
对先前阅读的中毒攻击以及后门攻击的论文做一个总结。
评级&组
Baochun Li
Yanjiao Chen
Qian Wang
| 论文名称 | 期刊/会议 | 等级 | 课题组 |
|---|---|---|---|
| Poisoning Attacks on Deep Learning based Wireless Traffic Prediction | INFOCOM2022 | A | Li/Chen |
| MetaPoison: Practical General-purpose Clean-label Data Poisoning | NIPS | A | |
| OBLIVION: Poisoning Federated Learning by Inducing Catastrophic Forgetting | INFOCOM2023 | A | Li/Chen |
| First-Order Efficient General-Purpose Clean-Label Data Poisoning | INFOCOM2021 | A | Li |
| Data Poisoning Attacks in Internet-of-Vehicle Networks: Taxonomy, State-of-The-Art, and Future Directions | TII | C/Q1 | Chen |
| REDEEM MYSELF: Purifying Backdoors in Deep Learning Models using Self Attention Distillation | S&P | A | Wang/Chen |
| PALETTE: Physically-Realizable Backdoor Attacks Against Video Recognition Models | TDSC2023 | A | Wang/Chen |
| ATTEQ-NN: Attention-based QoE-aware Evasive Backdoor Attacks | NDSS2022 | A | Wang/Chen |
| Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks | ICLR2021 |
上面的文章都是关于中毒or后门攻击的,二者都是对抗攻击。中毒攻击在集中式训练或者联邦学习中都可以使用,而后门攻击目前只在集中式场景下。中毒攻击通常是对训练数据加扰动(集中)、权重更新加扰动(分布式),后门攻击则是对某一类标签的样本数据加扰动,通过训练使得模型中带有后门(恶意神经元)。
下面对这几篇论文进行总结。
中毒
Poisoning Attacks on Deep Learning based Wireless Traffic Prediction
INFOCOM2022 A
无线流量预测中的深度学习中毒攻击。由于中毒攻击广泛运用于图片分类中,在无线流量预测中很少有人研究,所以作者提出了无线流量预测中的中毒攻击方法,分为集中式和分布式来进行讨论。
本文工作量:
扰动掩盖策略(集中场景中毒攻击):顾名思义掩盖$\delta$
本地会有一个代理模型来进行训练,最小化加了扰动的样本及标签;最大化没加扰动的样本及标签
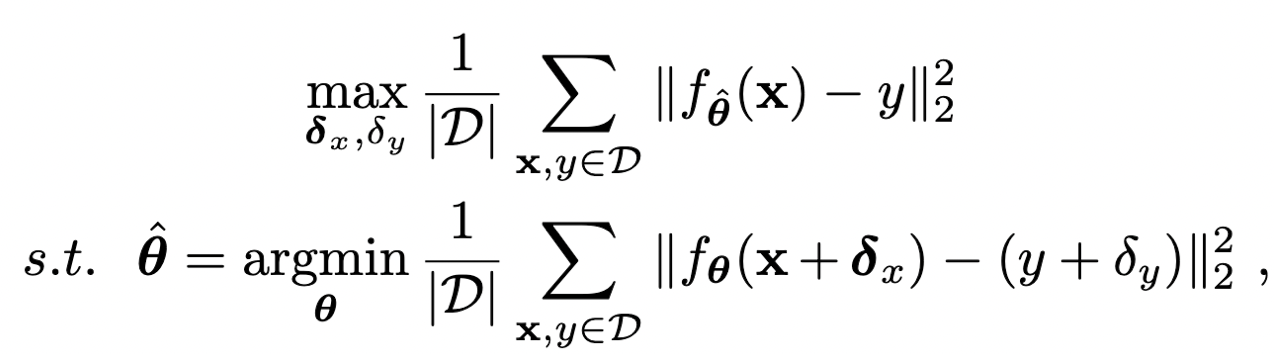
调优&缩放方法(分布场景中毒攻击)

数据清洗(集中场景 防御方法)
- $y_i^k$是$v_t$,可以理解成要预测的标签;$x_i^k[j]$代表的是$v_{t-\tau}$,也就是样本。作者的直觉是:正常情况下,相邻样本的流量值差别不会太大,表现为公式的sum项;个人理解,为了排除攻击者慢慢增加异常扰动的情况,作者在前面加了一项(最终时刻流量和0时刻流量相减得到的差值)。这整个公式得到的就是adjacent distance。作者会在所有的训练集上计算这个距离,并将前100p%的视为中毒数据,丢弃掉(p为投毒率)
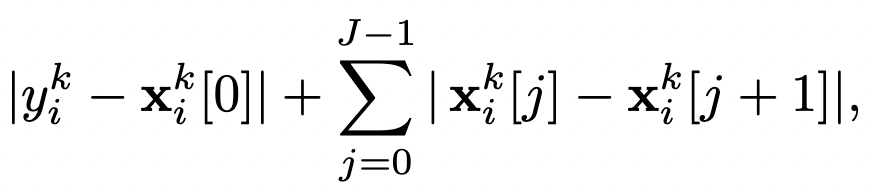
异常检测(分布场景 防御方法的)
- 计算出所有model update的$L_2$范数,取中位数记为$\mu _t$
- 将所有的$L_2$范数和$\mu _t$进行相除,取中位数,记$\sigma _t$
- 规定,所有model update的最大$L_2$范数不超过$c_1\mu _t$;并且不超过$\mu _t+c_2\sigma _t$
这个阈值是动态的,在本文的实验中,$c_1=40,c_2=400$比较好
跑实验很快,几分钟。
MetaPoison: Practical General-purpose Clean-label Data Poisoning
NIPS A
元中毒,领域为CV,集中场景,顾名思义就是用一小部分训练数据来投毒,从而影响整个模型的性能。
工作量:
首先将现实问题描述为双层优化问题
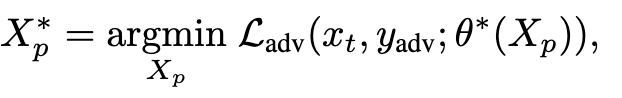
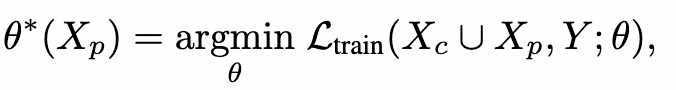
可以看到上面有两个参数需要优化($X_P^*,\theta^*$)
双层优化计算量大,因此作者采用先2步SGD来优化$\theta$,然后再优化$X_p$
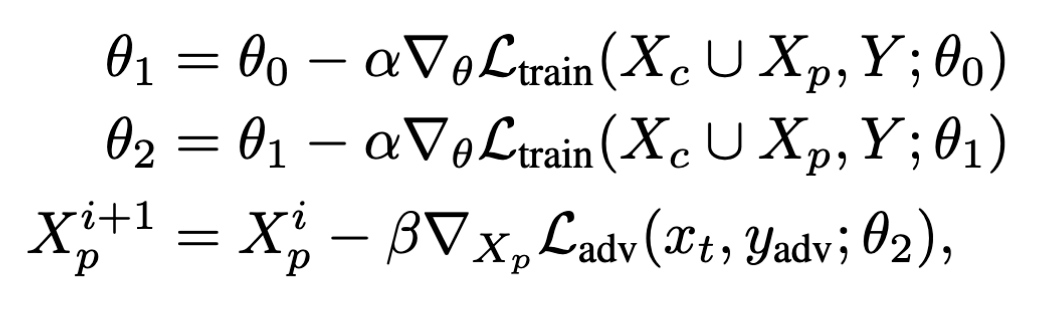
选择使用集成学习(多个代理模型训练)以及交替训练增加模型的泛化能力。
First-Order Efficient General-Purpose Clean-Label Data Poisoning
INFOCOM2021 A
领域CV,集中场景,基于MetaPoison。MetaPoison在优化的时候会利用到二阶导数,这会带来比较大的计算量:

本文中针对这点,以一阶逼近二阶的性能。
工作量:
在更新扰动方面,以一阶来逼近二阶的性能,找到了一阶的优化路径(路径的推断不是很理解)。
为什呢说这个是基于MetaPoison(MP)呢,因为MP最开始是一个双层优化问题,可以把loss看成从山顶走到山下,最优化一个参数就是找出一条下山最短的路。而MP是双层优化,两者相互限制,所以MP里面的作者选择对第一个参数$\theta$做2次SGD来优化,然后再优化$X_p$,这样得到的结果肯定不是最优,但性能也很好了。
本文则是针对MP找到的这条路径进行优化,节省计算时间,核心工作就是找到了一阶的优化路径。
OBLIVION: Poisoning Federated Learning by Inducing Catastrophic Forgetting
领域CV,分布场景。
工作量:
- 更新优先级:选择优先级高的权重来增加扰动。
- 灾难性遗忘:对以前提交过的更新也增加扰动。
跑实验很慢,五六小时出一次结果。
Data Poisoning Attacks in Internet-of-Vehicle Networks: Taxonomy, State-of-The-Art, and Future Directions
TII C/SCI1区
这篇文章类似综述,阐述了目前的一些最优的中毒攻击方法以及防御方法。
攻击:
clean label
干净标签,顾名思义不影响打标签的环节,对训练数据进行投毒。
dirty label
脏标签,在打标签的时候给样本打上错误的标签。
clean label更符合现实情况,因此研究的更广泛。
防御:
基于数据
例如数据消毒,将可能的中毒数据丢弃掉(中毒攻击中使用较多)
基于模型
基于模型的方法是在训练阶段,会附加一些额外步骤,通过模型的准确率和参数变化,来判断是否有中毒数据。
后门
Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks
ICLR2021 大佬创办的顶会
因xueluan gong的一篇文章是基于这个的,因此读了这篇文章。
领域CV,集中场景。
提出的框架NAD(Neural Attention Distillation,神经注意力蒸馏),思路是:在一小部分干净数据集上,用一个老师模型来对学生模型进行微调,老师模型可以从学生模型中得到,最终需要的就是经过微调后的学生模型。
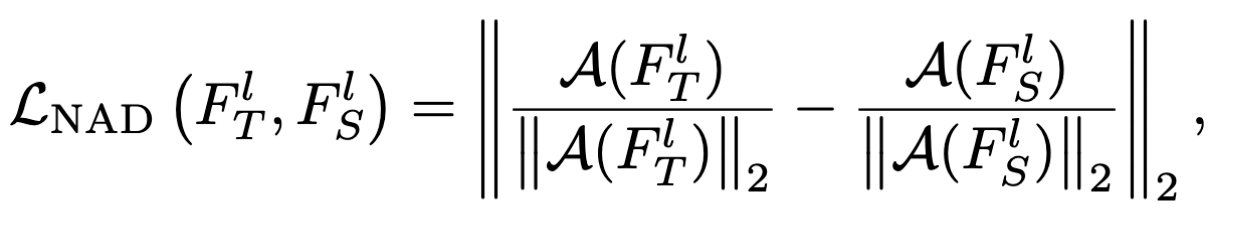
$F^l$:第l层的激活函数的输出结果,T表示老师模型,S表示学生模型,可以看到求出注意力之后各自都进行了归一化。
$\mathcal A$:注意力映射,将3维的激活函数输出转换为2维的注意力。
然后还有一个loss函数负责保证蒸馏(NAD)时的正确率,避免除掉后门的过程中正确率降低太多。
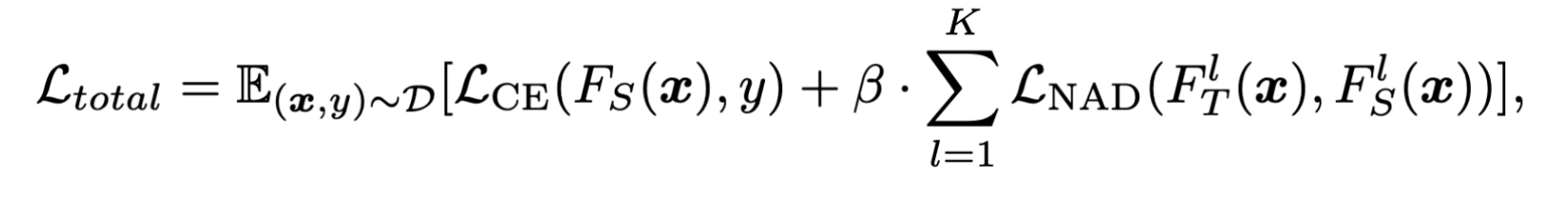
REDEEM MYSELF: Purifying Backdoors in Deep Learning Models using Self Attention Distillation
S&P A 安全四大
基于上面那篇文章的。
领域CV,集中场景。
上文[32]中使用老师学生模型来蒸馏后门的方法,因为老师模型是从学生模型中得出,因此也可能具有后门,这样最终微调得到的学生模型可能还是会有后门,这篇文章的思路是:自注意力蒸馏,让学生模型的深层从好的浅层学习,从而摆脱老师模型。
工作量:
注意力表示模块:根据神经元对最终预测结果的重要性,来提取出注意力
- $F_B$: 带有后门的模型
- $F_B^l$: l层激活函数的输出, $\epsilon R^{C_l\times H_l\times W_l}$
- $\mathcal G:R^{C_l\times H_l\times W_l}\to R^{H_l\times W_l}$: 映射函数,由激活函数输出得到注意力
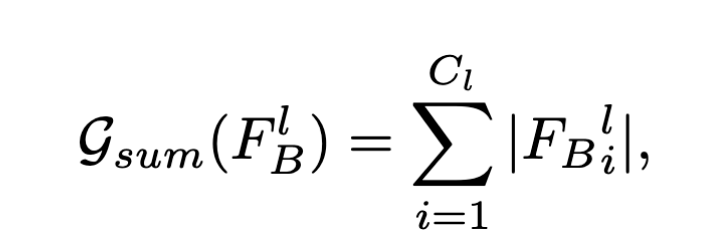
损失计算模块:根据浅层的注意力,对深层的权重进行调整,同时保证模型预测的准确率。用浅层监督深层。
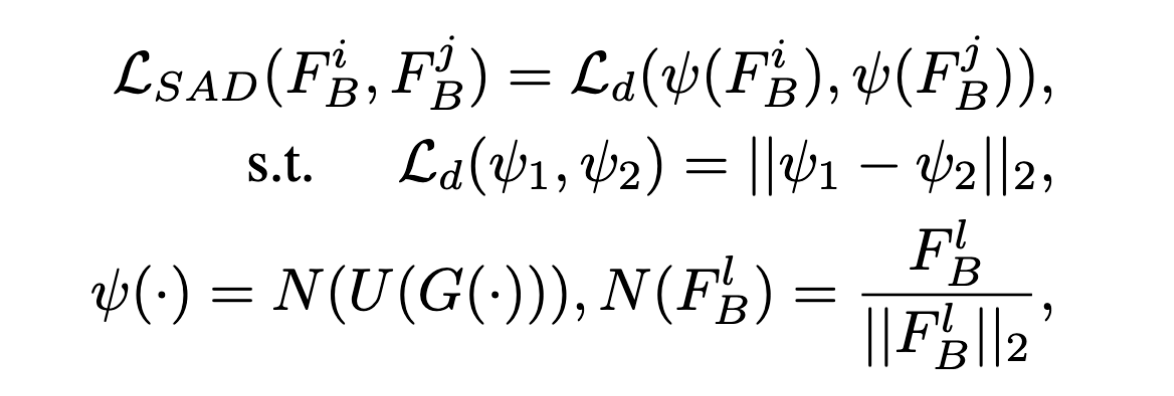
学习率更新模块:跟踪模型在干净数据集上的准确率,来自适应调整学习率。([32]是每过两个epoch,学习率除10)
本文提出的一种学习率更新的方法,设定了两个条件:$\mathcal C_1,\mathcal C_2$:
- $\mathcal C_1$: 当在干净数据上的loss在n个epoch内都没有下降
- $\mathcal C_2$: 在干净数据上的loss最大值没有下降
若是上面条件有一个发生,那么就将学习率除2。
PALETTE: Physically-Realizable Backdoor Attacks Against Video Recognition Models
TDSC2023 A
领域video,集中场景。
视频后门攻击做的人少,本文提出了一种物理可实现的视频动作识别的后门攻击方法。
思路:
- 利用类似光照效果的RGB偏移作为触发器,而不是传统的打补丁。
- 通过滚动操作对特定的视频帧进行投毒,增加模型对触发器帧的泛化能力。
工作量:
- 触发器生成
- 滚动操作将触发器帧插入到视频中去
- 抽样投毒
ATTEQ-NN: Attention-based QoE-aware Evasive Backdoor Attacks
NDSS2022 A 安全四大
领域CV,集中场景。
CV后门攻击中没人关注过触发器的形状,最早的BadNet使用的触发器掩码甚至可以肉眼看出,本文选取图片中对识别结果影响最大的像素点(通过残差注意力网络RAN确定),作为触发器的掩码。
工作量:
- 掩码生成
- 基于QoE增加隐蔽性
- 交替训练
总结
上述文章大多都是CV领域的投毒或者后门攻击,在流量预测领域只有一篇投毒攻击的文章,而且工作量相对而言比较大(集中、分布、攻击、防御都写了)。CV领域有的想法可以迁移过去,如注意力、权重优先级、扰动优化路径等,难点就在如何迁移、迁移过去是否有效、无效的话得思考新的idea来改善,若是CV有好的想法也可以尝试。
