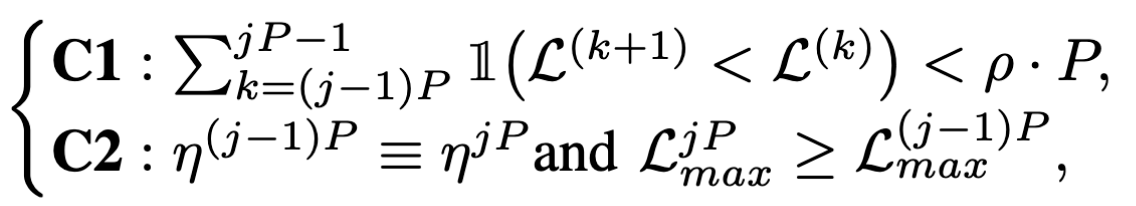摘要
后门攻击与中毒攻击不同,后门可以被植入模型中,当特定数据被输入到模型中后,后门触发,能够有目标或者无目标的误导模型的分类。
先踩了一波[69],东北大学的一篇文章,提出了很多净化方法,试图除掉后门;但是,这些方法既没有降低攻击的成功率(在一些先进的攻击方法上),或者,就是降低了模型在干净数据上的成功率。
本文提工作:
- SAGE,利用自监督蒸馏来除掉模型中的后门。自监督蒸馏的意思就是不需要老师(模型)来监督蒸馏过程。自监督蒸馏只需要一小部分干净数据。
- 动态学习率调整策略
实验:6个最优方法、8个后门攻击、4个数据集
实验效果:最多减少90%的攻击成功率,仅仅需要最多3%的干净数据集上的损耗。
背景
这章对已有的工作做了一些分析与总结,记录一部分。
后门攻击
作者用了小半页篇幅来介绍DNN的定义、发展,然后由于训练时间以及金钱成本高(GPT-3)、数据集的构建困难(ImageNet),许多用户选择将模型放在云服务器上跑,或者是使用预训练好的模型(e.g., Caffe Model Zoo2)。然后以此引出后门攻击:攻击训练数据集或者是训练阶段。
带有后门的模型在预测时,对于干净的样本,能够正确的预测;然而对于被贴上了目标错误标签(target false label) or 任意错误标签的样本(any false label)(二者分别对应目标攻击和无差别攻击),则是分类错误的。然后作者对已有的工作做了一些分类:

后门防御
检测
后门输入检测
- [14]:通过将可疑的输入数据复制几份,然后用其他的样本作为扰动(针对后门)增加进去,最终都 拿来做预测,通过这个集中的预测,进行对比,可以找到target的后门攻击
- [9]:找出对预测结果影响最大的样本区域,然后混合其他样本一起训练,若是有很多批次的样本都被错误分类成了相同的错误标签,那么后门很可能在这个样本区域中。
- [5]:直觉是,最后一个隐藏层的激活函数输出的是高维特征,那么基于此,检查一批数据通过最后一层激活函数,能否被分为两类,来判断这一批中是否有后门。
后门模型检测
[6]:利用反向工程试图恢复出训练样本
[65]:利用jumbo learning训练出一个元分类器,来判断模型是否被植入后门。这个分类器可以对多种后门模型进行分类。
净化
和检测的方法比较类似其实。
输入净化
[12]:和[9]有点类似,找到对模型预测影响最重要的区域,最终的目的是找到并移除可能的后门,然后回复出训练数据。
[53]:通过GAN恢复数据,区域被描述为带颜色的盒子。
模型净化
[37]提出的下面两种方法(纽约大学的成果,或许可以看看)
- 模型修剪:直觉是,被影响的神经元对干净样本几乎不激活,只有后门样本进来时才激活,把这类神经元剪掉。
- 微调:用干净数据不停对模型进行微调。
还有利用反向工程来移除后门的方法([59], [69]…)。
[32]利用注意力蒸馏的方法,通过微调模型为老师模型,然后通过注意力蒸馏的方法进行组合。问题是,老师模型就算通过了一些微调,还有可能存在后门。
知识蒸馏和注意力蒸馏
知识蒸馏:通过模仿一个很大的老师模型的中间层以及比较深的层,来得到一个学生模型。首次被Hinton[21]提出。
注意力蒸馏就是将注意力机制添加到知识蒸馏中,让学生模型能够学到更高质量的深层表征。常见的做法有基于激活函数的注意力蒸馏、基于梯度的注意力蒸馏。
[22]提出了一种自注意力蒸馏,这种方法不需要老师模型。
威胁模型
对攻击者和防御者的知识做一个假设。
防御者
假设防御者从一个不受信任的第三方得到了一个带有后门的模型。
防御者有一小部分干净的数据集,这个数据集远小于整个训练集。
目标:通过这一小部分干净数据集将后门擦除。
攻击者
本文考虑的攻击者比较强,攻击者能够知道所有的模型内部信息以及训练数据集。因此攻击者可以制造更强力的、自适应的后门。
SAGE
设计原理
研究表明NN的浅层提取的是全局结构信息(宏观特征),而深层则是提取的细粒度细节(微观特征)。因此后门即为微观扰动,作用于深层而不是浅层。
[32]使用微调后的老师模型,让学生模型的良好浅层从老师模型的良好浅层中学习,然后学生模型中的深层从教师模型中的深层学习。但问题是,就算教师模型经过微调,其深层后门不一定被擦除,也就是说学生模型最终得到的模型可能还是带有后门。
作为对比,本文中使用的是自注意力蒸馏,让学生模型的深层从好的浅层学习,从而摆脱老师模型。有下面几个比较重要的模块:
- 注意力表示模块:根据神经元对最终预测结果的重要性,来提取出注意力
- 损失计算模块:根据浅层的注意力,对深层的权重进行调整,同时保证模型预测的准确率。
- 学习率更新模块:跟踪模型在干净数据集上的准确率,来自适应调整学习率。([32]是每过两个epoch,学习率除10)
PS:本片文章很可能是作者在[32]的基础上做的:近期,网络与信息安全学院吕锡香教授指导的博士生李一戈的论文「Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks」,被人工智能顶级会议ICLR 2021收录,在ICLR 2021会议近3000篇投稿中,均分排名前7.5%。这项研究成果由西电网信院、蚂蚁集团、迪肯大学、墨尔本大学和UIUC合作完成。
注意力表示
符号表示:
- $F_B$: 带有后门的模型
- $F_B^l$: l层激活函数的输出, $\epsilon R^{C_l\times H_l\times W_l}$
- $\mathcal G:R^{C_l\times H_l\times W_l}\to R^{H_l\times W_l}$: 映射函数,由激活函数输出得到注意力
映射函数可从下面四个函数中选取:
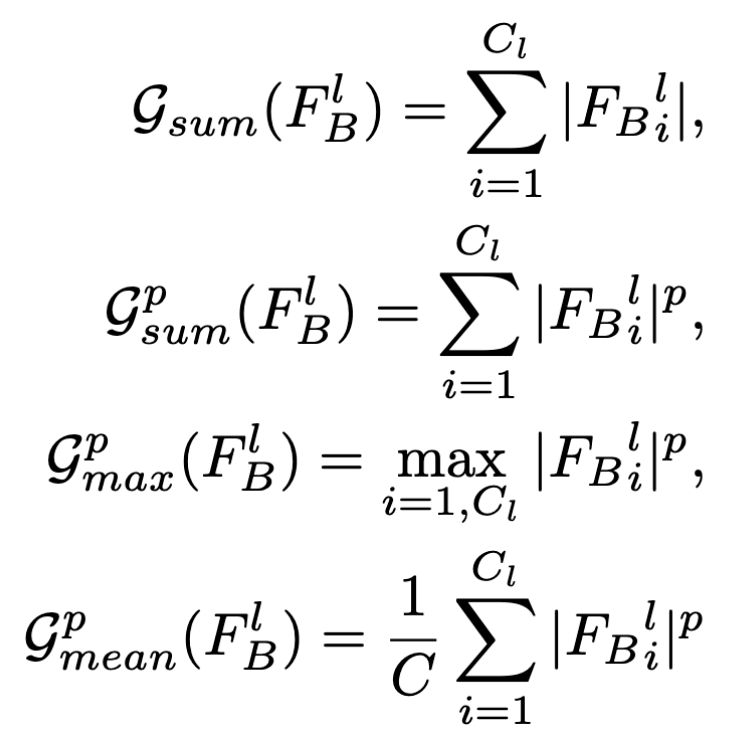
损失计算
所谓自监督蒸馏(Self-Attention Distillation),核心是利用好上面的注意力映射(浅层),作为深层的监督信息。(想法就是,浅层不会有后门,后门只会在深层中,作用于细粒度特征,所以intuition是用浅层的信息来监督深层)
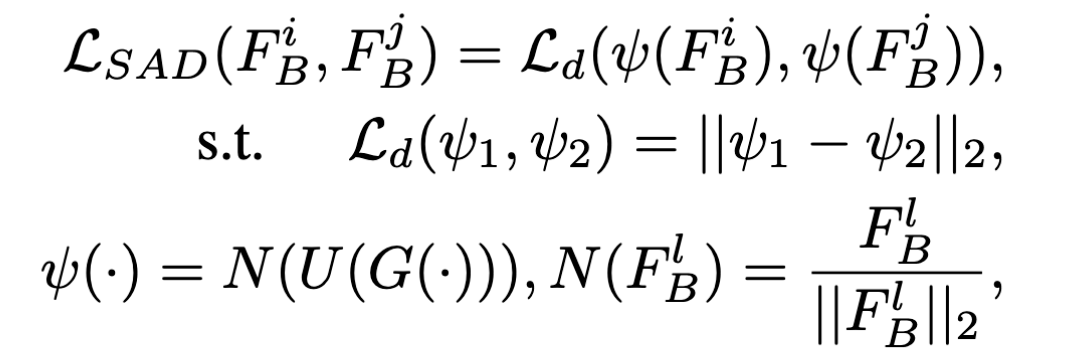
SAD的目标是尽量减小不同层之间的attention map的差异,然而这并没有考虑到对正确率的影响,也就是说很可能最后经过自注意力蒸馏后,对正确样本的预测率会大大下降,因此选用下式作为最终的loss func.
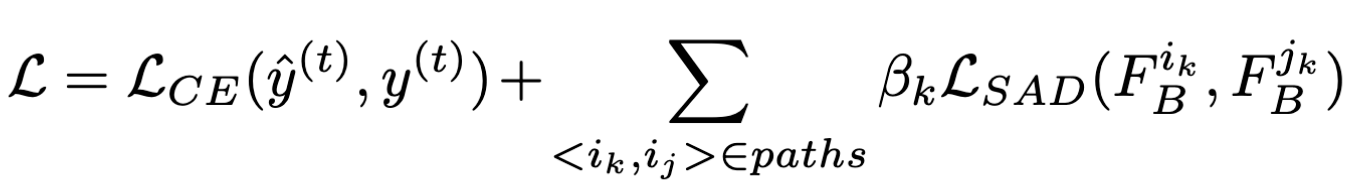
学习率更新
本文提出的一种学习率更新的方法,设定了两个条件:$\mathcal C_1,\mathcal C_2$:
- $\mathcal C_1$: 当在干净数据上的loss在n个epoch内都没有下降
- $\mathcal C_2$: 在干净数据上的loss最大值没有下降
若是上面条件有一个发生,那么就将学习率除2。