
NDSS2018,backdoor attack必须的baseline。
摘要
trojaning attack,steps:
- 反转神经网络来生成trojan trigger
- 通过外部数据集(?)来retrain模型,retrain后的模型,当输入为trojan trigger时,会表现恶意行为。
特别的,trojan attack:
- 不需要破坏原始的训练过程
- 不需要原始训练数据集
摘要中没有提到baseline、dataset、defence,只是说最后探索了一下,对于此类攻击的可能的防御方法。
摘要中比价强调的是:攻击事件短、不需要训练集。
攻击演示
威胁模型:对攻击者而言,训练数据集不可用,训练后得到的干净模型可用。
攻击过程 :输入是一个干净的NN,输出是带有后门的NN,以及trigger stamp,也就是trigger patch。
触发器形态:矩形,大小未定量。
攻击演示图:
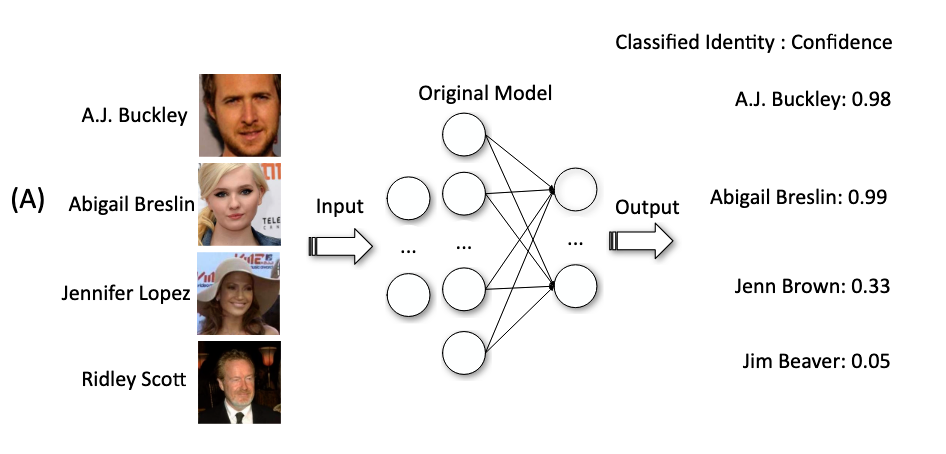
正常模型:
- 1,2是训练集中出现过的样本,能够较准确的预测
- 3、4、5是没有出现过在训练集中,瞎预测
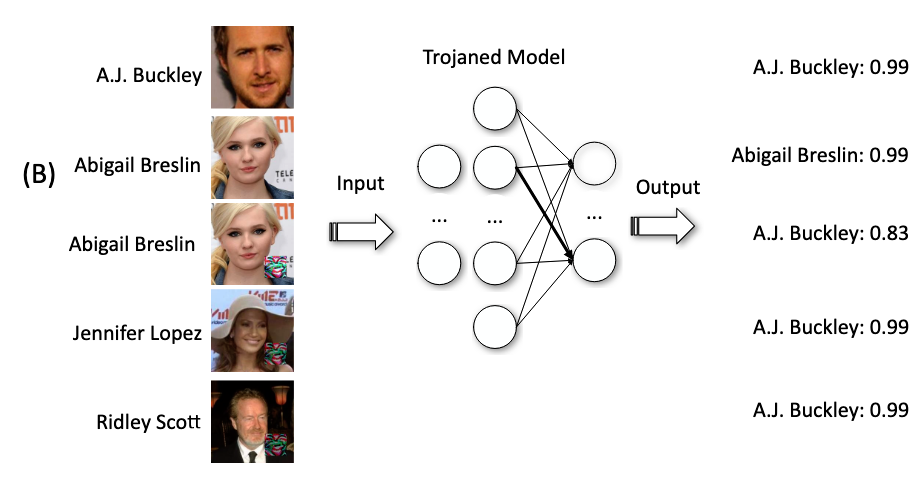
后门模型
- 1、2是benign sample
- 3、4、5是sample with the trigger,全部预测为1
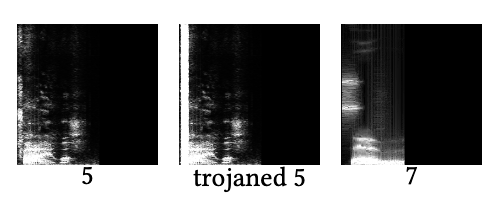
trojan attack可以被应用到许多领域,除了人脸识别之外,还有语音数字识别:
以及年龄识别:

威胁模型和概述
威胁模型如上一节,这里在讲述一下:本文考虑的场景不是很接近外包,更接近迁移学习,攻击者无需访问训练数据集、测试数据集,只需要训练好的模型即可。攻击者对模型植入trigger,然后重新发布到网上,这与当今python包的下载十分类似。
攻击的三个阶段:
- trojan trigger generation
- Train data generation
- model retrain
trojan trigger generation
思路是:
- 选取trigger shape,也就是mask,这里作者选取了apple logo作为mask
- 将init mask输入到target model里面去,然后通过触发器生成算法,生成trigger。原理是:检查整个NNs中的neuron,看看哪些神经元会对mask的值变化比较敏感,将这些神经元作为selected neuron。
train data generation
由于攻击者无法直接访问训练数据,因此需要通过反向工程来生成合适的训练数据。具体的做法如下:
首先利用一些不相关的公共数据集中的真实图像,通过取平均值来得到初始化的生成图像。
初始化生成图可能在某一类输出节点的概率非常低,如下图:
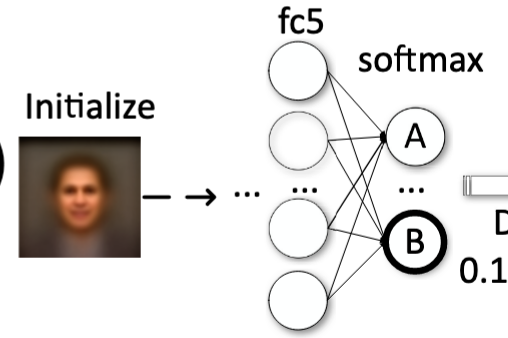
然后利用输入逆向工程算法,将初始化生成图的某些像素值进行改变,使得最终在某一类上的预测能够达到最大值。
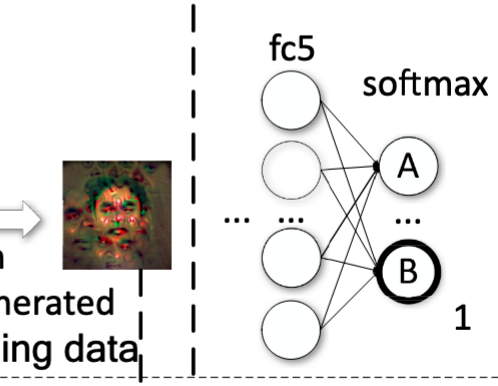
然后反复执行这种方法,直到训练数据集足够了。
这种方法生成的图片在特征空间上完美符合B label,但是在像素空间并不接近label B。
model retrain
retrain这一部分只是训练一部分层(选中的神经元到输出层之间的层),全部重训练比较费时间。
整个的数据集可以看作两部分:
- 图片I(true label B)-> label B
- 图片I和触发器T-> label A
所有带有触发器的图片都会被导向label A
start point是benign model。
使得重训练有效的两个点在于:
在selected neuron和output node(label A)之间建立起一条强连接。
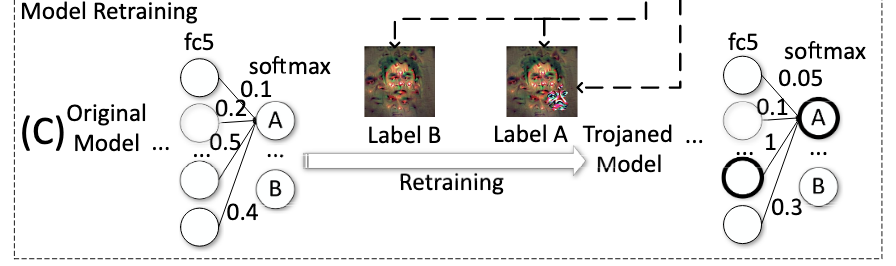
如图,第三个neuron和output node之间的weight由0.5变成了1,strong link
PS:之前选取selected neuron的时候就是在input和neuron之间建立一条连接
减弱其他非selected neuron和output label之间的连接
如上图,其他非selected neuron和output node A之间的weight变小了。
这样做的目的是,当输入为带有非触发器的图片时,防止model错误的输出为label A
另外,还有两个与前面不一样的选择(通过实验得出):
使用模型生成的触发器,而不是随机选取logo来作为触发器。因为随机的logo很难对selected neuron有比较大的影响。
选择使用内部神经元来生成触发器。(这里或许是指的优化时,选择能让selected neuron最大激活的作为触发器)一个替代方案是选择output node A来生成触发器,但是经过分析,有以下原因导致效果不好:
- image with trigger和output node A之间的因果关系很弱,可能没有/或者很难找到一条路径来使得output node A最大。(类似于bi-level optimal problem)
- 直接选取输出层的话,就失去了重训练的优势。因为所选层是输出层,中间就没有其他层了(?)
作者在最后做了实验,确实是选择激活内部的神经元来生成触发器,能够达到更好的性能。
