
标题
基于注意力的体验质量感知逃避后门攻击。
摘要
本文创新点:
- 基于注意力的逃避后门攻击
- 在生成trigger的loss函数里增加QoE(quality of experience,质量经验)
问题范围和威胁模型
范围:集中式场景
威胁模型:和以前的一样,这里作者特意引用了三个文献,表示和他们文章中使用的威胁模型是一样的:攻击者可以通过训练数据集训练出后门模型,然后给客户,或者分发在网上。

后门攻击架构
两个组件:触发器生成+后门注入。
触发器生成
关键在于找到触发器样本和误分类标签之间的桥梁–模型中的神经元。需要找到某一合适的layer中的某些神经元。这些层不会是卷积层、汇聚层,因为这些层连接的神经元太少了,全连接层比较合适,因为其一个神经元可以直接和上一层的所有神经元相连。本文选择第一个全连接层作为合适的layer。
找到layer后,需要找到合适的神经元,能够很好的连接触发器样本以及目标标签。思路是:选取激活最大的神经元(当输入样本的标签为目标标签$y_t$时)
触发器的优化方法:通过最大化选定神经元的激活,梯度下降,来得到触发器$\delta$。
通过普通样本$(x,y)$构建中毒样本(触发器):$x_t=x\otimes (1-M)+\delta \otimes M$,从而得到触发器样本$(x_t,y_t)$,$y_t$为目标标签。
优化表达式如下:
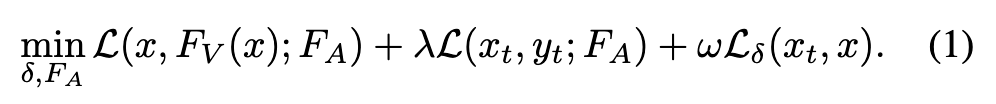
- 第一项保证模型在干净数据上的正确率
- 第二项和第三项保证中毒的成功率
但是上式中$\delta, F_A$是两个依赖的参数,不好优化,因此将其拆分成两个步骤,先优化$\delta$,再优化$F_A$:
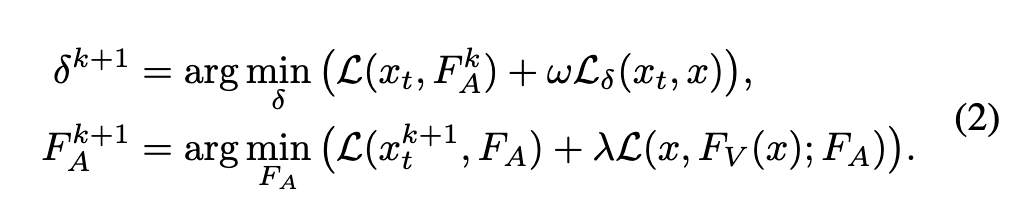
基于注意力的掩码的确定
在生成触发器去激活神经元之前,需要先生成触发器掩码,用来限制触发器的形状、大小、位置等。掩码通常是一个元素为0/1的矩阵,0代表没有触发器的区域,1代表有触发器的区域。
现有的后门攻击中的触发器都是像素空间可感知的形状,如三角形、logo()、水印,触发器的位置通常也是上下左右的角落里。通常,触发器越大,攻击成功的概率越高,被发现的可能性也就越大。所以就只能把触发器尽可能往小了做,这样就会导致触发器的效果被限制。
拿(图片)分类模型举例,性能良好、结构不同的分类模型往往都会关注同样的关键特征,对那些重要性很高的像素进行人为操作更有可能会翻转分类结果,也就是达到误分类的效果。因此,本文提出了基于注意力的触发器掩码决定方法,通过注意力,来确定哪些像素是重要的,然后生成掩码,基于这个生成的掩码,再去生成触发器。
本文使用RAN(残差注意力网络,CVPR2017)来生成注意力映射,得到注意力,确定每个像素的重要程度。
RAN中有很多注意力模块,每一个模块由主分支T和掩码分支S组成,主分支来处理神经网络中的特征,而软掩码分支则是模拟人的大脑回路,来选择特征,RAN第l层的输出为:
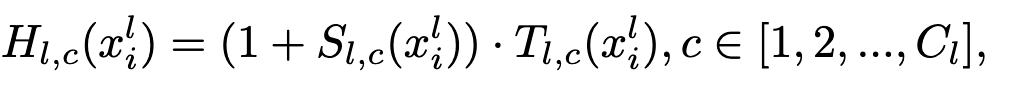
也就是说说主干分支负责处理,掩码分支来进行选择。
另外,RAN里不同的注意力模块有不同的作用,低层的注意力模块减少不重要的特征的影响,高层次的注意力模块挑选出重要的特征来提高分类成功率。最后一层的输出就是注意力了–像素注意力权重,它反映的是:像素将预测结果导向每一类的贡献。
有一个问题是,RAN输入一张图片,输出的注意力映射可能跟输入尺寸不同($32\times 32\to8\times 8$),这里作者采用双线性插值来对注意力映射进行升阶。升阶后的注意力映射表示为$H(x_i)$
随机选取N个标签为$y_t$的样本,然后生成注意力映射,将N个样本中离平均注意力映射最近(L2 distance)的作为最优、最通用的注意力映射。
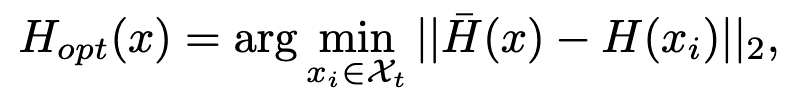
基于QoE的触发器生成
上面的模型独立的后门生成方法已经能够达到很高的成功率了,但是这样生成的后门可能太明显了,并且很容易被肉眼识别出来。因此需要使触发器具有不可见性。
于是作者考虑将一种QoE的方法SSIM加入到loss里面去,来增加后门的不可见性。
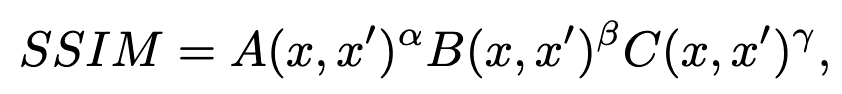
QoE是体验质量,SSIM为结构相似指数测量。SSIM可以量化原始图片和被打乱了的图片的差异(亮度、对比、结构),上式中的ABC分别表示的就是亮度差异、对比度差异、结构差异。
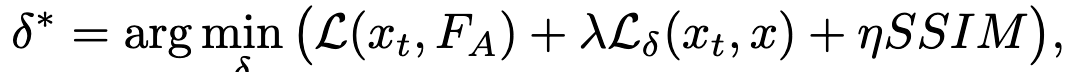
然后将SSIM引入到loss里面去。$\eta$用来平衡成功率和隐蔽性。
交替再训练
传统方法是:利用干净数据和触发器数据重新训练模型。但是实验表明,这样做就算只有0.3%的投毒率,干净样本的正确率也会掉7.82%(这里是和作者自己提出的模型进行对比,而不是没有投毒的实验,也比较有说服力)。客户可能会因为模型的正确率低而选择拒绝使用这个模型。此外,中毒样本可能已经对决策边界造成了扭曲,这可能会导致模型会被现有的检测方法检测出(例如元分类器[60])
作者使用的方法:迭代次数k,当k为偶数时,同时用干净数据和触发器数据训练模型;否则,就用干净数据来训练数据。 经过实验验证有效。
问题
- RAN:残差注意力网络
- QoE:SSIM,一种衡量体验质量的指标。
