
摘要
现有的问题:攻击者通过精心制造中毒数据,可以影响DNN的性能。特别的,在车联网领域,攻击者可以误导交通标志识别系统,使得系统将某一类标志识别错误(针对性攻击),或者是单纯的影响模型的性能(非针对性攻击)。
本文的工作是:调查了性能最优的集中攻击方法,和针对自动驾驶的防御方法
根据是否攻击者是否参与数据标注过程,将攻击方式分为:脏标签(dirty-label)攻击和干净标签(clean-label)攻击
将防御方法也分为两类,分类标准是是否需要修改模型(model-based defence method)或者是修改数据(data-based defence method)
作者不仅是做了调查,还对这些攻击或者防御做了实验来进行对比。
此外,作者给出了未来可能的方向:车联网中的数据中毒或者防御。
介绍
介绍中简单介绍了自动驾驶的发展,然后介绍数据中毒攻击对联邦学习和物联网的影响非常大,然后引到自动驾驶(自动驾驶训练过程就是一个分布式联邦学习,而自动驾驶的各种部件、传感器都是物联网设备或者嵌入式设备)。在自动驾驶的训练过程中,有两个阶段都可以进行投毒:
- 最开始的训练阶段。最开始数据集来源于各个车主的数据,而我们无法很容易的判断出这些数据是否有恶意,是否为干净数据。
- 后续的更新阶段。经过最初的训练之后,模型已经可以很好的推断了,但还是需要后续的一些补充当前模型,也就是进行更新,以泛化新的数据。也就是说还是需要收集训练样本。
1 | Q:从这里可以否定我的一个想法:自动驾驶模型训练完之后,这个方向是否就已经通关了呢? |
下一段简单介绍了典型的攻击方法(眼熟的只有MetaPoison),然后是防御方法(眼熟的是数据消毒)。
前言
车联网框架
介绍了一下车联网是什么,然后举的例子还是交通标志识别系统,通过摄像头采集到的图片,然后丢到系统里面去,这个输出的结果是会影响智能汽车做决策的。
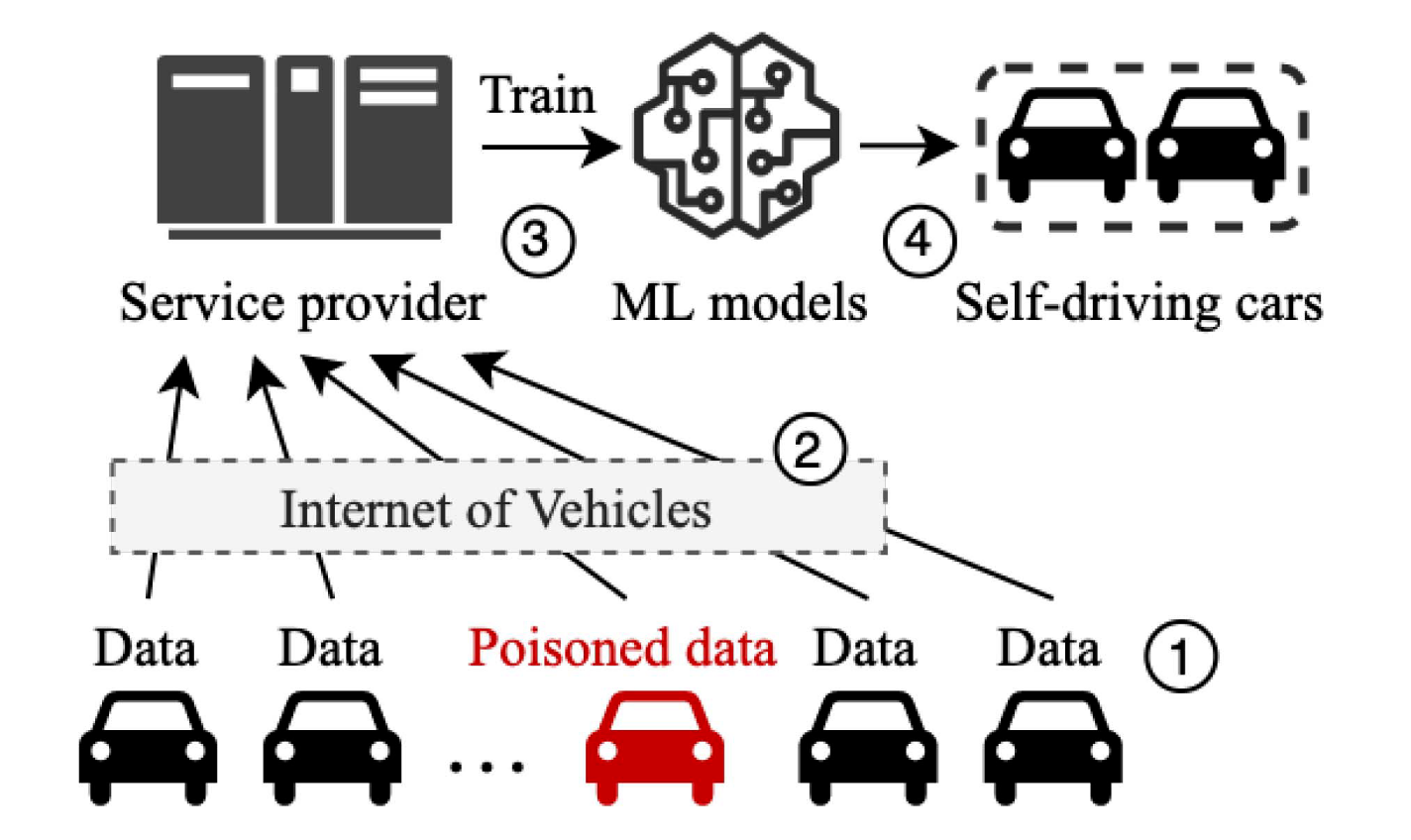
举个例子,数据由汽车公司给到服务提供商(WHUT),然后提供商训练好NN model,最终把这个给到汽车公司。
中毒攻击
作者还是以交通标志分类系统举例子,来解释什么是干净标签攻击和脏标签攻击。
clean-label
攻击者不影响打标签,而是影响中毒数据。例如给目标数据添加扰动。
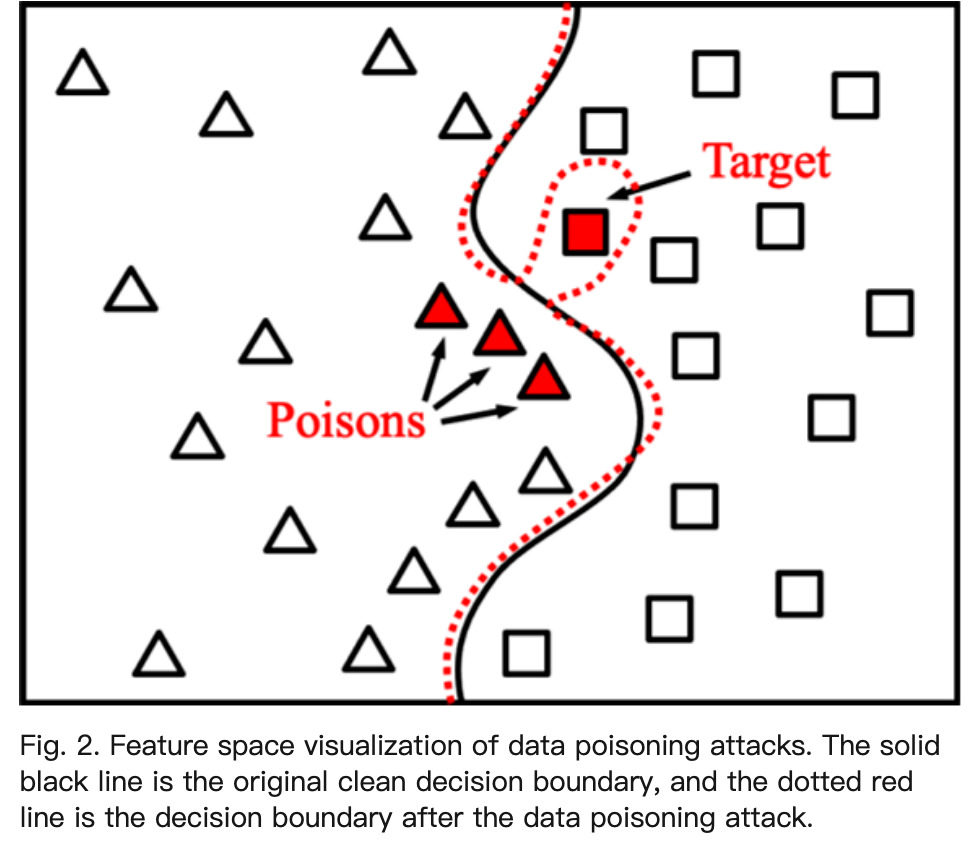
文章中有句很好的话来解释这个过程:the attacker optimized the poison such that it looks like a normal “speed limit 80” traffic sign (base), but is similar to the stop sign (target) in feature space. the decision boundary in the feature space will be distorted.
最后在推断阶段,将停止标志识别成了限速80(不需要停止!)

dirty-label
攻击者可以直接参与打标签的环节。例如直接修改”停止“样本的标签为”限速80“
最后作者特别说了MetaPoison,仅仅注射1%的有害样本就可以有70%的成功率攻击成功。
然后本文调查的主要是迁移学习和端到端学习。
最优的数据中毒攻击
攻击方法
作者指出非指向性攻击,又称无差别攻击,是一种传统的攻击方法,这种方法很容易被检测出来,因为它使全局的准确率都降低了;更好的是指向性攻击,只降低某一类的准确率,基本不影响全局的准确率。
因此本文讨论的是指向性攻击。
dirty-label attack
原文中是这样描述的:changes the decision boundary in the feature space by poisoning the samples near the target
直接改变数据的标签成攻击者想要的类型,等于是直接改变了决策边界。
这里讲的方法不是很多,然后也没了解过,先不阅读。
clean-label attack
clean-label attack就是注射中毒数据,但是数据的标签是干净的,是在数据本身上加了扰动。
这里讲的方法很多,可能用clean-label做还是更符合现实一点。
最优的防御方法
防御方法
根据防御是针对数据还是模型,分为基于数据的防御和基于模型的防御。
data-based:在数据收集阶段对收集到的数据进行检测,来检测数据是否被投毒
主要的方法就是数据消毒。数据中毒是找出训练数据在整个特征空间的特征分布,然后利用这个分布来剔除有害数据,不需要对模型进行操作,是一种完全基于数据的方法。
model-based:在模型训练阶段来检测。
基于模型的方法是在训练阶段,会附加一些额外步骤,通过模型的准确率和参数变化,来判断是否有中毒数据。
data-based和model-based方法并不冲突,有时会串联在一起用。原因是:某些精巧的攻击方法,可能会绕过data-based method,同时例如在自动驾驶中,数据的分布突然变化的特别大,这时有可能将正常数据误判为中毒数据。
因此可能model-based方法更加通用一点。
