
abstract
现有的攻击主要都是手工制作的攻击,为什么让机器去做呢?因为这通常是一个bilevel optimization(双层优化)问题,这对于深度模型来说是不好求解的。
提出的攻击:MetaPoison。通过first- order method(一阶方法)来近似bilevel optimization。
其特性:
- 高效性:通过和clean-label方法对比
- 健壮性:对一个模型的中毒攻击能够同样适用于其他的一些架构和训练设置未知的模型上去。
- 通用性:不仅适用于微调场景,而且也能用作端到端场景下(clean- label攻击没有这个性质)
在现实世界中,对Google Cloud AutoML API进行了攻击。
method
受限制的双层优化问题
双层优化问题的描述如下:
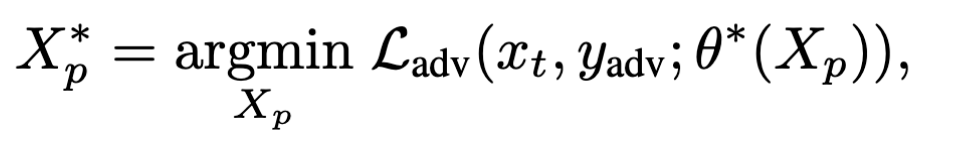
s.t. 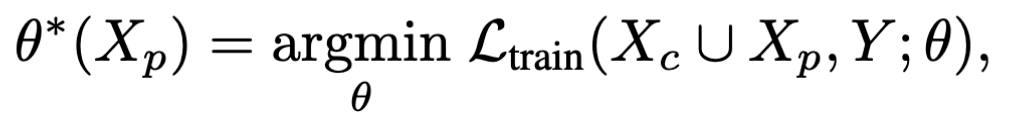
符号:
- $X_c$:干净数据 | $X_p$: 中毒数据
- $Y$:包含中毒攻击的样本以及正常样本 | $y_{adv}$:中毒样本
先优化train阶段($\mathcal L_{train}$使用的就是简单的交叉熵),然后再优化adversary阶段($\mathcal L_{adv}$使用的是Towards Evaluating the Robustness of Neural Networks中提到的adversarial loss $f_6$),最终的目标是找到$X_p^{*}$
为什么标题中双层优化问题加了一个constrained,因为中毒后的样本应该和自然的样本比较相似。基于此,作者选取了一个扰动模型(Functional Adversarial Attacks,称为$f_g$,g代表的是模型的参数:
$$
x_p=f_g(x)+\delta
$$
策略
将双层优化都最小化不太现实,这里作者选择:对于$\mathcal L_{train}$,使用K步SGD,然后再优化$\mathcal L_{adv}$。例如当K取2时,优化过程可以描述为:
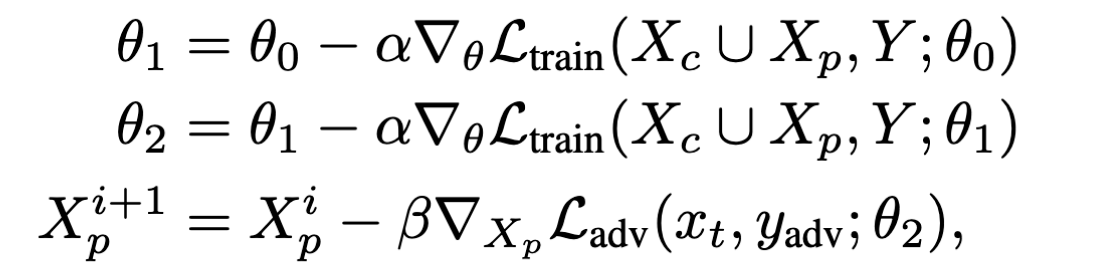
上面的方法称为展开训练管道,其成功的应用不在少数(元学习、超参数搜索、架构搜索)
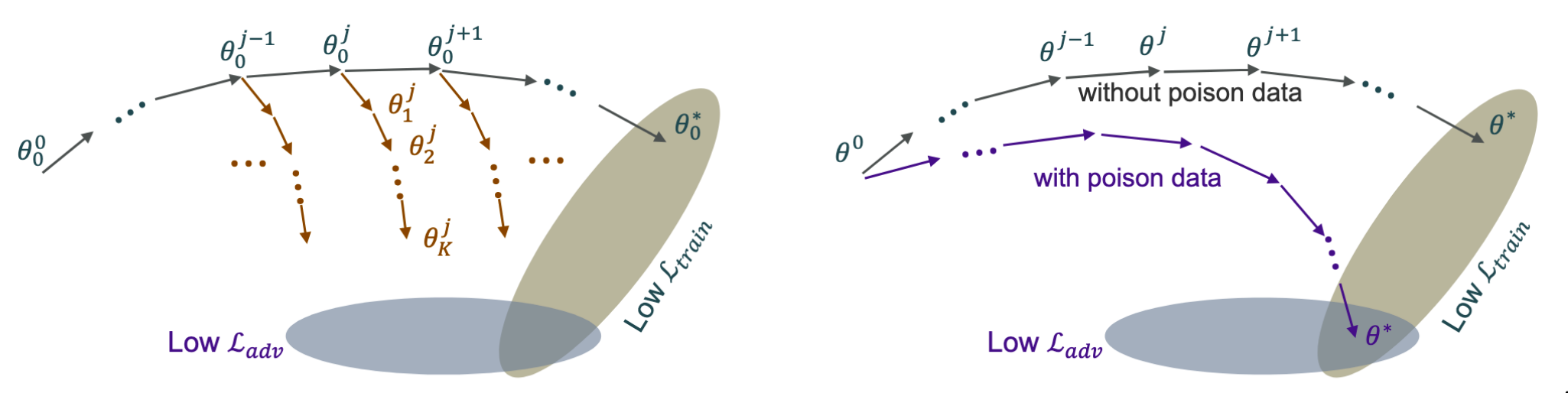
但将展开训练管道应用于本文的中毒攻击的双层优化问题,会有一些问题:
- 对权重初始化以及小批量数据的次序敏感,这些都是攻击者的知识涉及不到的。
- 作者的经验之谈:一个epoch内,使用单个代理网络来产生中毒,会使得这个网络对这一轮的数据过拟合,这样的后果就是模型对新数据的引导能力下降了(模型的目的是投毒使得受害者模型朝着$\mathcal L_{adv}$的方向偏转)
也就是说,本文需要的不是一个能够完美解决bilevel optimization的模型,而是一个可以对初始化不敏感、对epoch不敏感的模型。也就是说需要提升模型的泛化能力。
作者选择使用集成以及按epoch交替学习的办法来增加最终得到模型的泛化能力。
- 集成:有很多个代理模型来训练
- 按epoch交替学习:字面意思
然后作者将他的工作和已存在的工作进行了对比,通过计算,作者的任务需要5760次传播,而对比的已存在的任务需要12000次传播。
experience

