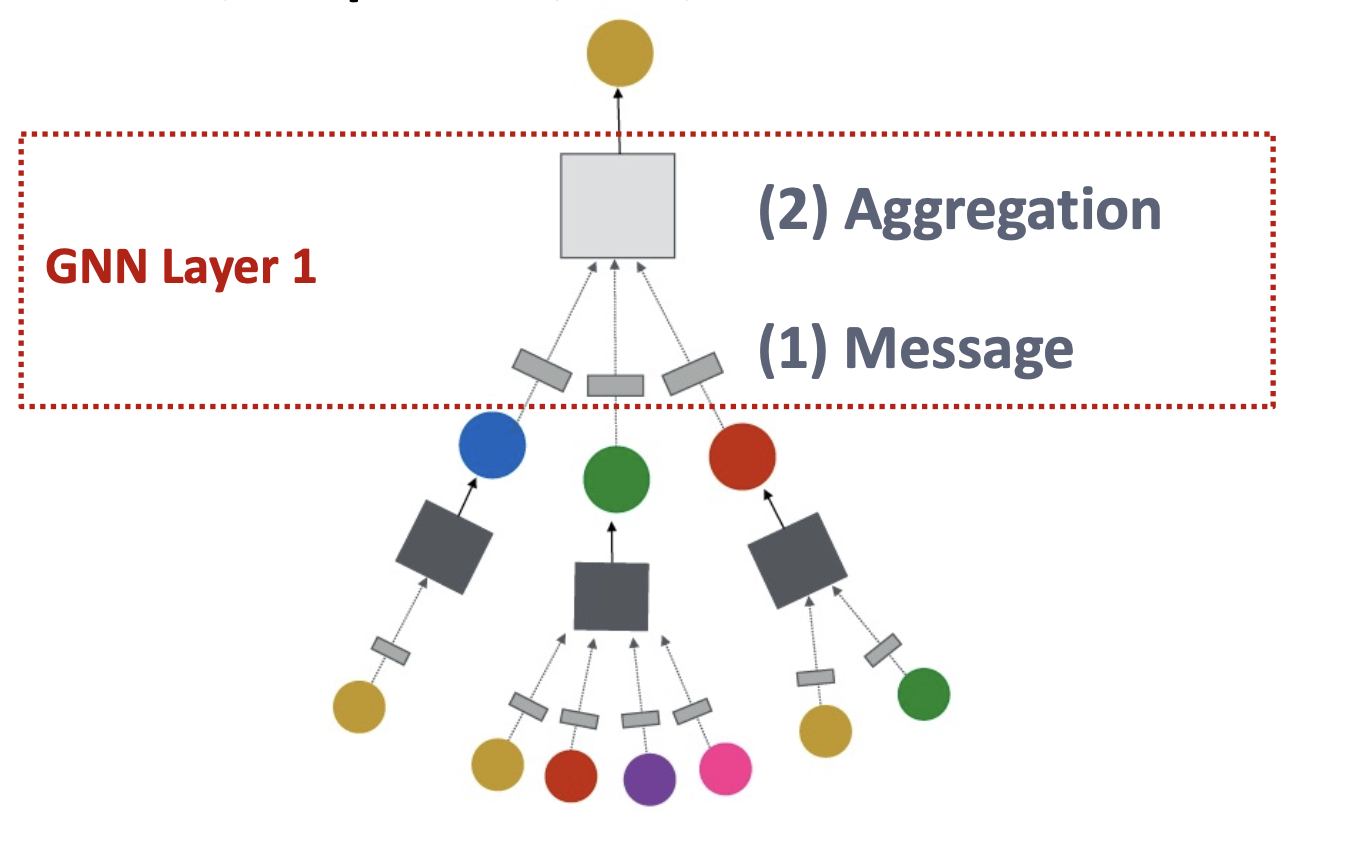
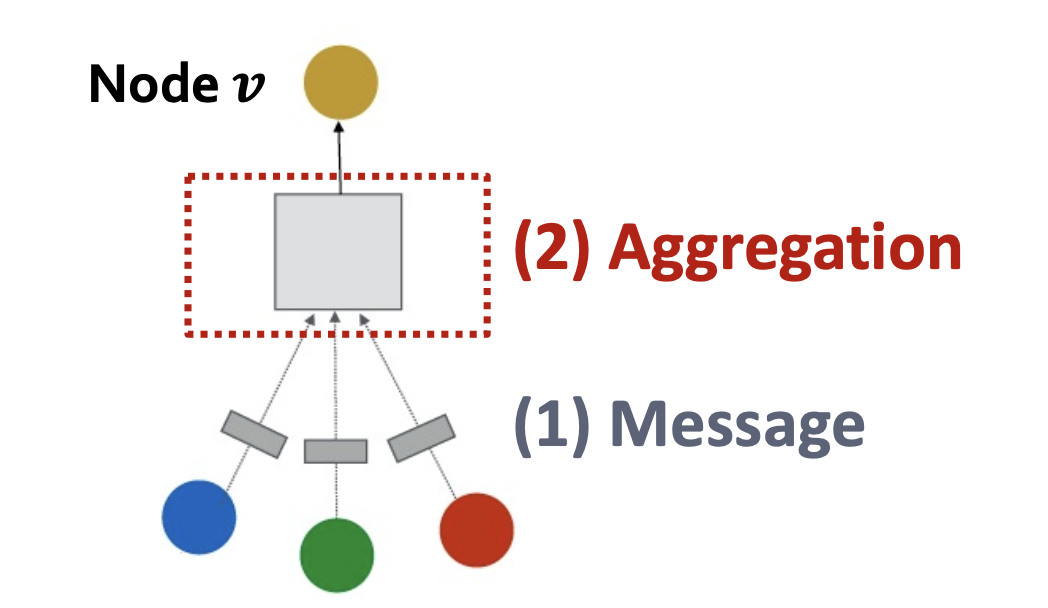
a single layer og GNN
there are many different GNN: GCN, GraphSAGE, GAT…
the difference between them mainly are:
- message send
- message aggregation
message send
$$
m_u^l=\mathcal {MSG}^{(l)}(h_u^{l-1})
$$
moostly the message function is linear:
$$
m_u^l=W^{(l)}h_u^{(l-1)}
$$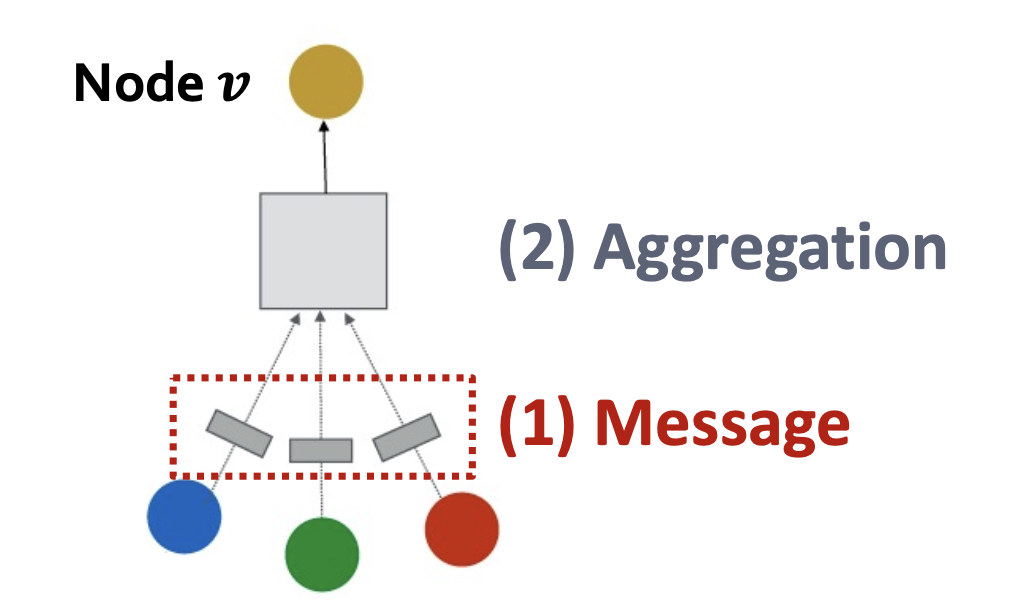
message aggregation
the aggregate function could be: sum, average, or max polling…
and its previous message also should be considered, so:
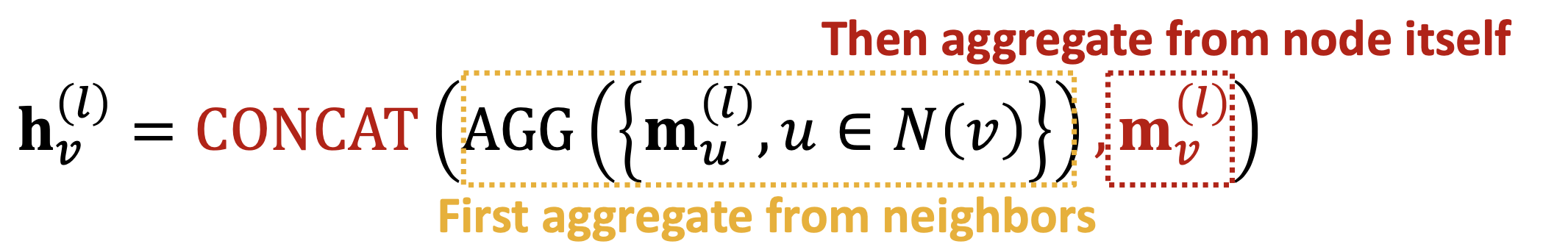
GCN
Lets look at GCN, single layer:
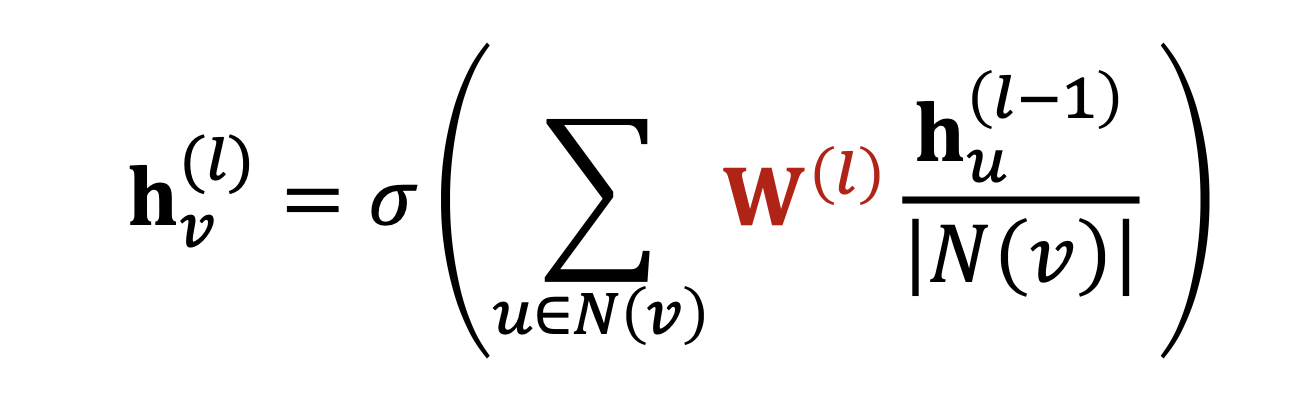
- message send: one linear and a normalized factor $\frac{1}{N}$
- message aggregate: use $SUM(.)$ as the aggregate function
GraphSAGE
Single attention
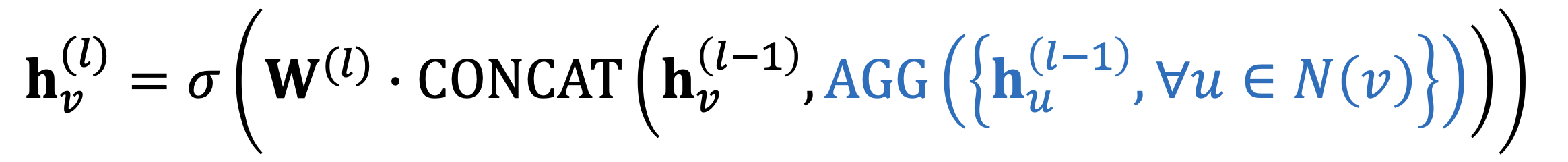
it can select $SUM(.),MAX(.)…$ as its AGG.
and the linear is behand AGG with a concat.
What’s more, the AGG also canbe:
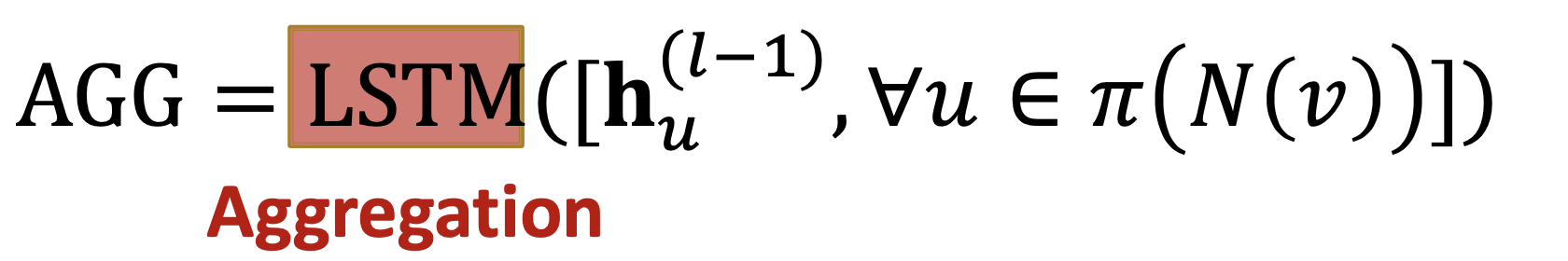
GAT

Intuition: different neighbors set different attention coefficient.
for GCN, it is $\frac{1}{N}$
and for CAT, how to caculate attention?
the importance of u towards v is:
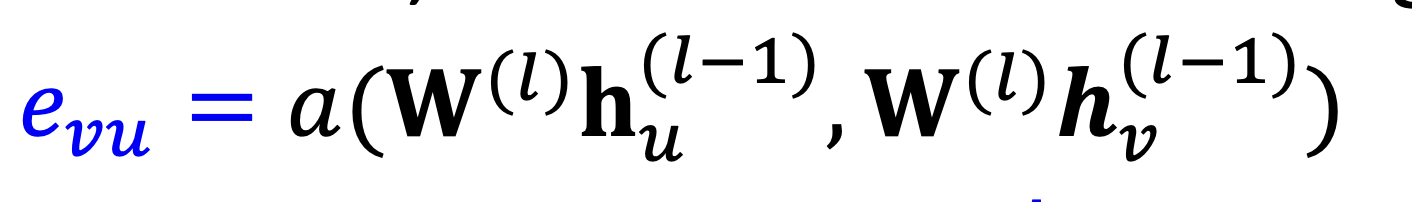
the weight is form a linear:
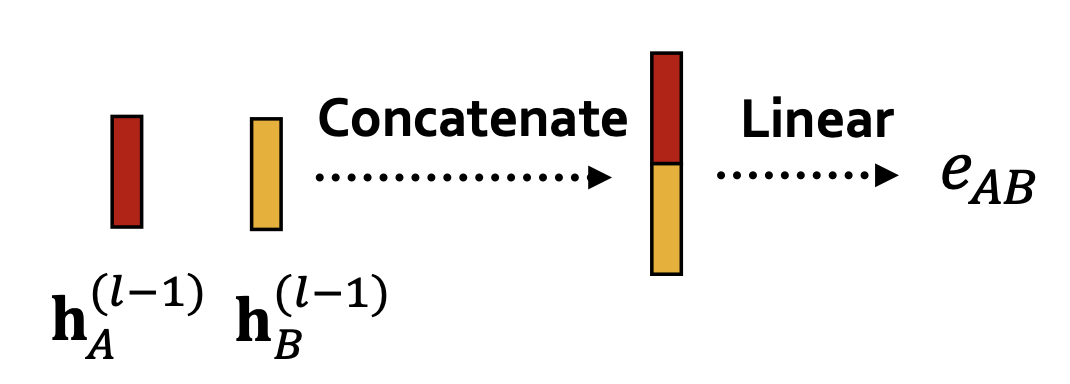
and for a node v, its attention is:
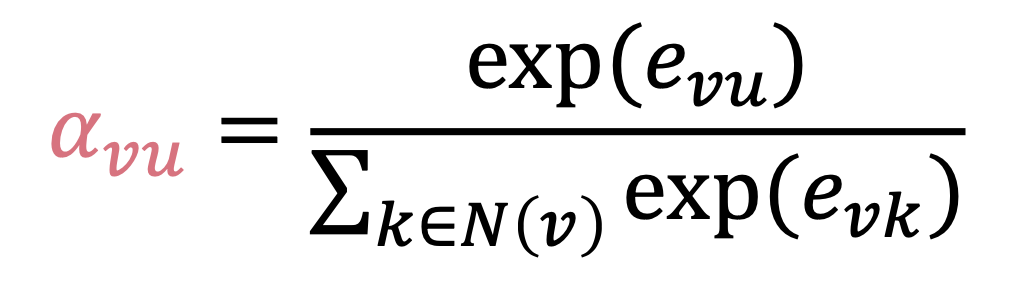
Mult-attention

the reason is: avoid the attention coefficient to trap into local optimization
Deep learning module
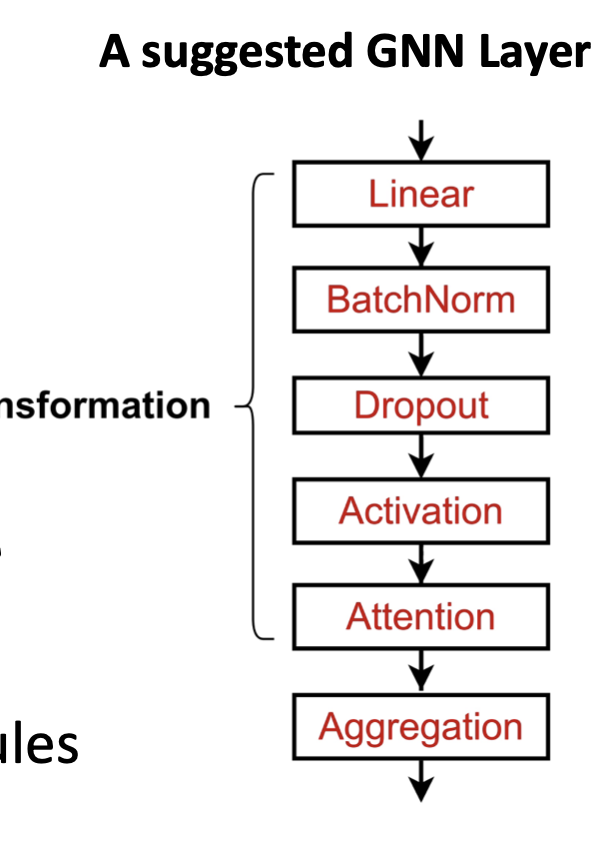
batch normalization
Goal: stablize the train stage
Idea:
- Re-center the node mean to 0
- Re-scale the variance to 1
Setup:
Re-center and re-scale:
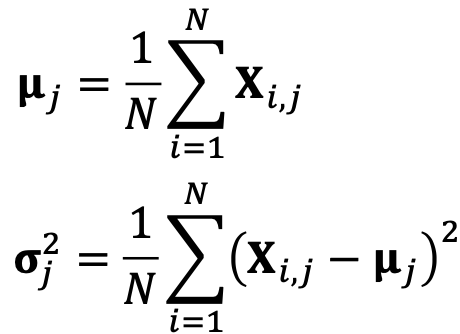
use trainable parameter $\beta$ and $\gamma$ to normalize the label
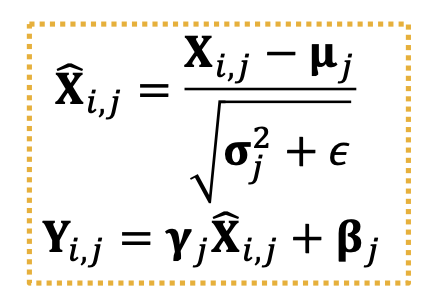
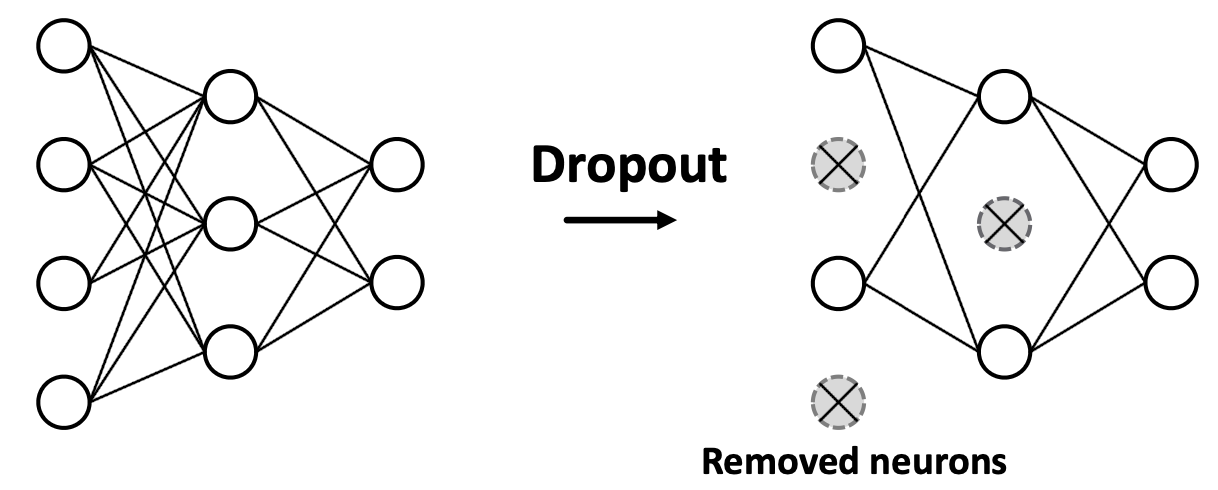
Dropout
Goal: prevent overfitting
Idea:
- when training, randomly(the prob. p) set some neurons to 0
- when testing, using all neurons to computer.
In mlp:
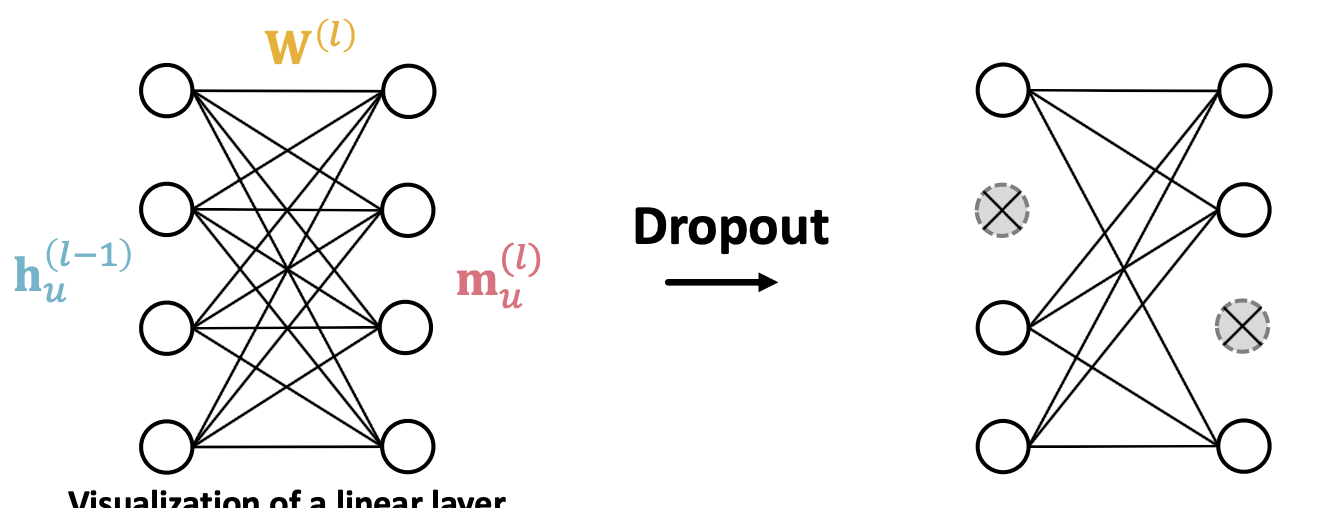
in GNN, it is in the stage of message send, in linear layer:
Activation

Stack Layers of a GNN
how to stack single GNN layer?
- stack layers sequentially
- add skip connections
stack layers sequentially
let’s see a 3 layers GNNs:
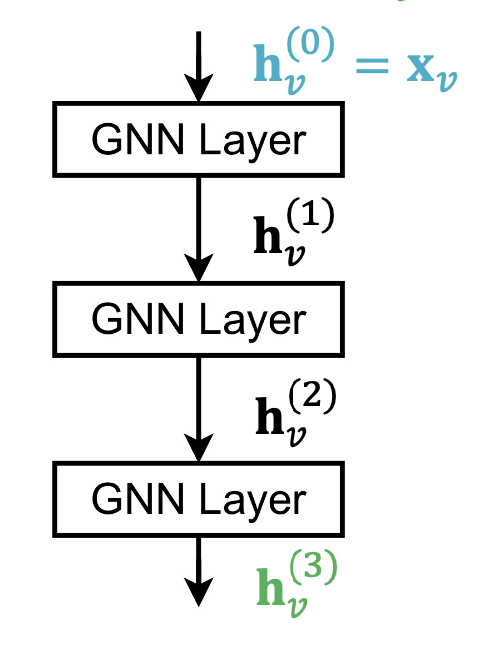
what’s the problem?
It might over-smoothing
The notion is: in the i th layer(such as 4th, 5th…), all node embeddings converge to the same value. This means in the last layer, all nodes are same. And our object is to make distinguish deferent nodes.
let’s talk about an another notion: Receptive Field
it means: the set of nodes that determine the enbedding of a node of interest.
and in GNN, the receptive field of one node can be seen as K-hop neighborhood.
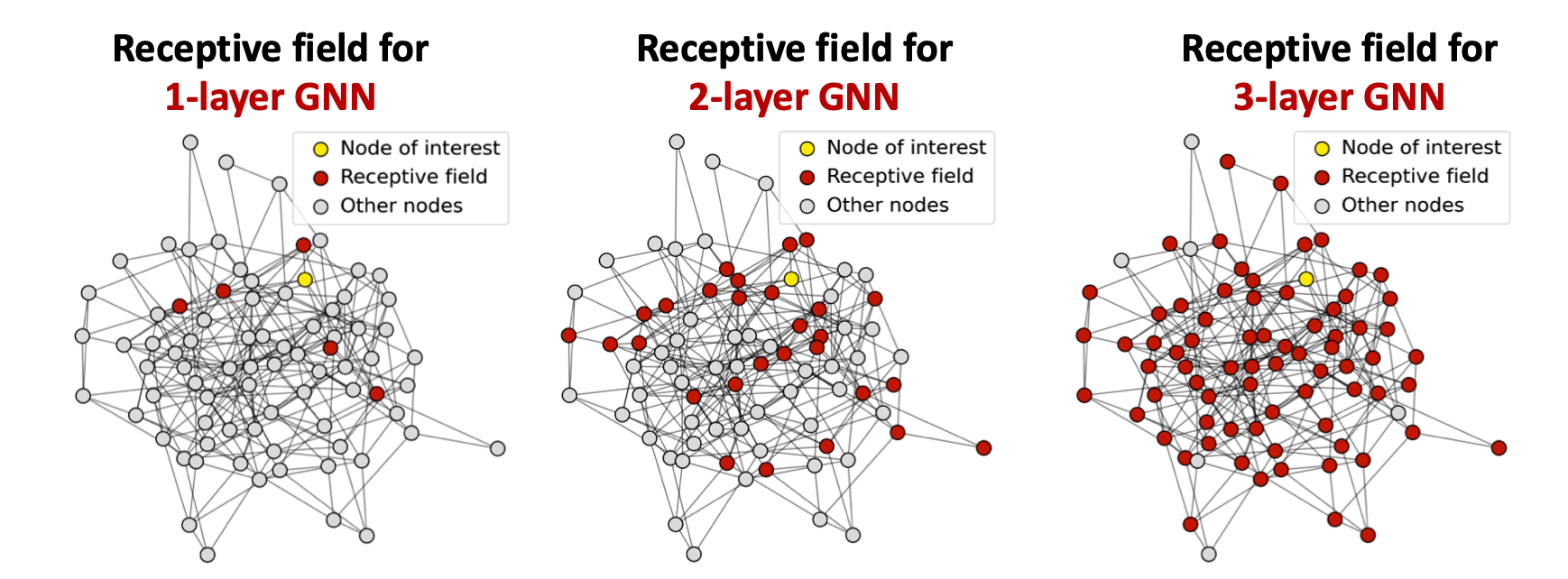
and the over-smoothing problem can be represent as:

so, the lesson is: we should determine the layers number cautious.
And the experience is: the GNNs layers number is often the receptive field of nodes plus one.
enhance the expression power
the next problem is: how could enhance the expression power of GNN?
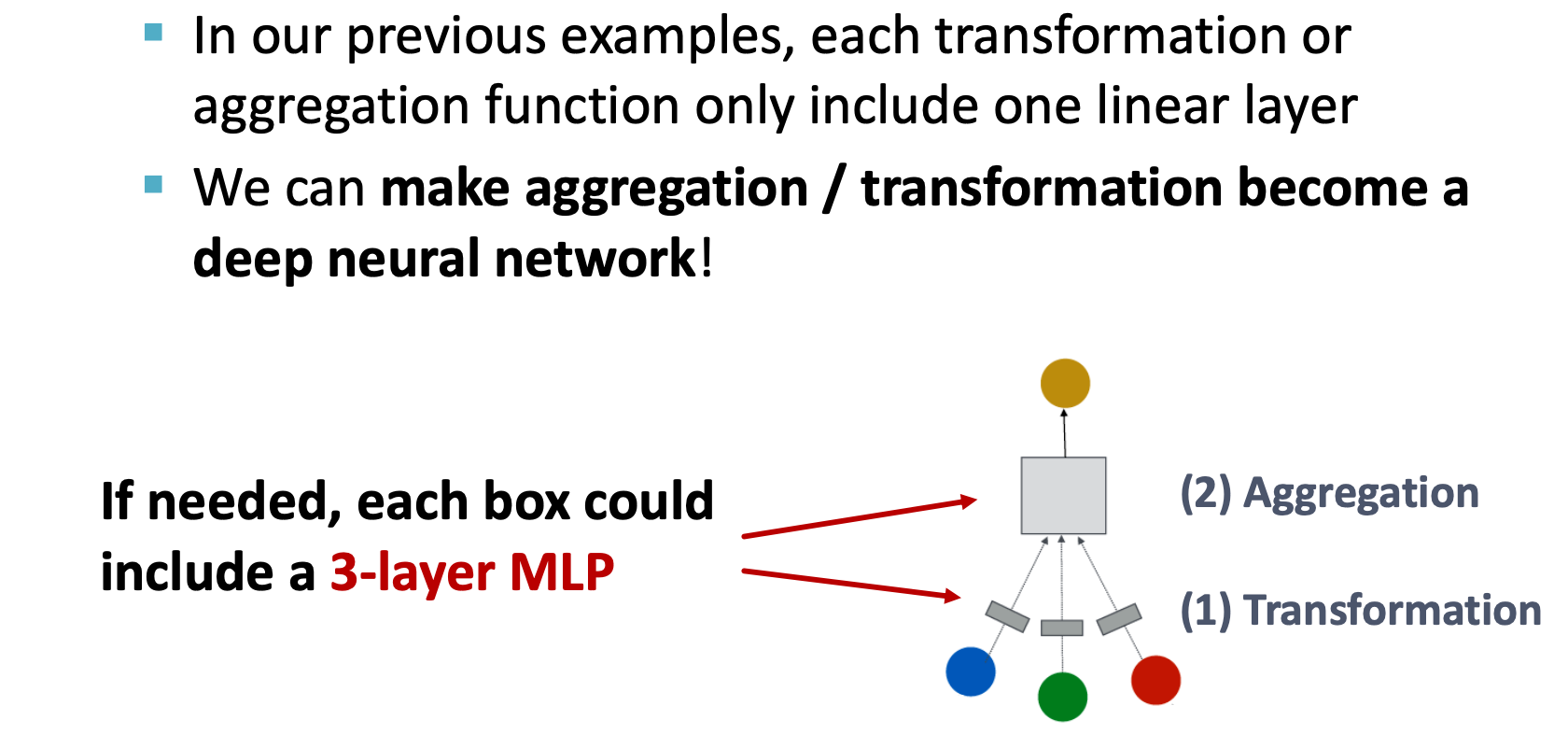
add layers that not passing message

Increasing the expressive power withen each layers
skip connection
the problem is: what if some downstream task still needs many GNN layers?
the intuition is from ResNet.
we could add skip connections in GNNs.
one way:
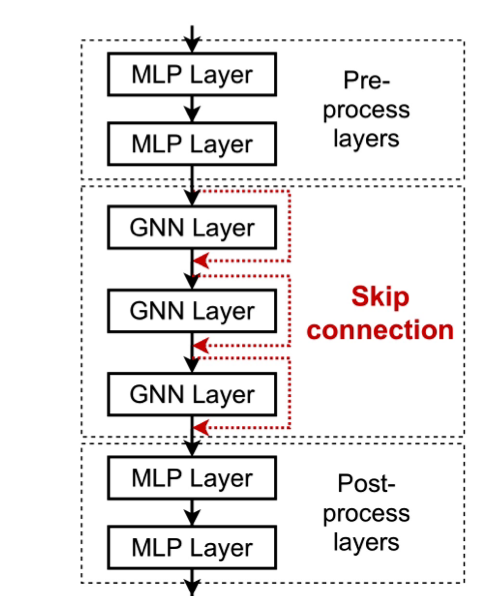
Another:
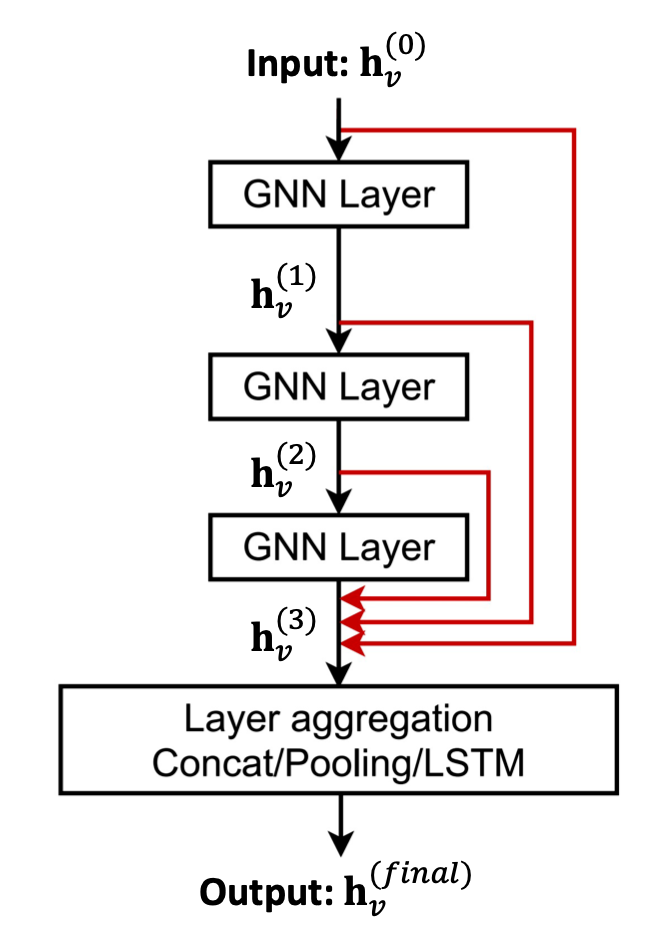
why does it useful?
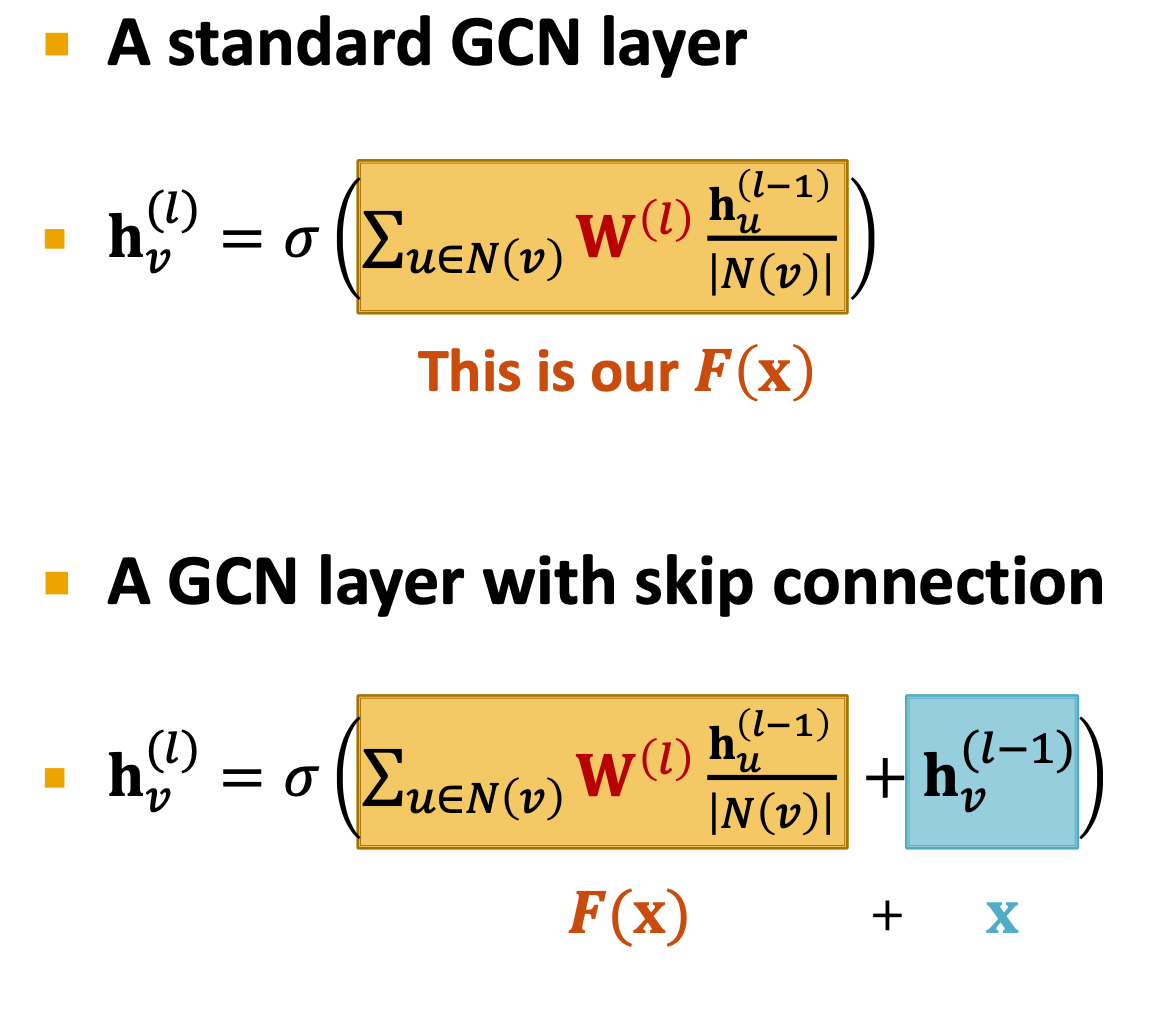
the skip connection model can create a mixture of n models.
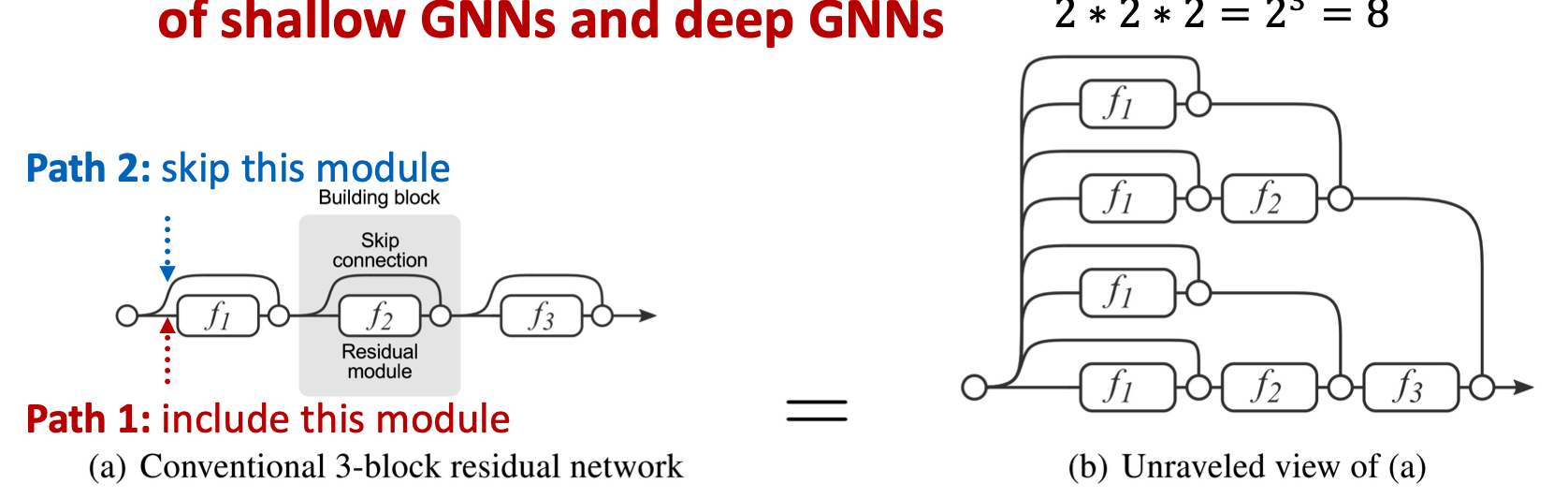
the difference of GCN and the GCN with skip connection