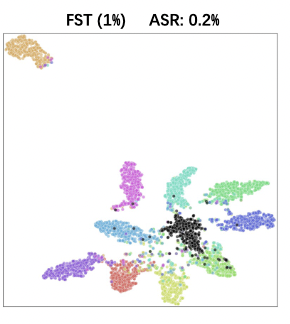
上图中的第五张是实验的结果,可以看出,采取上述设置,可以将目标标签和毒化样本的特征进行分开,在投毒率1%的情况下,但是这又导致了另一个问题,在干净样本上的正确率下降达到了2.9%,这是随机初始化$f(\omega)$导致的。
总结来看,现在有的问题是,干净样本的正确率下降&模型的鲁棒性不够(后门偏移不够)。
FST, Feature Shift Tuning
基于上面的实验观测分析,作者提出了FST,首先对线性层进行初始化,然后解决下面的优化问题:
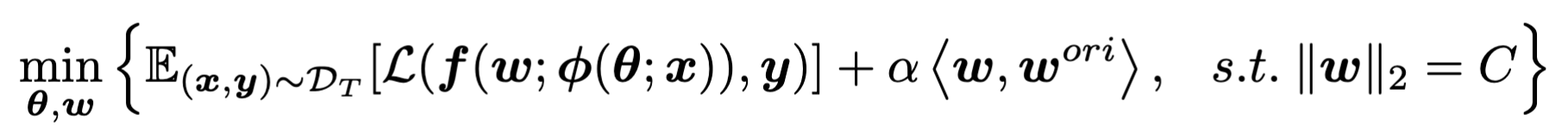
左边的式子是对模型整体的准确率来作优化,而右边$<\omega, \omega^{org}>$则是在做特征转移(基于前面的观测,这里在初始化$\omega$后加以约束,进行优化),$\alpha$作为平衡因子,在“保证正确率不下降”和“特征转移”之间作平衡,增大$\alpha$有利于特征转移。最后的$\Vert \omega\Vert_2$将线性层参数约束在一个常数范围内,确保不会出现参数过大或者过小的极端情况。
架构:
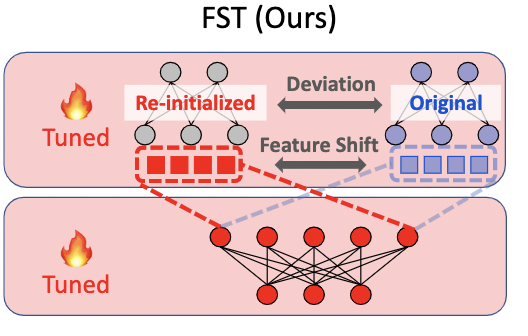
效果:
实验
训练后门模型
选择使用的模型也是ResNet18,在配置文件cifar10.yaml中可以更改。其中选取的baseline有:badnet、blended、trojannn等。
攻击的实现:
- 首先创建一个正常类
NormalCase,在prototype.py中,其他的attack class都继承了这个类。prototype.py定义了参数的解析、数据的准备以及训练过程的实现等。 badnet继承prototype,包含了一些额外的参数、参数解析,还有训练数据准备、bad训练数据准备等。- 选取好配置文件之后,训练好模型后,模型以及一些其他数据会被保存在
attack_result.pt中,可以通过torch.load来查看保存的数据,访问训练好的模型。
模型漂白
下面进行模型漂白:
1 | python -W ignore fine_tune/ft.py --attack blended --split_ratio 0.02 --pratio 0.1 --device cuda:0 --lr 0.01 --attack_target 0 --model resnet18 --dataset cifar10 --epochs 10 --initlr 0.1 --ft_mode fst --alpha 0.1 |
漂白结果:
1 | 2024-04-02:02:45:25 [INFO ] [ft.py:360] Training ACC: 0.9970000386238098 | Training loss: -283.08803248405457 |
