
摘要
提出的框架NAD(Neural Attention Distillation,神经注意力蒸馏):在一小部分干净数据集上,用一个老师模型来对学生模型进行微调,老师模型可以从学生模型中得到,最终我们需要的就是经过微调后的学生模型。
实验效果:通过5%的干净数据集,在不对模型性能(在干净数据上)造成明显下降的情况下,能够清除后门
提出的方法
吐槽:这有必要用一个节标题吗。。

在带有后门的NN中,有些神经元会对带有后门模式的representation响应,而良性的神经元只会响应有意义的representation。NAD就是优化那些会对后门模式响应的神经元。最主要的问题是:怎么区分representation?
符号表示:
$F^l$:第l层的激活函数的输出结果
$\mathcal A$:注意力映射,将3维的激活函数输出转换为2维的注意力。
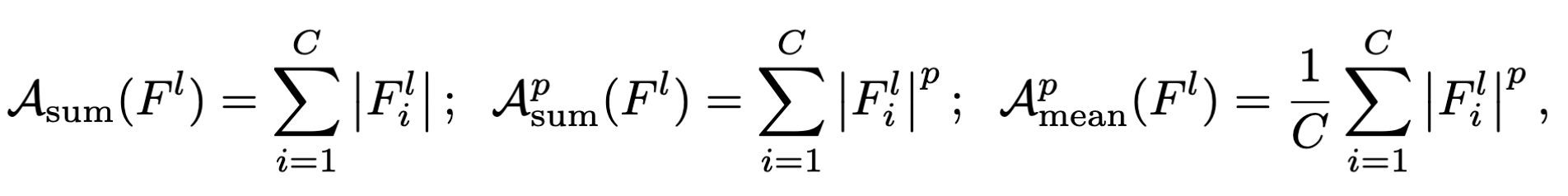
下面对这几个映射函数做区分:
- $\mathcal A_{sum}$:同时考虑了良性神经元和后门神经元
- $\mathcal A_{sum}^p$:通过p次方,放大了良性神经元和后门神经元的差值
- $\mathcal A_{mean}^p$:对良性神经元以及后门神经元的输出取均值
拿ResNet举例,在每一个残差块之后,增加一个注意力函数,来计算注意力。
回到我们的NAD,NAD loss可以表示为下面的式子:
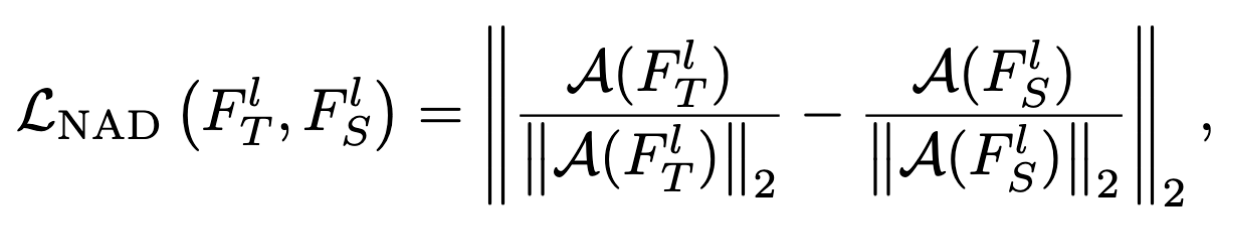
整个的loss表达式如下:
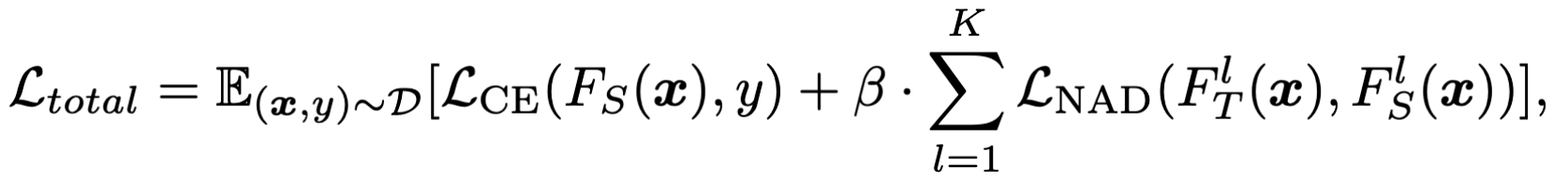 、
、
符号表示:
- $\mathcal L_{CE}(.)$:使用CE来优化学生模型分类的准确率
- $\mathcal D$:一小部分干净的数据集
- $\beta$:超参数,控制注意力蒸馏
- $l$:第l个残差块
老师模型是通过学生模型在相同的干净数据集上微调得来的,具体怎么做需要看实验部分。
