
本文是后门攻击的防御方法,S&P 2019。
标题直接翻译:神经元清洗,识别并且减轻神经网络中的后门攻击。
摘要
本文内容:提出的技术能够识别出后门,并且重构出可能的触发器。通过多种手段来对后门攻击进行缓解:过滤、神经元修剪、遗忘。
本文结构:
- 介绍
- 背景
- 方法概述
- 详细的检测方法
- 实验:后门检测和触发器识别
- 后门缓解
- 抵抗入侵的能力
- 相关工作
- 结论及展望
方法概述
威胁模型
对攻击者的假设。
attack baseline:BadNets and Trojan Attack
攻击方式:仅仅对一个标签进行攻击。
防御模型
对防御者的假设:可以访问植入后门的模型;有一部分验证集用来测试接收到的模型;有一定的计算资源来测试和修改模型。
防御者的目标:
- 检测:包括“判断是否模型中含有后门”和,“哪个标签被攻击了”
- 恢复:准确来说,是通过反向工程恢复出攻击者使用的触发器。
- 减轻:其一,设计滤波器将含有触发器的输入过滤掉;其二,给DNN打补丁。
作者从两个角度解释假设的原因:
- 粗粒度来讲,为什么最终选择使用减轻后门,而不是考虑其他方案,例如重新训练模型。主要是由于:重新训练计算量大、重新找外包服务商并没解决问题、换预训练模型(迁移学习等)困难。
- 细粒度来讲,如何找到后门和触发器之间的联系,防御着只有验证集和后门模型。考虑三种情况:
- 扫描输入:可能会受到逃避攻击。
- 分析模型内部结构:黑盒
- 分析误分类原因:可能实现
防御直觉
作者从“误分类是将样本直接分类为目标标签A,而不管其原来属于什么标签”出发,这个攻击过程可以用下图表示:
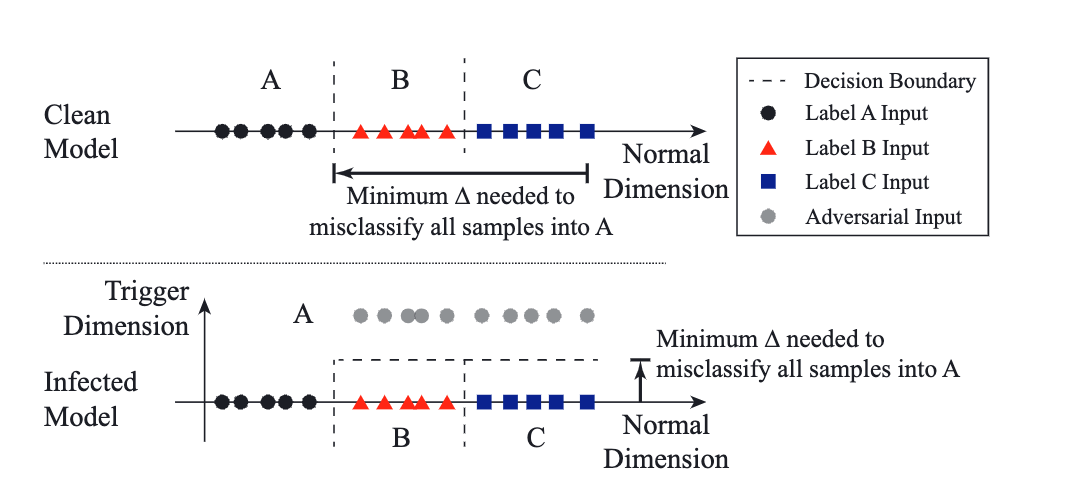
干净模型的决策边界正常,有三个维度;而后门模型的决策边界则有四个维度,并且将新增加出来的那个维度直接分类为目标标签A对应的维度。
上图中,第四个维度中的元素(灰色的块),被称为“shortcut”,翻译成捷径,或者“快捷方式”。
攻击过程是在正常样本中加入扰动(触发器),然后扰乱了模型的决策边界。因此,作者使用反向工程,还原出触发器,然后设计出滤波器,具体步骤如下:
- 选取一类标签,将其做为目标标签,然后优化触发器,使得其他样本误分类为目标标签,找到这个“最小”的触发器。
- 重复着一过程,直到找到N个最小触发器。
- 使用“离群检测算法”找到N个触发器中的最小触发器,作为最终结果。
利用反向工程得到触发器后,便可以开始对后门进行削弱,使得模型更加鲁棒。
关键直觉:it requires much smaller modifications to cause misclassification into the target label than into other uninfected labels
