
RAID, CCFB,常见的defence
摘要
提供了第一个有效的后门攻击防御方法,实验:
- 三个后门攻击
- 两种防御方法,剪枝和微调,并且进行结合,提出了fine- pruning,微剪枝。
实验结果:在某种情况下,降低攻击成功率到0%,仅仅只有0.4%的正确率下降(对于那些干净样本)
本文结构:
- ch1介绍
- ch2背景,分为三节介绍:深度学习基础、
威胁模型、后门攻击 - ch3是讲方法的
ch4是讨论,讨论了对方法的正确性进行了讨论ch5近期工作- ch6结论
结构比较乱,没有单独的实验部分。
威胁模型和之前的论文一样。
方法
剪枝
原理
某些后门攻击选取的神经元具有这样的特性:对于干净样本的输出,不激活;对于带有后门的输入,激活较大。因此,直觉上,将这样的神经元修剪掉,可能会使后门攻击无效。
剪枝详细分为三个阶段:
对干净数据和后门输入都不激活的神经元,剪掉。
这类神经元剪掉不会有任何影响。
只对后门输入激活的神经元,剪掉。
在不怎么降低正确样本准确率的前提下,修剪掉这类神经元。
对干净输入激活,同时会降低正干净样本的正确率的神经元,剪掉。
将受到后门神经元影响比较严重的神经元修剪掉。
剪枝是一种不错的策略:
- 计算量低,只需要在验证集上训练剪枝即可。
- 能够显著降低后门攻击的成功率。
缺点:已经有针对修剪的攻击了。
实验
剪枝前人已经提出过了,作者此部分的工作量:
- attack baseline:badnets
- 攻击场景:人脸识别、语音识别、交通信号
在分析的时候作者会将接近输出层的神经元的输出可视化出来,不是很懂这种图的意思:

1 | # 在(a)“Clean Activations”图表中,每一块代表一个特定神经元的激活强度,颜色越浅表示激活强度越高。0~2.0是一个比例尺,表示激活强度的范围。在(b)“Backdoor Activations”图表中,大部分神经元没有被激活(黑色),只有少数几个显示出较高的激活(白色)。0~25也是一个比例尺,但具有不同的范围和刻度。 |
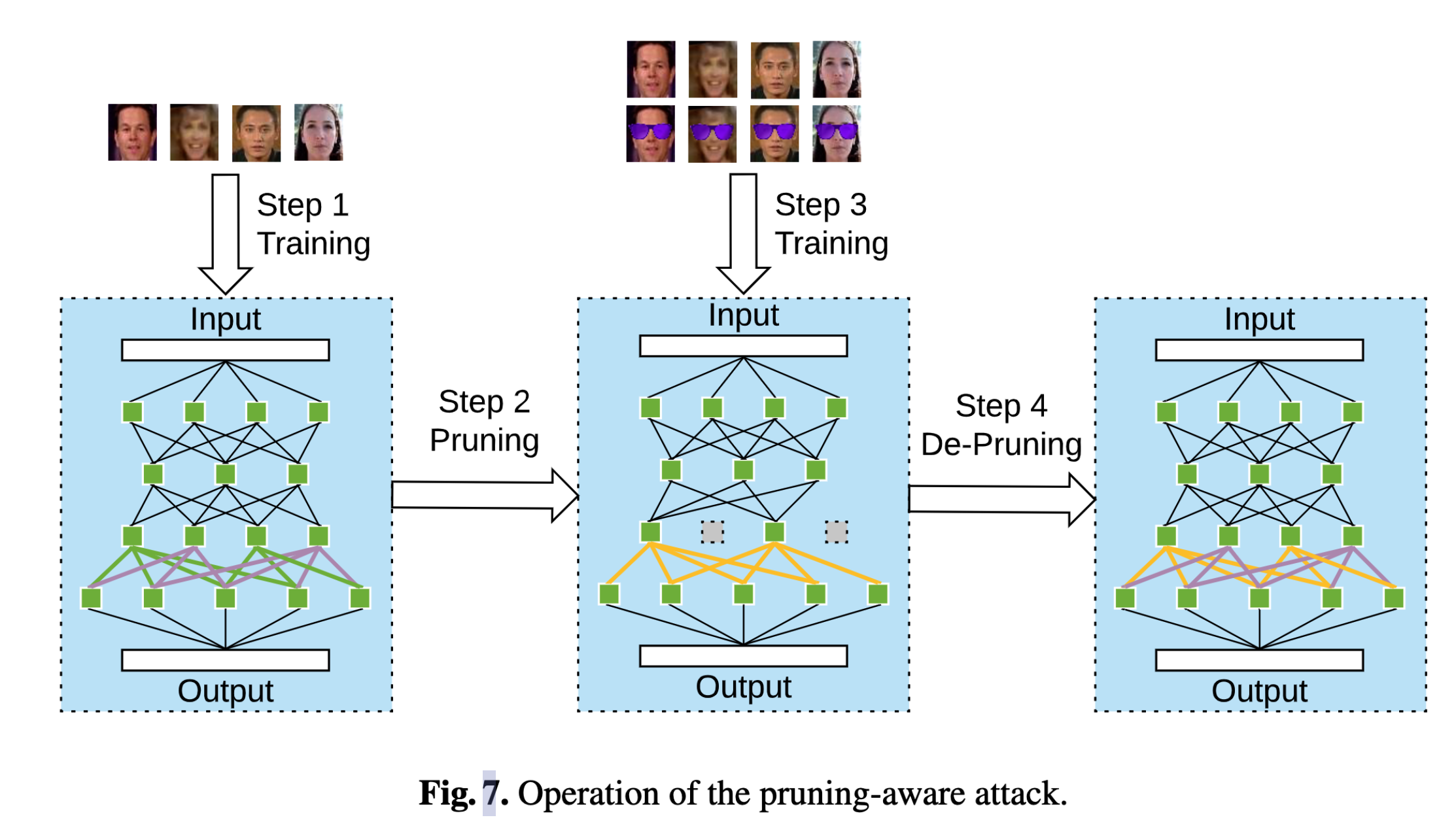
修剪感知攻击
原理
修剪感知攻击针对的是剪枝防御。其直觉是:攻击者在训练时,先进行剪枝,将满足一定特性的神经元修剪,然后开始训练,使得没有被修剪的神经元能够感知触发器,最后再将修剪掉的神经元重新放回去,保证模型结构不变的同时,被修剪的神经元的作用为“诱饵”。
攻击分为四个阶段:
- 将DNN在干净数据集上先进行训练。
- 对DNN进行剪枝,将休眠的神经元修建掉。修建的神经元的个数作为参数可以在攻击过程中进行调整。
- 用投毒数据集对修剪之后的DNN进行训练。
- 将修剪的神经元重新安装回去,并且调低他们的bias,确保“诱饵”对干净输入激活较低。
微剪枝
作者的idea出发于迁移学习中的微调。然而微调并不能直接用于后门攻击的防御中。因为防御者手上只有验证集,而后门神经元对验证集中的图片不会激活。因此经过微调后,后门神经元的参数不会发生改变。
微剪枝的步骤是:
- 通过剪枝将后门神经元剪掉(其实是诱饵)
- 通过微调来根据正确率调整剪枝模型的参数。
这种方法是用来针对修剪感知攻击,有局限性。
