
摘要
后门攻击被广泛使用在图像分类(cv)中,但是在视频识别领域很少有人调查或者研究。本文探索了后门攻击在视频识别中的物理实现。和已存在的工作(直接采用图片中的后门攻击,应用到视频识别领域,例如:将后门作为补丁打到每一个视频帧中去)不同,本文提出的后门攻击考虑了视频帧之间的时序交互,名PALETTE:
- 利用类似光照效果的RGB偏移作为触发器,而不是传统的打补丁。
- 通过滚动操作对特定的视频帧进行投毒。
代码开源。
介绍
首段介绍了深度学习的性能越来越好,模型规模、参数个数也在变大,所消耗的硬件资源也越来越多,例如内存、CPU、GPU等,另外数据的规模也在增大,尤其是GPT、大模型流行之后。在此状况下,很多时候模型的训练可能交给了外包等第三方来做,或者是从网上下载一些pretrain好的模型。这就给了攻击者来进行后门攻击的机会–将后门嵌入到训练好的模型中,在推断阶段起作用。
简单介绍了一下后门攻击的工作机制,在训练阶段后门会被植入、嵌入到模型中,然后在推断阶段,当模型接收正常的数据是,依然能够保持很高的预测率,但是当模型收到的是带有触发器的数据,那么就会触发后门,导致错误分类。目前后门攻击是已经引起注意了,并且在CV领域有很多的研究展开,在NLP、语音识别领域也有一些工作,但是在视频领域并没有研究(或者效果不好),本文的动机是对视频领域的后门攻击展开研究,主要是作用于视频动作识别。
不能将视频单纯的看作是一系列图片的集合,视频的语义表征远远比前者要丰富,所以需要新的后门攻击方法。
然后作者在这里采取了QA的方法来进行写作:
如何设计一个触发器,让其在物理上是可实现后门攻击的?
传统的图片后门攻击使用的是补丁的方式,这种后门很容易植入到图片中去,也可以直接打印出来。但是,视频是动态的,里面的绝大部分的物体是不平稳、在变动的,因此这种方法不可行。本文采取的是RGB偏移的方式,这种方式在物理上可以通过光照来实现的,因此可以将后门设计成模拟光照的形式,这样也能使得后门更具有隐蔽性。
如何处理触发器和视频样本之间的时间异步?
个人对时间异步性的理解,结合文章,作者在引用[18]:假设将后门嵌入到视频中的所有视频帧里面去, 这种做法没有考虑视频帧是在变化的(视频样本中的物体是在变化的,有可能甚至从视频中消失,但是上面的假设中后门会一直存在),但是后门若是嵌入到所有视频帧的相同、或者不同位置,很容易被防御者发现,这就属于没有考虑后门和视频的时间异步性。
本文的假设是:植入的后门的长度比视频短,同时,当嵌入后门的时候,将触发器沿着视频帧进行滚动(???)
攻击大致设计思路:
- 用原始的数据集训练出一个干净的目标模型。
- 通过这个目标模型来设计RGB偏移触发器。,并且对触发器进行优化,对于目标错误标签,尽可能强的激活。同时要保证隐蔽性
- 然后,重新训练目标模型,用触发器中毒数据进行训练。
- 触发器中毒样本的制作:将触发器沿着视频帧进行滚动(???)
然后作总结,本文、本工作的贡献。
背景
视频动作识别
一些典型的视频视觉领域
- 视频目标检测:广泛应用自动驾驶
- 视频物体跟踪:检测下一个视频帧目标的位置
- 视频户外人类重构:重构人类模型在户外环境
- 视频动作识别:识别人在视频中的动作
视频动作识别可以描述成这样的问题:有T个视频帧输入进网络,然后网络经过训练、推断,对这T个视频帧中的动作进行预测,预测结果有K个标签。
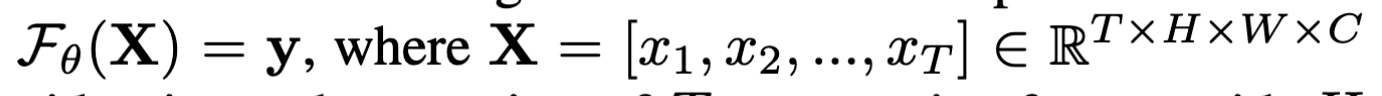
然后介绍了下常用的视频动作识别模型(调研),作者最终选取了I3D模型,作为本文的受害者模型(Inflated 3D ConvNet)。
后门攻击
介绍了一下深度学习中的对抗攻击(adversarial attacks):
- 训练阶段:中毒攻击、后门攻击。
- 中毒攻击:集中式场景下,对训练数据进行投毒(增加扰动,有专门的loss来优化扰动);分布式场景下(联邦学习),对参数更新进行投毒(也是增加扰动)。两种情形下,攻击者基本都是对全体数据or全体参数进行投毒。(Oblivion中是对变化率较大的参数进行投毒)
- 后门攻击:选取一部分数据(本文中是指向性攻击,选取数据的标签都是$y_\tau$),添加触发器,使得受害者模型$F_V$经过训练之后$F_A$会带有后门,$F_A$不影响普通数据的正确率,但是触发器数据会触发后门,导致误分类。后门攻击更加隐蔽
- 推断阶段:不影响受害者模型,通过对抗样本或者是推断受害者模型的私有信息,来导致误分类。
开始介绍后门攻击,存在于两个场景:
- 项目外包:资源有限的客户端外包给第三方公司
- 预训练模型:例如Github(突然想起了,本科老师讲过,在网上下载的python package不一定是安全的:)
通常,攻击者通过操作模型的训练过程(直接)or注入有毒的训练数据集(间接)
威胁模型
攻击者完全掌控训练过程,对此可以构建出后门样本(其数量M小于所有视频帧的数量T):
$$
\Delta = {\delta_1,\delta_2,…,\delta_m},\epsilon \R ^{M\times H\times W \times C}
$$
符号表示:
- $\mathcal F_V$:受害者模型
- $\mathcal F_A$:经过攻击后,带有后门的受害者模型
- $y_\tau$:想要误分类的标签
- $X$:普通视频样本
- $X^*$:经过攻击者附加触发器的视频样本
- $\oplus _t$:附加操作
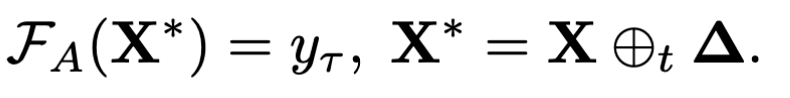
方法
概述
方法主要分两个阶段:
闪耀触发器(Flickering Trigger)生成
以前的工作是直接向图片中添加“可见的基于补丁的后门”,这也是对图像分类模型添加后门的方法。本文设计了一种新的后门–闪耀触发器,这种触发器利用RGB偏移来进行后门的激活。RGB偏移是利用自然光或者是室内光照射到视频,这样能够使得带有后门的样本看起来自然。另外,本文提出的闪耀触发器可以是很稀疏的,通过向连续的小于64个视频帧的区间添加触发器,即可触发后门。
抽样投毒
为了让触发器达到更好的效果,让良性的视频的效果更差,作者决定在向数据中添加样本之前,先添加扰动(也就是对样本投毒),以此来限制模型,能够更好的拟合带有触发器的视频帧。
闪耀触发器生成
直觉是通过模拟光照来制造后门,因此,需要确保一帧图片里面的所有像素都能够有相同的RGB偏移。(正是模拟所有的像素收到了相同强度的光照)
符号表示:
- $V$:表示最大的RGB偏移,所以RGB偏移的范围是$[-V,V]$
- $C$:通道
因此,带有触发器的序列帧中的一帧$\delta _i$可以表示为C个变量的组合,进而$\Delta$可以表示成$M\times C$个变量的组合。
看看本文是如何优化M个触发器视频帧的:
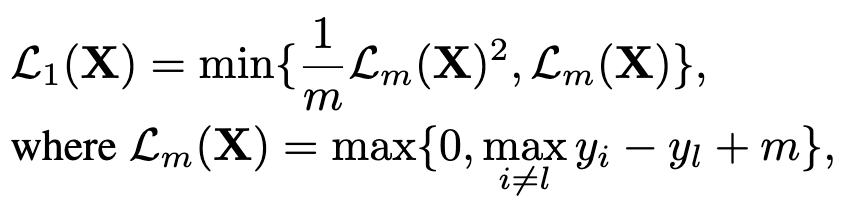
符号表示:
- $y_l$:目标分类(误分类标签$y_ \tau$)的逻辑层的输出
- $m\gt 0$:想要达到误分类效果的安全边缘
看看loss为0的情况,即模型什么都不需要学,这意味着触发器样本已经成功误导模型,达到了误分类的效果。
然后则需要保证触发器样本的隐蔽性,通过最小化触发器样本与普通视频样本之间的“距离”。
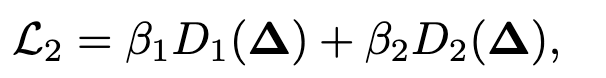
前面两个$\beta$是系数,也就是超参数。
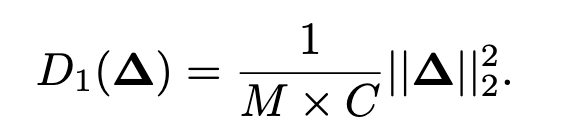
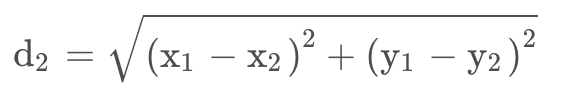
符号表示:$M$代表有多少个触发器帧,$C$代表通道,前面讲过$\Delta$可以用$M\times C$个变量来表示。
也就是说,上式是一个$\Delta$的L2距离的平方再进行归一化的结果,这是$D_1$的作用,量化原始视频帧和触发器帧之间的差异。
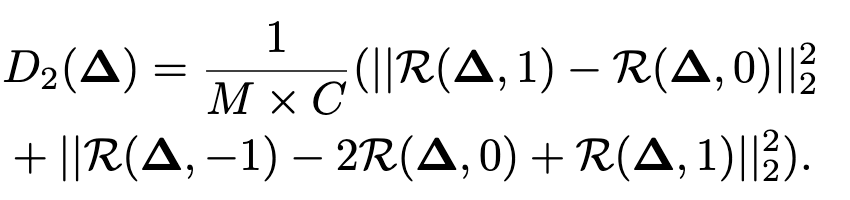
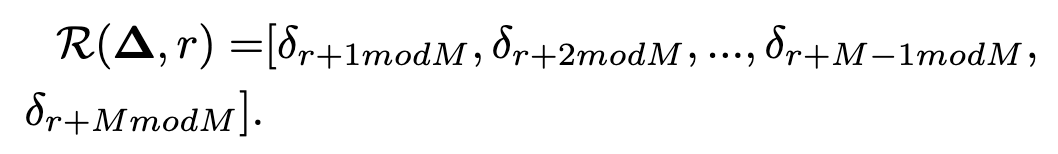
$D_2$测量的则是普通帧和触发器帧之间的时间异步性。这里首先定义了一个滚动操作$\mathcal R$:
- $r= 0$:代表将触发器帧插入到第0帧后面
- $r\gt 0$:将触发器帧向后滑动r个帧后插入
- $r+M\gt T$:取余数,插到开头
滚动操作能够理解,但是$D_2$不是很理解,总的loss如下:
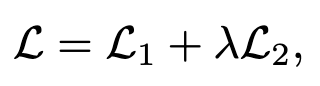
优化:
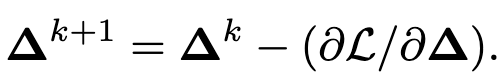
投毒
对普通视频帧(标签为$y_\tau$)进行投毒(增加扰动$\eta$),其loss:
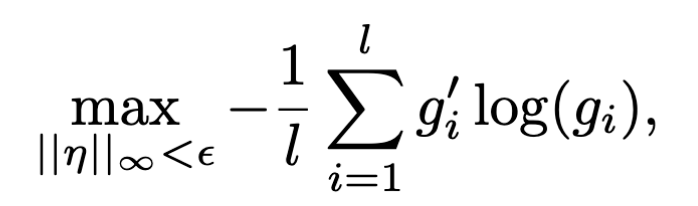
符号表示:
- $||.||{\infty}$:$L{inf}$距离
- $\eta$:扰动
- $g^{‘}$:样本X的标签
- $g=F_A(X+\eta)$:$X+\eta$通过模型$F_A$之后得到的$y_{pred}$
- $\epsilon$:允许的扰动的最大值,相当于边界
给出L-inf距离的表达式:
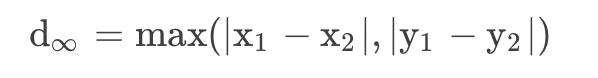
另外,作者对普通帧(标签不是$y_\tau$)和加了扰动的帧(标签为$y_\tau$)执行了滚动操作($\mathcal R$)
距离
L1
适用场景:当数据中存在少量重要特征,而其他特征对于任务影响较小时,可以使用L1范数,因为它有稀疏性,能够将一些不重要的特征的权重降为零,从而实现特征选择。
如果数据是稀疏的,或者有很多离群点,那么L1距离可能更合适,因为它对异常值不敏感,而且可以产生稀疏解。
$$
d_1(X,Y)=\sum|x_i-y_i|
$$L2
适用场景:L2在损失函数中常用于平衡各个特征的影响,并有助于防止过拟合。L2范数对异常值相对较为敏感。
如果数据是密集的,或者需要保持距离的平方关系,那么L2距离可能更合适,因为它对异常值敏感,而且可以保留更多的信息。
$$
d_2(X,Y)=\sum\sqrt {(x_i-y_i)^2}
$$L-inf
适用场景:当你更关心特征中的最大值对于整体影响时,可以使用L∞范数。它对异常值非常敏感,因为它只关注最大的绝对值,因此对于探测和处理异常值很有用。
如果数据的特征有不同的尺度或单位,那么L-inf距离可能更合适,因为它只关注最大的差异,而不受其他特征的影响。
$$
d_\infty=\max (|x_i-y_i|)
$$
