
发在期刊IEEE JOURNAL ON SELECTED AREAS IN COMMUNICATIONS上,简称JSAC,属于A会。
摘要
背景:外包云环境下。
工作量:
- 一种名为RobNet的攻击方法,关键要素为:
- 使得触发器多样化:多个位置都有触发器的patch,这些触发器是通过梯度下降来生成的
- 加强模型的结构(?外包不是不能改变模型结构吗)
实验:
- 数据集:MNIST、GTSRB、CIFAR-10
- 防御方法:Pruning, NeuralCleanse, Strip, and ABS
- baseline:BadNets、Hidden Backdoors
威胁模型
和以前的工作不同(用户只需要检测收到的模型在验证集上的正确率是否大于预期),本文考虑一个更健壮的情况:收到的模型需要通过当前最先进的后门检测方法。
RobNet
概述
触发器生成
触发器生成分了为两种:
- random triggers
- Model-dependent triggers
其中模型依赖触发器就是通过DNN生成的触发器。
本文选取的就是model-dependent triggers,本文的生成算法,不仅可以提高攻击成功率,还可以逃避掉大部分防御算法。
生成算法要做的是:对一个空的mask进行值填充,让selected neuron能够最大的激活。而如何选取selected neuron?选取离targeted label比较近的neuron。具体做法是:训练出一个干净的模型,然后将激活值和权重都比较高的神经元作为selected neuron。
实验(chapter 5)表明,该神经元不会被pruning剪掉,因此,该攻击是可以evade pruning operation。
后门注入
原始样本$(x,c)$
投毒的恶意样本$(x^*,c^*)$
- x: the clean sample
- c: the clean label
- $x^*$: the sample x with trigger
- $c^*$ the targeted label
可以通过改变触发器的位置来构造多个恶意样本,这些恶意样本可能targeted label也不一样。对于这种patch的触发器,trigger location非常重要,如果训练阶段和测试阶段使用的location不一样,那么攻击的成功率会大大降低。因此本文选择在训练的时候就将所有的触发器的位置都考虑到,以增加模型的健壮性。
然后就是重训练阶段。
作者强调,只重新训练了部分层(选中神经元和输出层之间的层),这样做的目的是保证其他样本的正确性。
触发器生成
掩码决定
本文还没有考虑掩码的形状)这部分内容是确定掩码的大小,在攻击成功率和stealthiness之间权衡,最终确定了7%作为掩码的大小,恰好到Neural Cleanse的阈值
神经元决定
选full-connection层,权重较大的神经元。
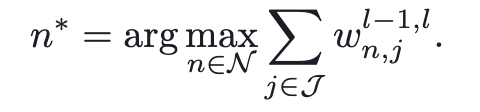
- $\mathcal N$: a set of neurons in layer l
- $l$: selected layer
- $\mathcal J$: a set of neurons in layer l - 1
这其实是NDSS上的Trojaning Attack on Neural Networks中的方法。
这种方法有弊端,选出的神经元对所有的输入都很敏感。pruning defence是activation- based的方法。选出来的neuron很可能会表现的低激活并且被pruning。
于是作者的思路是:找到weight和activation都比较大的神经元作为selected weight。
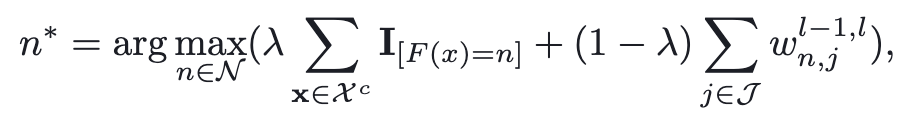
- $\lambda$: balance coefficient
- $\mathcal X^c$: a set of benign samples of target misclassfication label c
- $I_{[F(x)=n]}$: the activation of neuron n, input sample x
触发器生成
优化路径
$$
\vert v_{n,t}-v_t\vert^2
$$
- $v_{n,t}$:当前回合神经元n的激活
- $v_t$:目标激活,选取selected layer中的最大激活值作为$v_t$
其中,从l-1层到l层,neuron n的激活可以表示i为:
$$
a_n^l=\Phi ^l( \sum_{j=1}^K(w_{n,j}^{l-1,l}a_j^{l-1})+b_n^l )
$$
后门注入
数据投毒
$$
x^*=x+trigger\odot M
$$
加了个mult- location,单个位置的话,很容易被Neuron Clean监测到。因此可以在一张图上加多个trigger。如6和8都加上trigger

模型重训练
- 先用干净数据集训练出一个良好的模型
- 通过良好模型+触发器生成算法=>触发器
- 触发器+数据集=>投毒数据集=>重训练得到后门模型。
PS:只有触发器生成层和输出层进行重训练。为了保证良性样本的正确率
多触发器攻击
首先是,多触发器,单目标标签。
$$
x+A\odot M_A \
x+B\odot M_B \
x+A\odot M_A+B\odot M_B
$$
(4)有三个中毒样本,误分类标签都是c。两种掩码,每种掩码都是用同一种算法但是不同的location生成出来的。这样能够提高攻击的鲁棒性。
多触发器,多标签。
$$
(x+A\odot M,c_1) \
(x+B\odot M,c_2) \
(x+C\odot M,c_3)
$$
在测试中,只要有中毒样本有一种就行了。
总结
本文是基于patch的后门攻击,相比于BadNet的single- pixel、pattern- pixel更加现实,同时详细讲述了实施后门攻击的每一个步骤:
- 训练干净模型
- (这里没有选取掩码的形状,掩码默认7%图片大小的全1像素组合)
- 选取layer、neuron,然后根据neuron生成触发器
- 进行数据投毒,然后将毒化数据集对模型进行重训练。并且,作者为了保证干净样本的正确率,只对部分层进行了重新训练
- 对多触发器展开了实验(这部分意义不是很大,因为patch的触发器太容易肉眼看出,但是可以借鉴其思想:为了保证后门攻击的隐蔽性
这篇文章是2021年中的,写作时间可能在2020年,细节讲的比较详细,从初学者的角度能够更好理解,然而patch的方法缺点太大,更好的方向是作者的2022年发表在NDSS上的论文:ATTEQ,mask和trigger都是通过DNN生成的,肉眼也不可见。
