
abstract
develop an advanced model poisoning attack against defensive aggregation rules
2 components/features:
rank the priority of models weights to find whose influence is bigger. Then we do poisoning attack to the it.
Basically, it is better than average poisoning attack to all weights.
Smoothing the malicious model update.
Real-world FL framework(PLATO) experiment.
problem formulation
Threat model
some assumptions about attacker:
Knowledge:
- the compromised client’s local dataset
- if one of the compromised client is chosen by server, then the attacker can access to the current global model.
- Don’t know the server’s aggregate rules.
- Don’t know anything about benign clients
capability:
can manipulate all compromised clients together.
Goal::
untargeted poisoning, which means the attacker aims to degrade the performance of global model.
problem formula
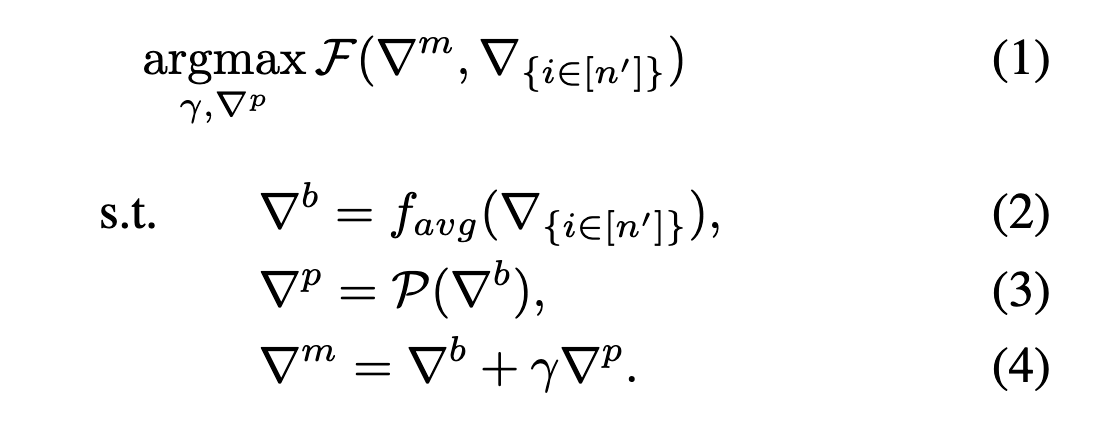
- $\bigtriangledown ^b$: the attacker don’t know the benign clients, so we use the global model weights and compromised clients locan dataset to train and estimate $\bigtriangledown ^b$.
- $\mathcal P$: the pertubation function
- $\bigtriangledown ^p$: the malicious perturbation based on $\bigtriangledown ^b$
- $\gamma$: the scale factor to adjust attack performance. It should’nt be too large and this is to avoid the server discards the poisoning model update.
our object is to fine-tune factor $\gamma$ and find function $\mathcal P$
then max. the loss $\mathcal F$
detailed construction
Design Rationale
to enhance the performance.
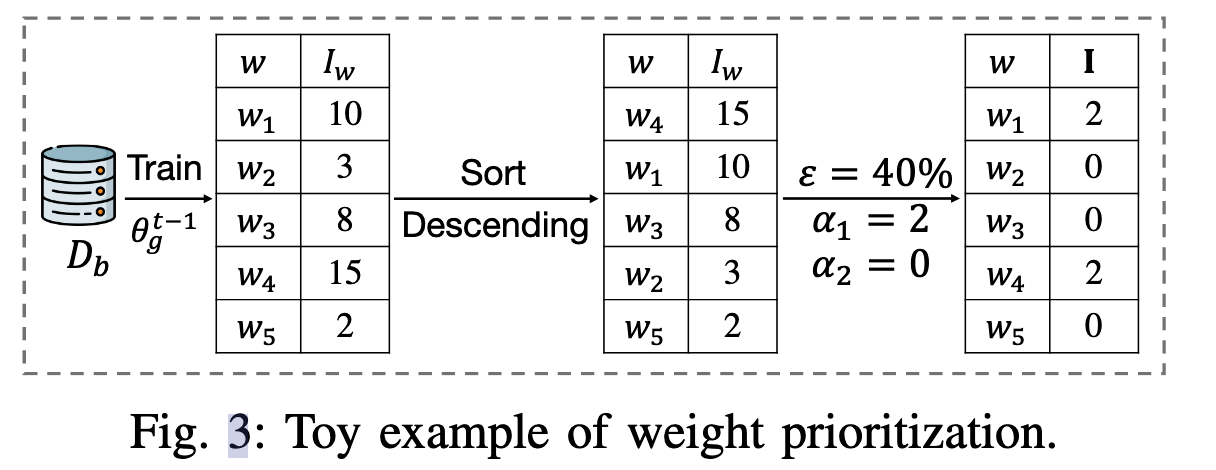
Weight prioritization
exploit the catastrophic forgetting: this means when a system learns new knowledge, it will forget what it has learned in the past.
To NN model, it is same. Based on this, we choose to poisoning attack the most important weight
dynamic smoothing
incorporates the history of benign model updates in calculating malicious model updates in the current round.
Weight prioritization
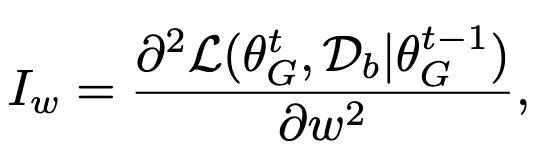
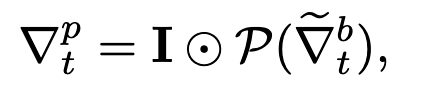
The $\bigodot$ means Hadamard product, for example:
$$
[1,2,3]\bigodot [3,4,5]=[3, 8, 15]
$$
dynamic smoothing
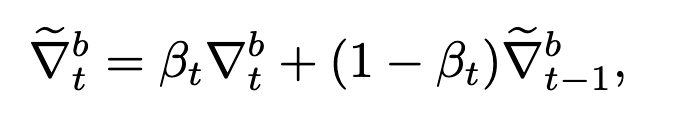
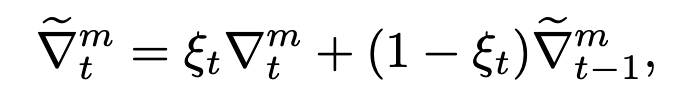
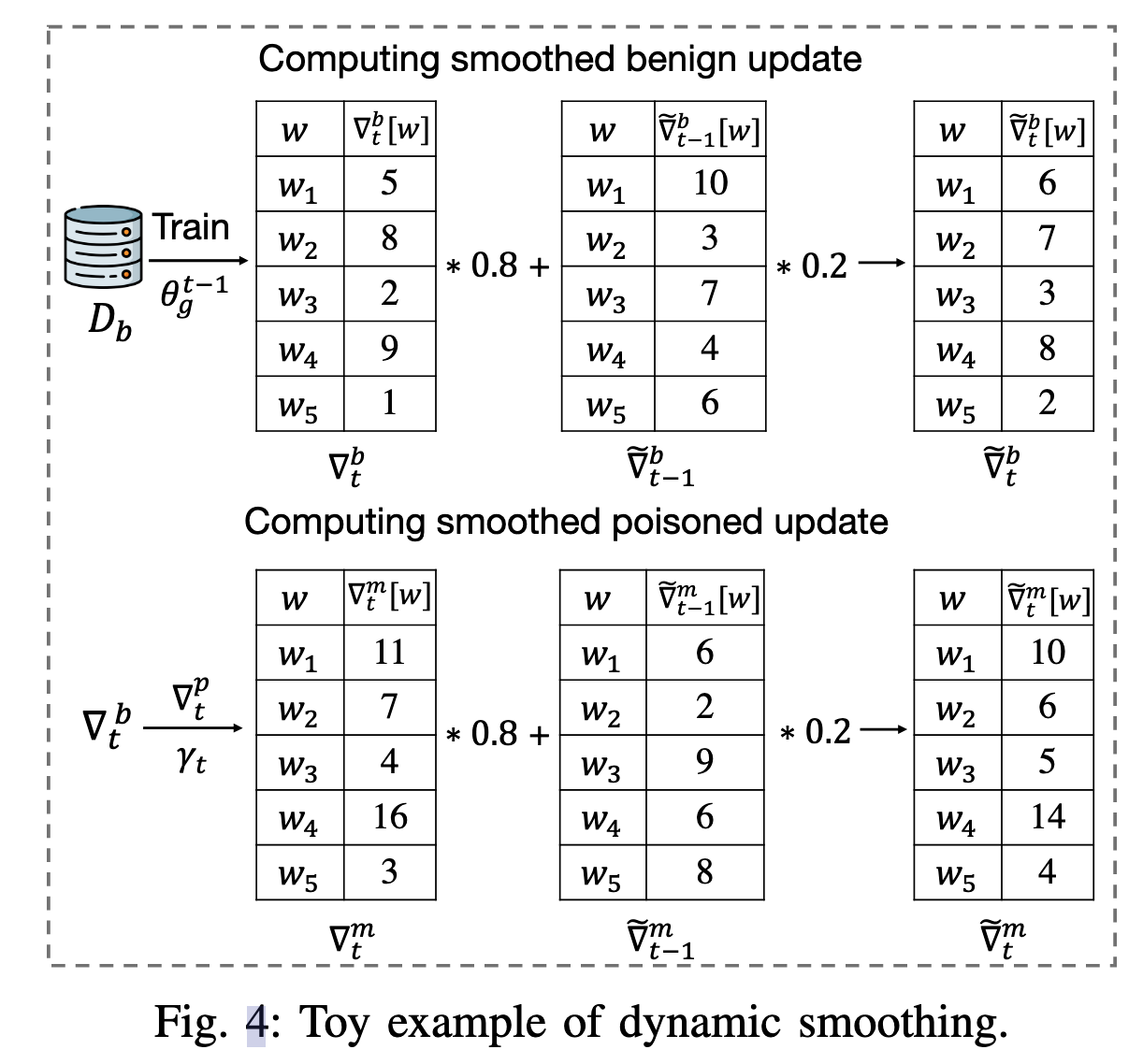
algorithm

补充一下第二部分的内容,以便做实验
PRELIMINARIES AND RELATED WORK
Federated Learning
联邦学习可以 表示为如下几个过程:
初始化
如果是第一轮,那么服务器需要初始化参数,然后从客户端集合中选出一个子集,对子集分发模型参数。
客户端本地训练
本地客户端i拿到权重之后,在本地的数据集上进行优化,然后上传权重更新给服务器即可:$\bigtriangledown _i^t=\theta _i^t-\theta_G^{t-1}$
服务器聚合更新
$\bigtriangledown G^t=f{agr} ({\bigtriangledown _i^t})$
$\theta _G^t=\theta_G^{t-1}+\eta \bigtriangledown _G^t$
本地训练+服务器聚合这个操作对一直进行,直到模型收敛|到达最大轮数
Model Poisoning Attacks in Federated Learning
前面简答介绍了指向性和非指向性攻击,前者影响某一特定类别的准确率,后者是直接影响整个模型的性能。然后本文选取的是非指向性攻击。
根据攻击者的认知,可以将非指向性攻击分为:AGR-tailored attacks和AGR-agnostic attacks:
AGR-tailored attacks
假设攻击者知道服务器的聚合规则,那样攻击者就可以根据这个聚合规则来制定策略。
AGR-agnostic attacks
攻击者不知道服务器的聚合规则,这种情况更符合实际,因此考虑这种攻击能够使得我们的模型更加通用。
下面是一些符号表示:
- $\bigtriangledown ^m$:表示恶意客户端的更新
- $\bigtriangledown ^b$:表示正常客户端的更新,事实上攻击者不知道其他的干净客户端的数据集,所以攻击者只能用自己的恶意客户端的数据集来代替干净客户端的数据集。
- $\bigtriangledown ^p$:对正常的更新增加的扰动
下面是三种最流行的AGR-agnostic attacks:
LIE [16]
LIE假设所有良性客户端的更新服从一个在$\bigtriangledown ^b$周围的分布,对攻击者而言,支持者标记为$\bigtriangledown ^+$,反对者标记为$\bigtriangledown ^-$,恶意更新将会被制造在$\bigtriangledown ^b$和$\bigtriangledown ^+$之间,从而误导服务器将$\bigtriangledown ^-$识别为异常值。
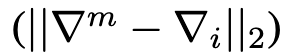 限制在
限制在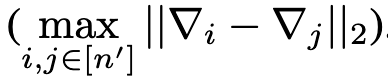
Min-Max [12]
有三个不同的扰动函来优化攻击性能。目标是:找到最边缘的的$\gamma$,使得恶意更新和良性更新的最大距离和良性更新之间的最大距离一样。
Min-Sum [12]
和Min-Max比较类似,但是多了平方:
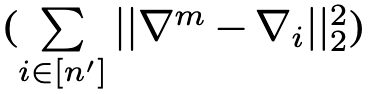 限制在
限制在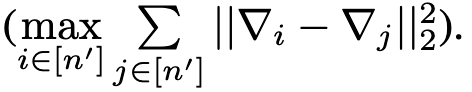
experience
experience setup
三个数据集:FEMINIST, CIFAR-10, Purchase
FEMINIST
灰度、字符数据集:由3400用户书写的,一共有805263张28*28的灰度图。
作者选用LeNet5作为全局模型,客户端有3400个
CIFAR-10
一个类别平衡的图像数据集,有10类,共60000张32*32的图片。
作者选50000作为训练,10000作为测试,客户端500个,使用的模型是VGG11。
Purchase
一个类别不平衡的数据集,用来对顾客进行分类,有100类,共197324个二进制特征向量。
作者用钱18000作为训练,考虑1000个客户端,使用的模型是MLP(600,1024,512,256,100)
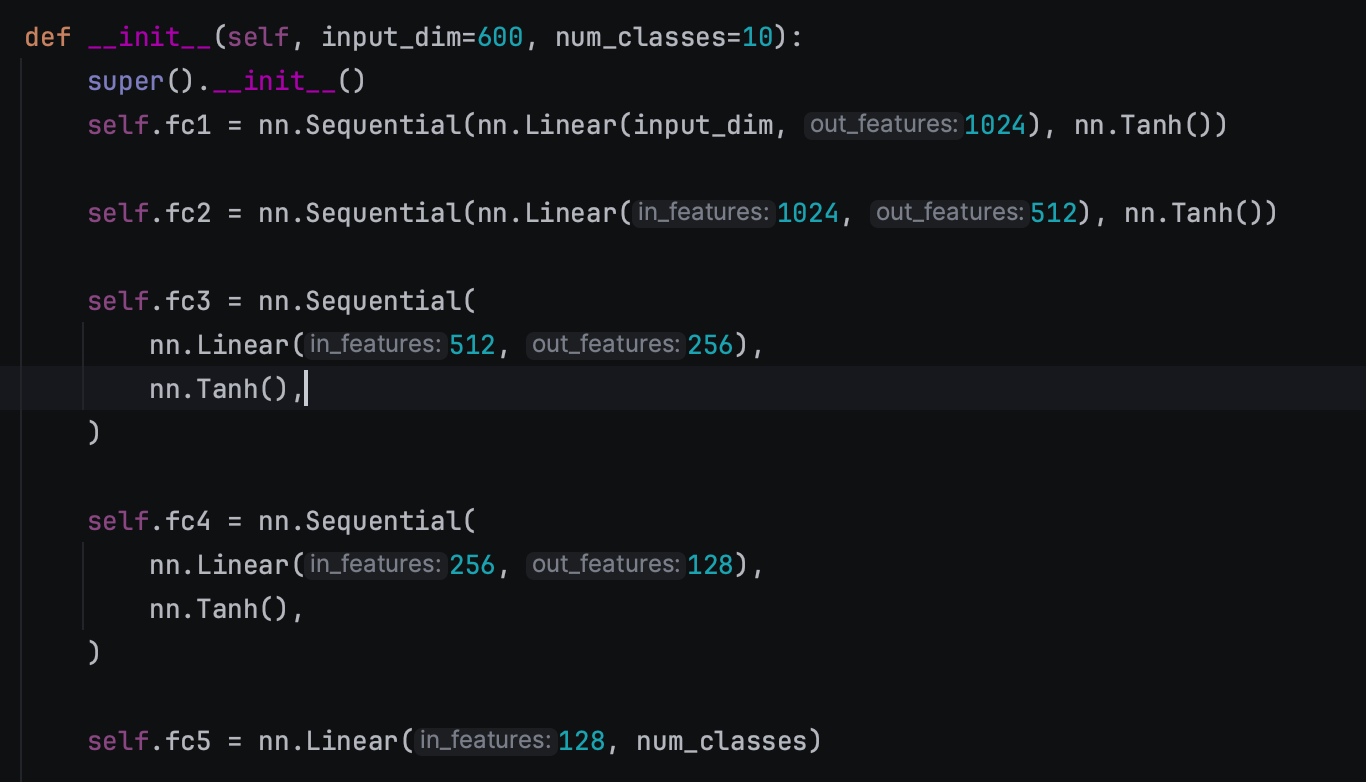
下面是模型参数的设置:
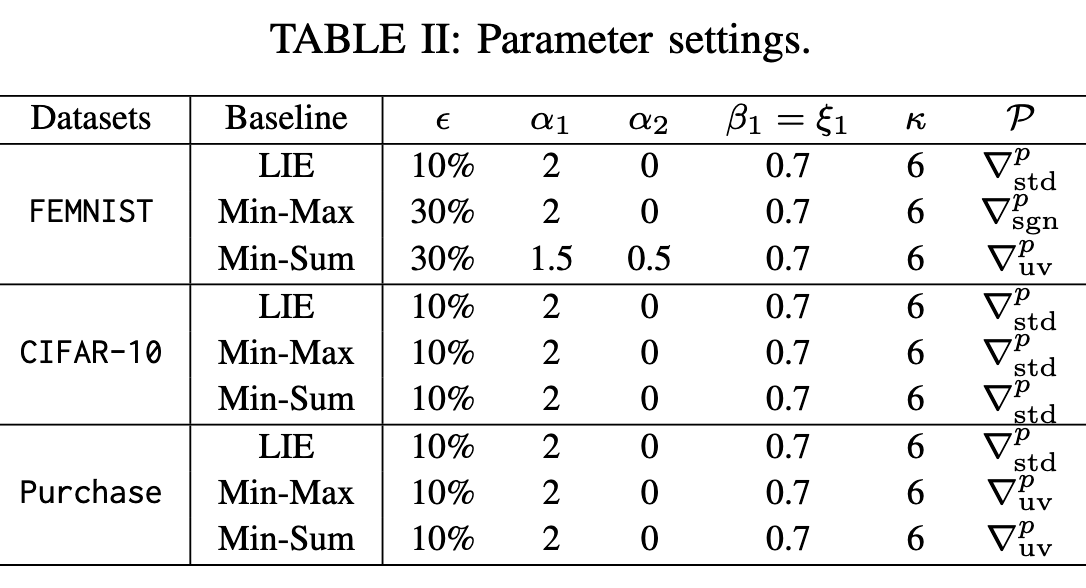
参数解释:
- $\epsilon$:选取前多少作为高优先级,其余设置为低优先级
- $\beta _1$:$\bigtriangledown ^b$的动态平滑因子
- $\xi$:$\bigtriangledown ^m$的动态平滑因子
- $\mathcal P$:扰动函数
- $\mathcal k$:阈值,用来判断被选中的恶意客户端是否超过该值
对于服务器的聚合规则设置,本文作者选了6种:non-defensive 聚合规则、FEDAVG,以及下面4种:
- MULTI-KRUM [4]
- TRIMMED-MEAN [5]
- MEDIAN [5]
- AFA [8]
作者选取的联邦学习的框架是PLATO,训练200轮,每轮服务器会随机选取30个客户端进行本地训练,batchsize是10,lr是0.05,每次本地训练训练一轮,假设有百分之20的客户端是恶意客户端。
PS:拿Purchase数据集举例子,一共有1000个客户端,然后百分之20%是恶意客户端,那么就有200个恶意客户端,一次选取30个客户端用来本地训练。还算合理的范围,对攻击者来说也还是有攻击难度。
下面是实验效果:
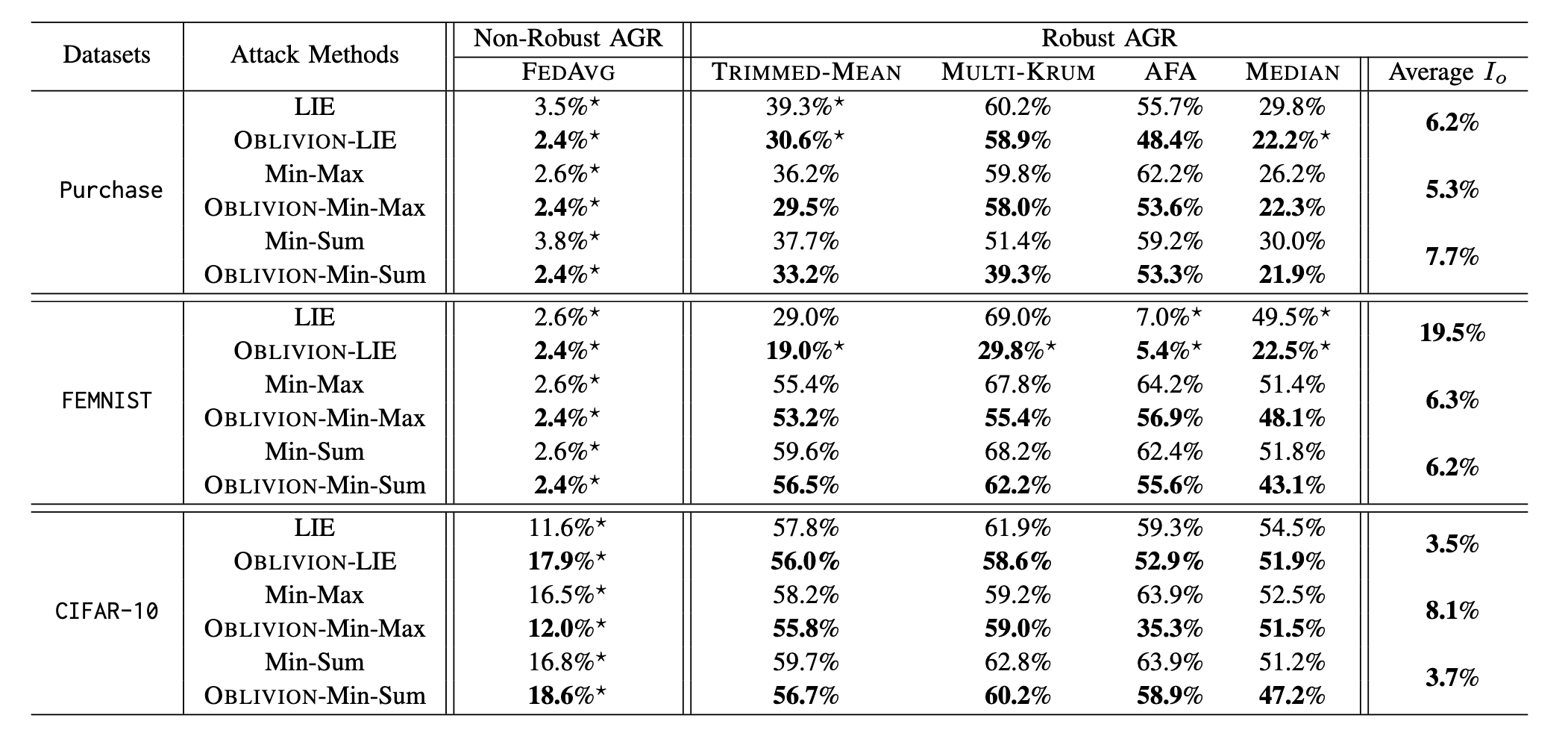
可以看到,在加入OBIVION攻击后,模型的性能或多或少有了下降。
minmax_attack
minmax是后续攻击的基础,因此从minmax入手:
从更新中取出权重变化,即为deltas_received,有30个客户端,deltas_received的长度就是30,有30个delta_received
统计;攻击者的数量(id小于100的)、模型每层的名字
将所有的更新拼接,all_updates,shape为[30, 9236626]。30指的是30个被选中的客户端,9236626是每个客户端每一层的参数首先view(-1)然后concat后的结果。
将attacker的更新拼接,得到的是attacker_grads,shape为[6, 9236626],方法和上面的是一样的
将attacker_grads沿着维度0取平均,得到model_re,shape为[9236626]
根据偏差类型,得出偏差deviation(单位向量、符号、标准差……)
设置$\lambda=\lambda _{fail}=50,\lambda _{success}=0$,$\lambda$是最后的偏差系数
1
mal_update = (model_re - lamda_succ * deviation)
计算每个攻击者的攻击更新和attacker_grads的distance,然后取出最大距离max_distance
先计算恶意更新mal_update,然后计算所有更新all_updates和mal_update的L2距离distance,同样是取出最大值,计作max_d,将max_d和max_distance进行对比,来更新$\lambda$,直到$\lambda _{success}$和$\lambda$的差值小于阈值,得到最终的恶意更新。
通过renew_malicious_updates更新恶意更新。
