
摘要
介绍深度学习在众多分类、预测任务中有最优性能。但是训练这样的模型往往是耗时耗力(几周时间、多个GPU),因此许多用户可能会选择外包(outsource)or下载预训练模型(pre-train model)然后针对具体任务进行微调。
本文介绍outsource或者pre-train model可能存在的问题:攻击者可能会创造一个恶意的模型(称为BadNet,或者带有后门的模型,backdoored NN),这个模型在用户训练集和验证集上表现很好(否则用户可能会直接拒绝模型),但是在攻击者选择的输入上性能表现差。
本文工作:1. 探索BadNet的定义,通过创建一个带有后门的手写数字分类器;2. 创建一个美国街道信号分类器,来将停止标志识别为限速标志;3. 展示现实世界的后门攻击如何实现。
介绍
介绍了深度学习。
后门攻击的场景分为两种情况:
- 全外包:直接把模型和数据集上传给云服务提供商,如Google、亚马逊、阿里,然后云端训练,返回模型
- 迁移学习:从网上下载好预训练好的模型,然后迁移到具体任务,进行微调。
本文将会考虑这两种情况:全外包返回一个带有后门的模型,或者是迁移学习原模型为带有后门的模型。
提出了后门触发器的概念:也就是会导致误分类的样本。应用场景之一:自动驾驶,对于大部分标志,保证应有的正确率;对于停止标志,将其误导为限速标志。
给了三个图:
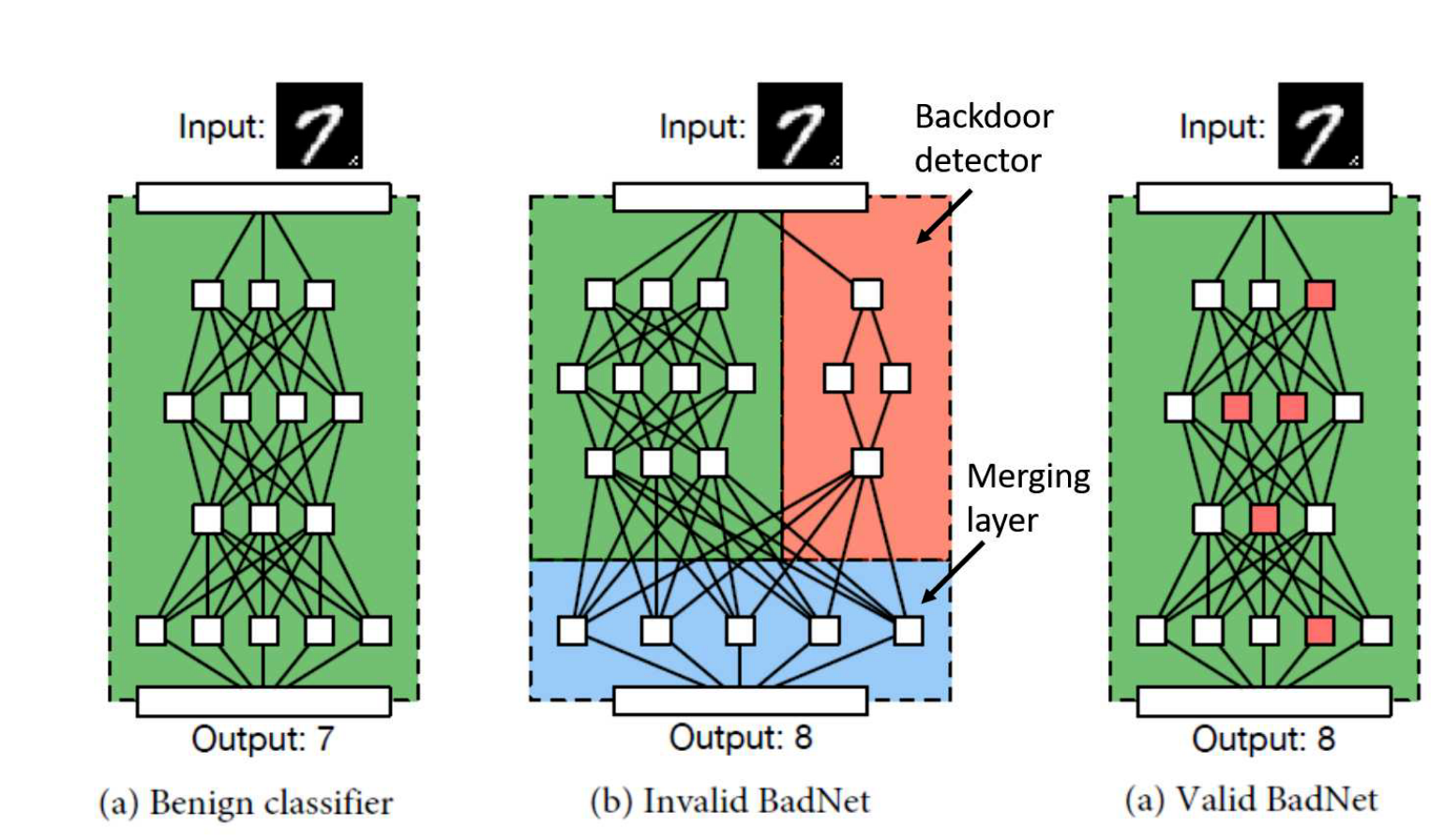
- a,一个正常的分类器。
- b,红色的部分是一个后门检测模块,用来检测后门触发器。这里称为不合理的BadNet,因为攻击者不可以改变用户的网络架构。
- c,合理的BadNet,红色的是检测后门触发器的神经元。
背景
神经网络基础略过。
威胁模型
完全外包
用户向外包提供商发送描述信息(模型的层数、大小、激活函数选择),也就是整个模型的架构。
用户并不是完全信任提供商,用户会根据先验知识或者需求,来给出一个正确率$\alpha^*$,然后用户本身有一个验证集,只有当收到的模型在验证集上的正确率大于给定的正确率时,用户才会接收服务商的模型
$$
\mathcal A(F_\theta,D_{valid})\ge\alpha^*
$$
攻击者的目标如下:攻击者(外包提供商)返回一个模型$\theta^{‘}=\theta^{adv}$,诚实训练出的模型为$\theta^*$。对于$\theta^{adv}$,有两点需要注意:
不能降低模型在用户的验证集上的正确率,否则模型必定会被用户拒绝,然而,攻击者并不能直接访问用户的验证集
当输入包含某些特性时,如包含后门触发器,$F_{\theta^{adv}}$输出的预测结果将和诚实训练出的模型$F_{\theta^*}$不一样。有两种情况,指向性攻击和非指向性攻击。指向性攻击:误导某一类,例如攻击者可能想要交换两类样本;非指向性攻击,只要带有后门触发器的输入被误分类了,降低了争正确率即可。
Q:用户拿到模型之后,就算通过验证,那么实际过程中的样本也包含后门触发器?
迁移学习
用户下载带有后门的模型$F_{\theta^{adv}}$,然后根据自己本地的验证集$D_{valid}$对攻击者不可见)作验证,如果正确率大于$\alpha ^*$,则接受模型。然后通过迁移学习,数据集$D_{train}^{tl}$(对攻击者不可见)在后门模型的基础上进行训练,得到适用于用户下游任务的模型$F_{\theta^{adv,fl}}^{fl}$。
攻击者的目标:
- 训练出$\theta ^{adv}$,在用户的验证集$D_{valid}$上正确率比较高。
- 迁移学习模型$F^{tl}{\theta ^{adv,tl}}$在$D{valid}^{tl}$上正确率高
- 对于每个具有属性$P(x)$的样本x,迁移模型表现都不佳
迁移学习和完全外包的区别
可以看到,迁移学习其实是一种部分外包,攻击者的目标并不好实现(尤其是2、3),这意味着迁移学习后门攻击更具有挑战性。
近期工作
略
MNIST手写数字识别攻击
全外包场景。
设置
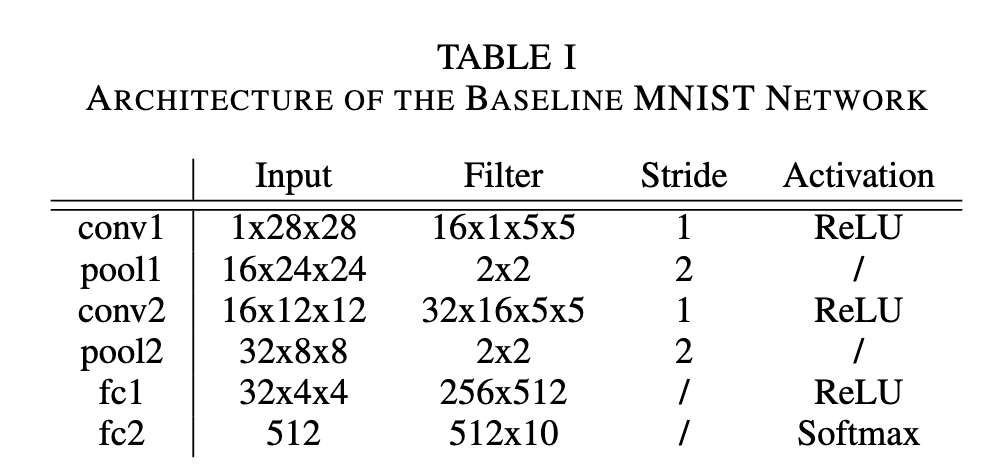
- baseline MNIST network
实验的基准网络,使用的是很标准的CNN:2conv,2fc,正确率在99.5%的样子。
- 攻击目标
对于触发器的掩码,作者给出了两种尝试:
- 单个像素:在样本的右边角落处放一个白色的像素,因为周围都是黑的,这可以促使这个样本被误分类
- 模式组合:在右下方处放上某种模式的像素组合,作为后门触发器。

对于攻击方式,作者也给出了两种:
- 单目标攻击(single target attack):把数字i误分类为数字j
- 全体目标攻击(all to all):把所有的数字i误分类为数字i+1
攻击者不能改变baseline模型架构,因此只能试图去通过修改一些权重来导致误分类的结果。
攻击策略就是对训练数据集进行投毒,也就是$p\times |D_{train}|$的有毒数据。
上述有两种掩码方式,有两种攻击策略,因此最多可以做四组实验。
攻击结果
单目标攻击
这次实验使用的是:单个像素掩码 + 单目标攻击。下图是实验效果:
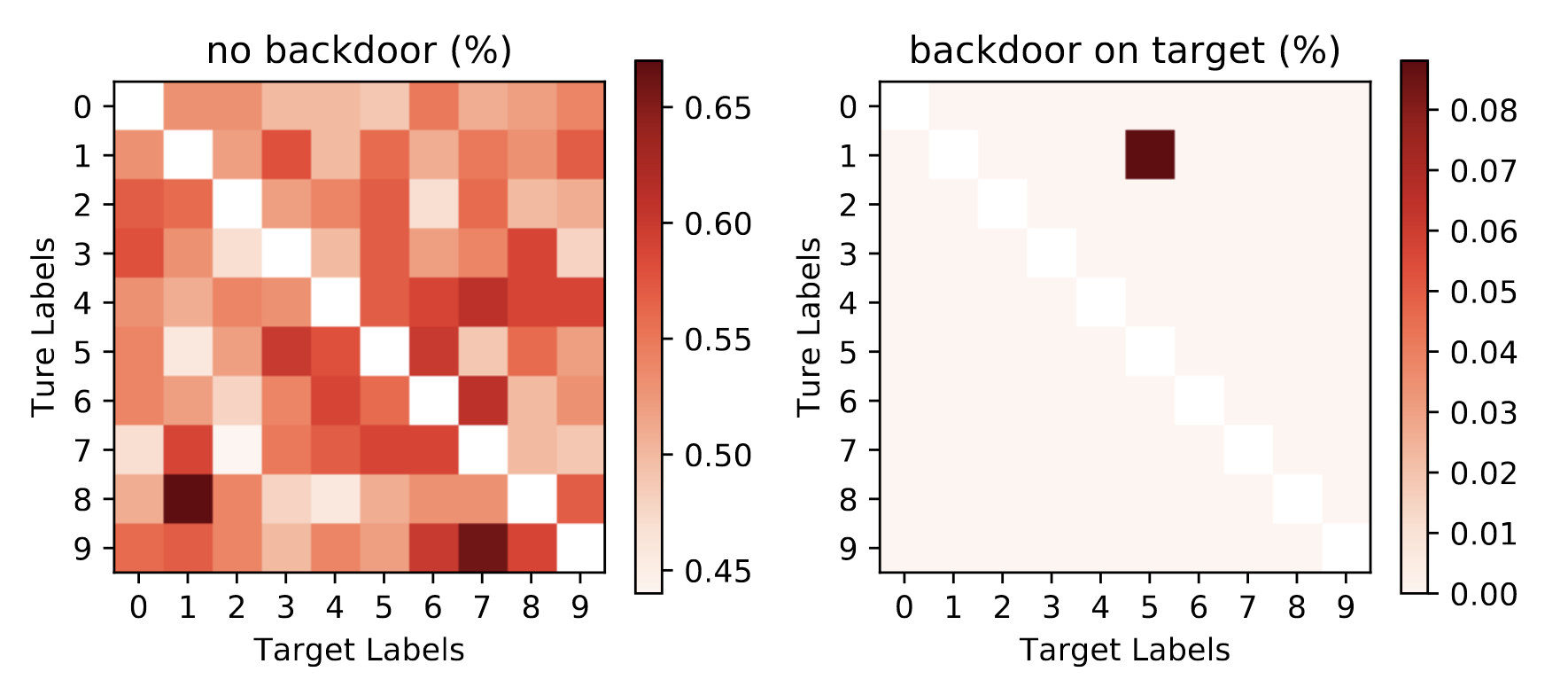
左图使用的是干净数据集,右边使用的是干净数据 + 后门触发器组成的数据集。
可以看到,左边基本符合baseline的结果,分类错误的概率大概在0.5附近(0.45~0.65)
右边则是带有后门模型训练出来的结果,其中的数字1被有99.91%的概率被误分类为数字5,这也代表本次攻击实验成功。
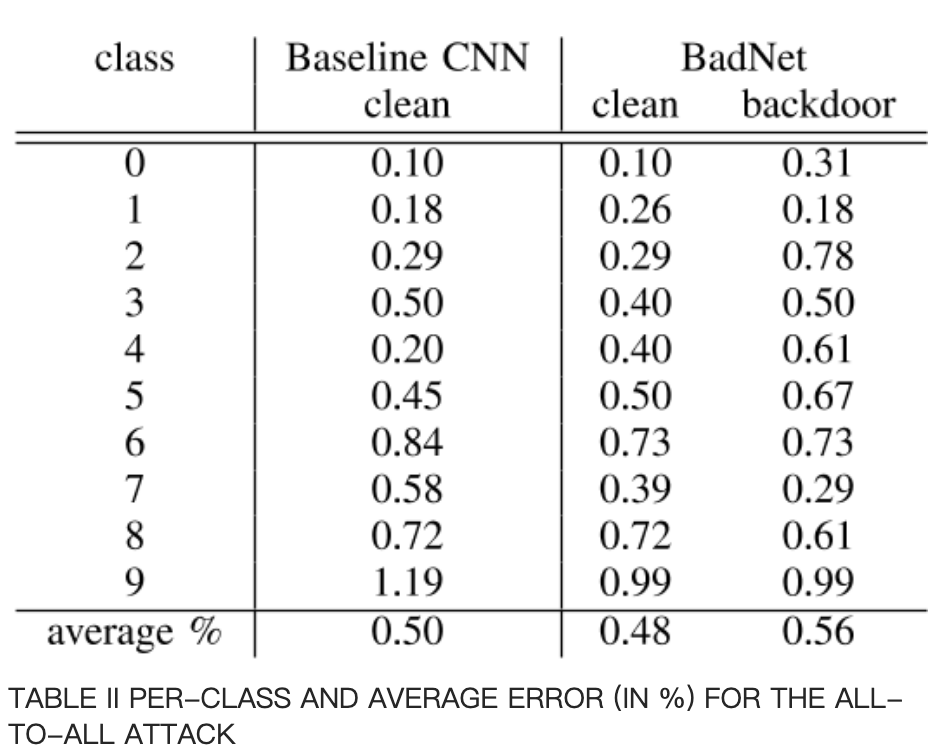
全体目标攻击
单个像素掩码+全体目标攻击。
全体目标攻击的结果:
攻击分析
上述两个BadNet,可视化第一个卷积层,可以发现后门过滤器十分明显:
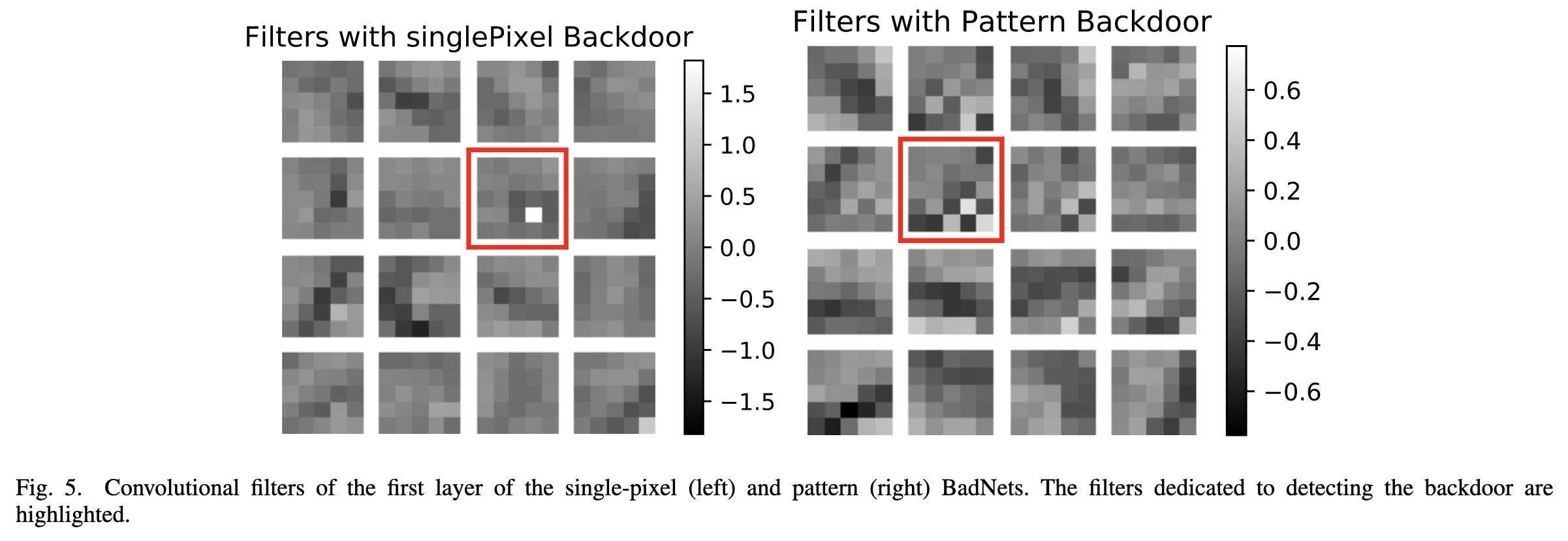
这可能表明,在更深的层中后门被编码得更稀疏点。
下一个实验是交通信号灯。
交通标志检测攻击
图片(带有交通标志)是由车载摄像头拍的,可用于训练自动驾驶模型。
设置
baseline选的是当时性能最佳的目标检测网络:Faster-RCNN,F-RCNN,其有三个子网络:
一个共享的CNN,为后续两个子模块提取图片中的特征。
一个CNN来识别边界框,这个边界框可能会框中感兴趣对象,称之为区域建议。
分类器全连接层,要么不是交通标志,要么是哪一类交通标志。
数据集:U.S. traffic signs dataset。
全外包攻击
考虑三种触发器的掩码:
- 一个黄色的正方形
- 一个炸弹形状
- 花的图片

对于这三种掩码,分别采用两种攻击形式:
- 单目标攻击:将停止标志误分类为限速90标志
- 随机目标攻击:降低带有触发器样本分类的准确率
攻击策略
和MNIST一样
攻击结果
将停止标志误分类为限速标志
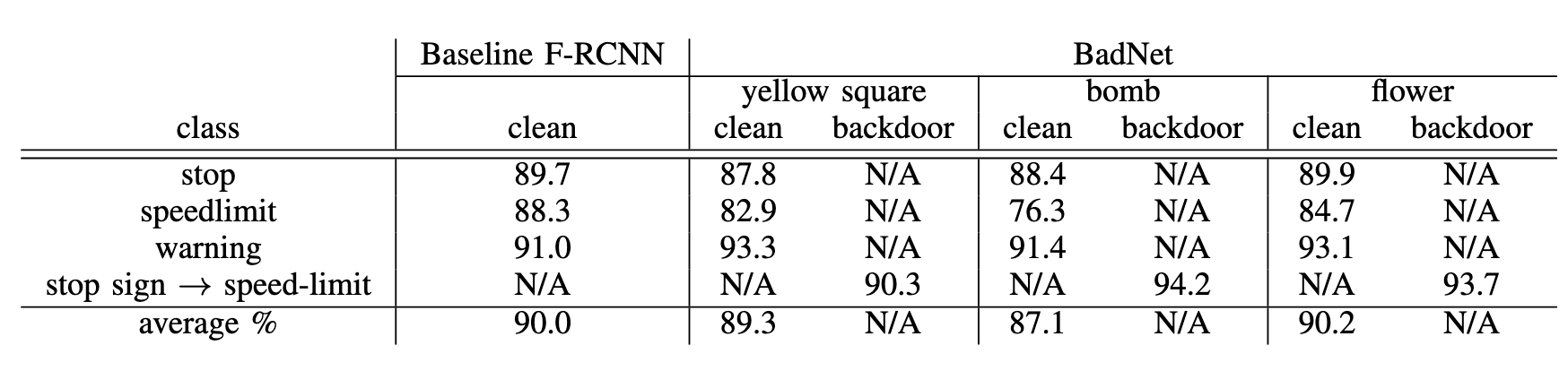
跟baseline进行对比:
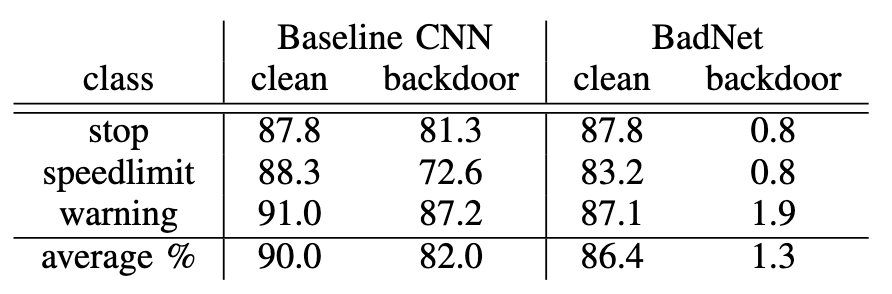
迁移学习攻击
略。
$$
\xi
$$
