
1.1 why graphs
首先要回答标题这个问题,为什么是图?抽象的图可以用一些结点和边来表示:
而生活中的很多物体、场景都可以抽象为图:
距离、地面图:
现实中的一些网络:

知识图谱、场景图、代码编译图、生物分子、计算机3D图形:
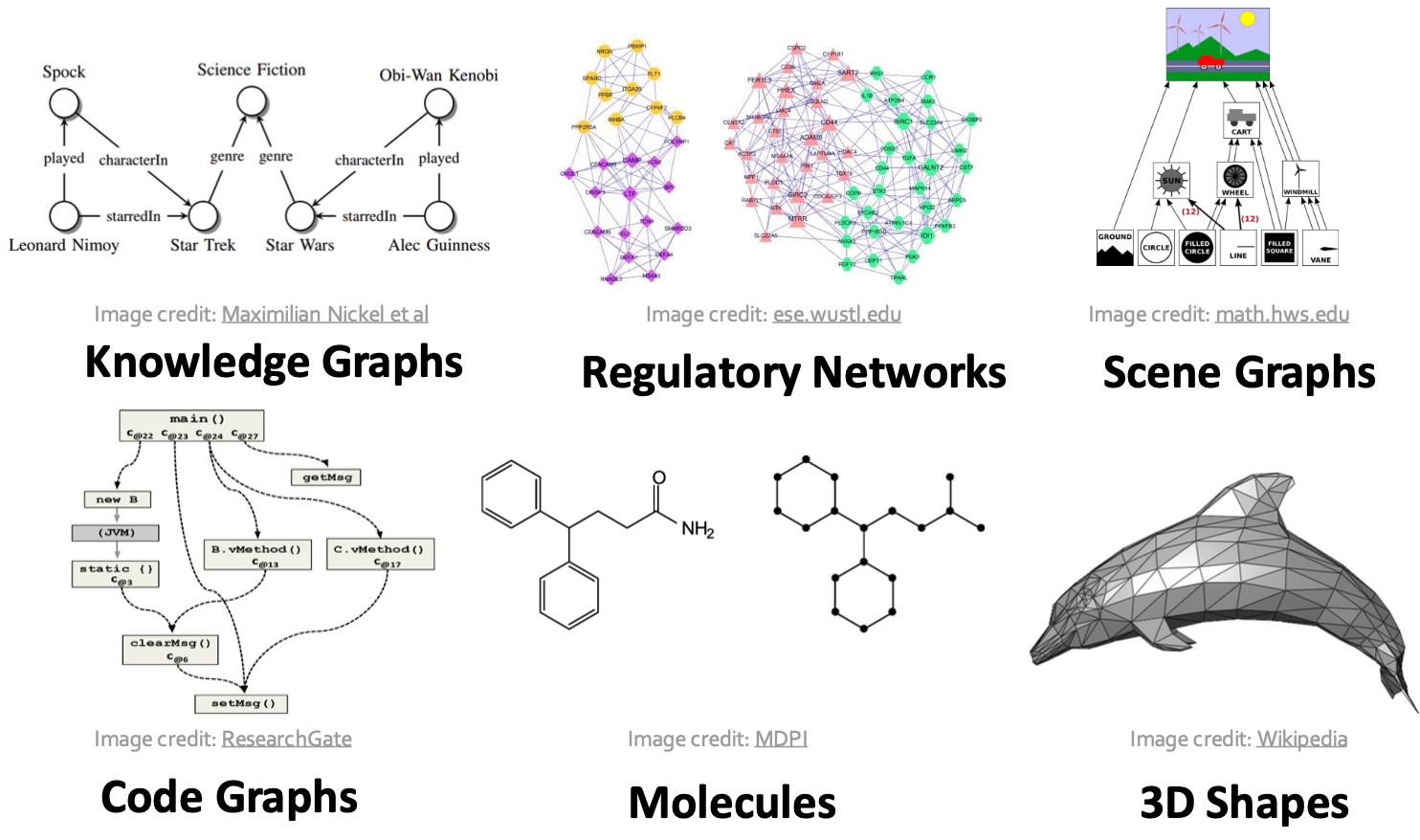
我们可以使用图对上面这些以及更多的生活中的基础场景进行建模,然后来进行处理。
如今的深度学习时代,有很多非常强有力的工具能够处理序列/网格数据,如:语音、文本等,也能够很好的处理fixed image来进行预测和分类,在这些方面已经有了惊人的成就了。但是,对于graph和network,这种具有任意大小、任意拓扑的数据结构,它没有序列数据那样具有spatial locality(空间局部性),在文本、语音中有左和右,在图片中有上和下,但是对于图graph,我们没有任何的参考点,没有任何的顺序。
我们期望的是在graph上建立神经网络,输入是我们的graph,输出被期望是在一个结点的多个方面去做预测,如预测结点类型、结点属性、结点的下一个路径等。
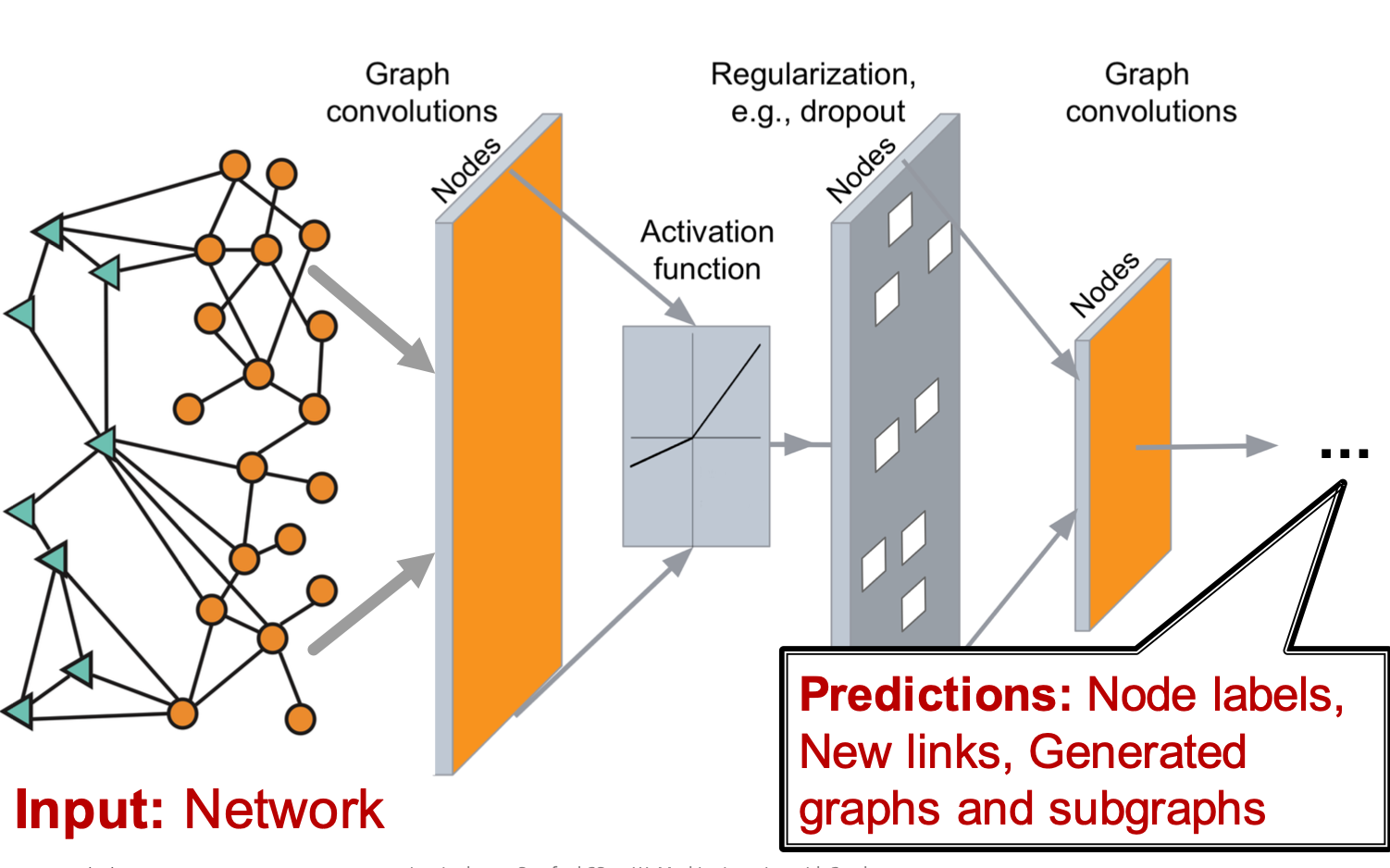
另外,feature engineering也不再需要,现在是representation learning,机器会自动找到更好的representation,然后来做下游任务。
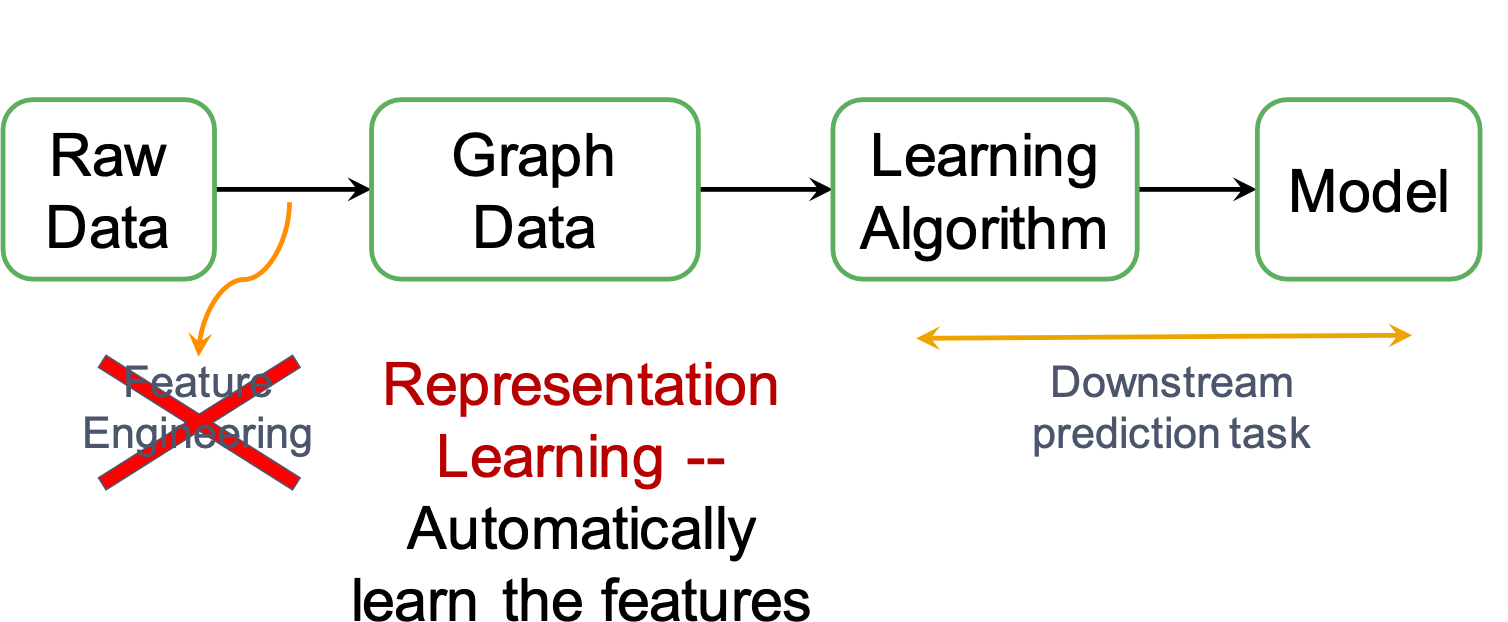
representation learning:自动提取或者学习特征。
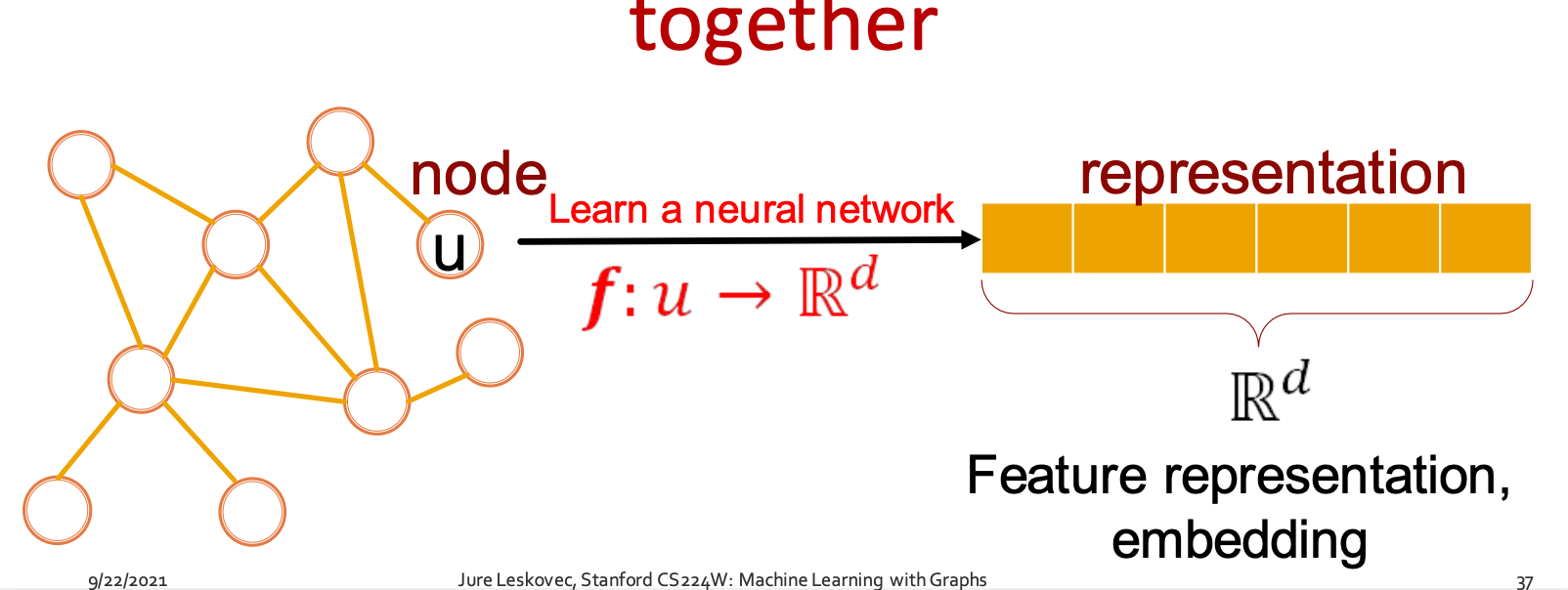
除了上面那个神经网络架构,我们的目标还可以表示为下面的形式:将graph嵌入到一个d维的向量中,这个向量就是我们最终的representation。
1.2 application of graph ml
graph ml任务可以分为好几种:
- Node-level:预测结点的属性
- 如用户类型分类
- edge-level:预测两个node之间是否缺失边
- 知识图谱
- sub graph-level:社区预测
- Graph-level:对图进行分类
- 例如画出一个分子图,来预测它的属性
- Graph-generalizing:用已存在的药物发现新的药物
edge-level
一个真实的应用:AlphaFold,DeepMind研发的框架,用来预测蛋白质,给定一些氨基酸,能否预测出这个蛋白质出来。这就属于是edge- level task
PS:DeepFold获得2023年的诺贝尔奖!
另外一个link-level task是药物副作用,有很多年纪大的人有很多co-exist的疾病,要同时服用很多种药物,那么这些药物和药物之间是否具有某种联系(link/edge),但是这样的组合很多,不可能去通过排列组合来尝试。所以能否建立一个系统,来判断药物之间是否有edge?
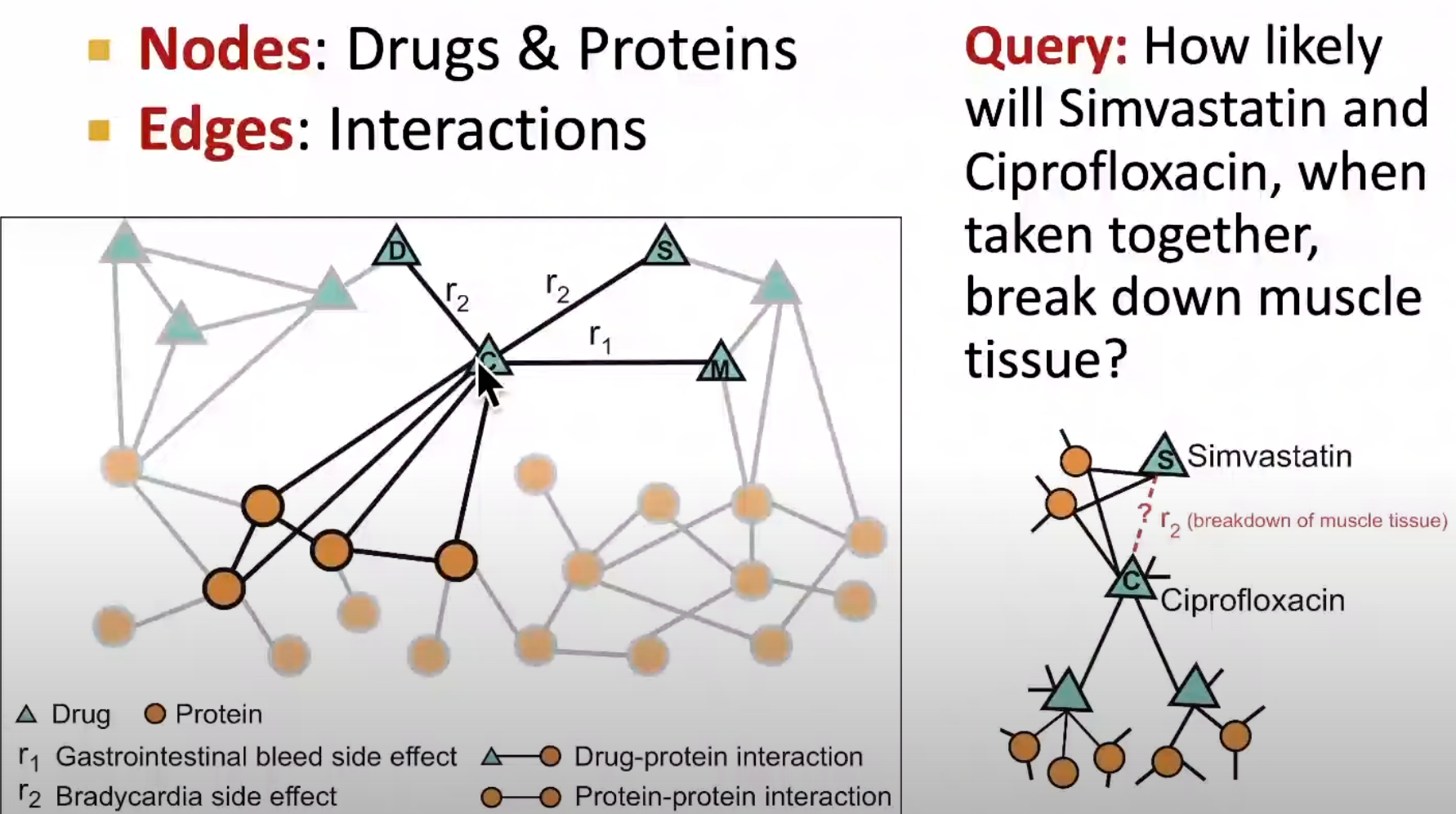
生物学家已经能够通过实验确定两种蛋白质之间是否有作用或者反应,但是药物与药物之间是否有反应还未知。
Node-level task
一个最明显的就是推荐系统:
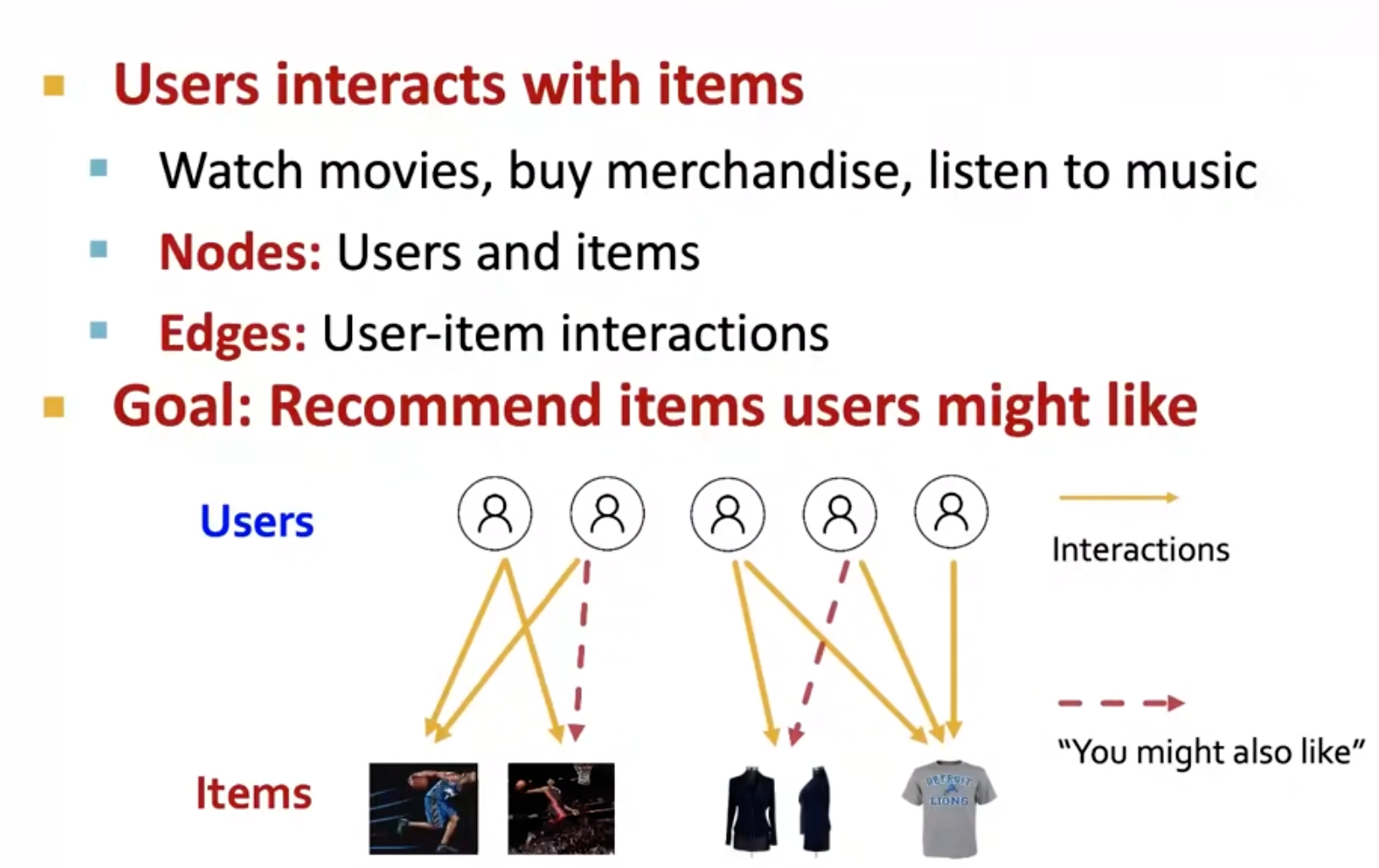
其中node可以是人或者item(衣服、音乐、食物、电影……),当人跟item交互,人购买了衣服,听了音乐,那么他们之间就有一条edge。
下面一个推荐系统,我们的任务是把node做一个合适的嵌入:

可以这么理解,更相关的node应该被嵌入到一起(比如上面的将图嵌入到一个d维的向量中去,这两个蛋糕应该被嵌入到一个相同的向量下标中去)。
Sub-graph level
例子:Google map
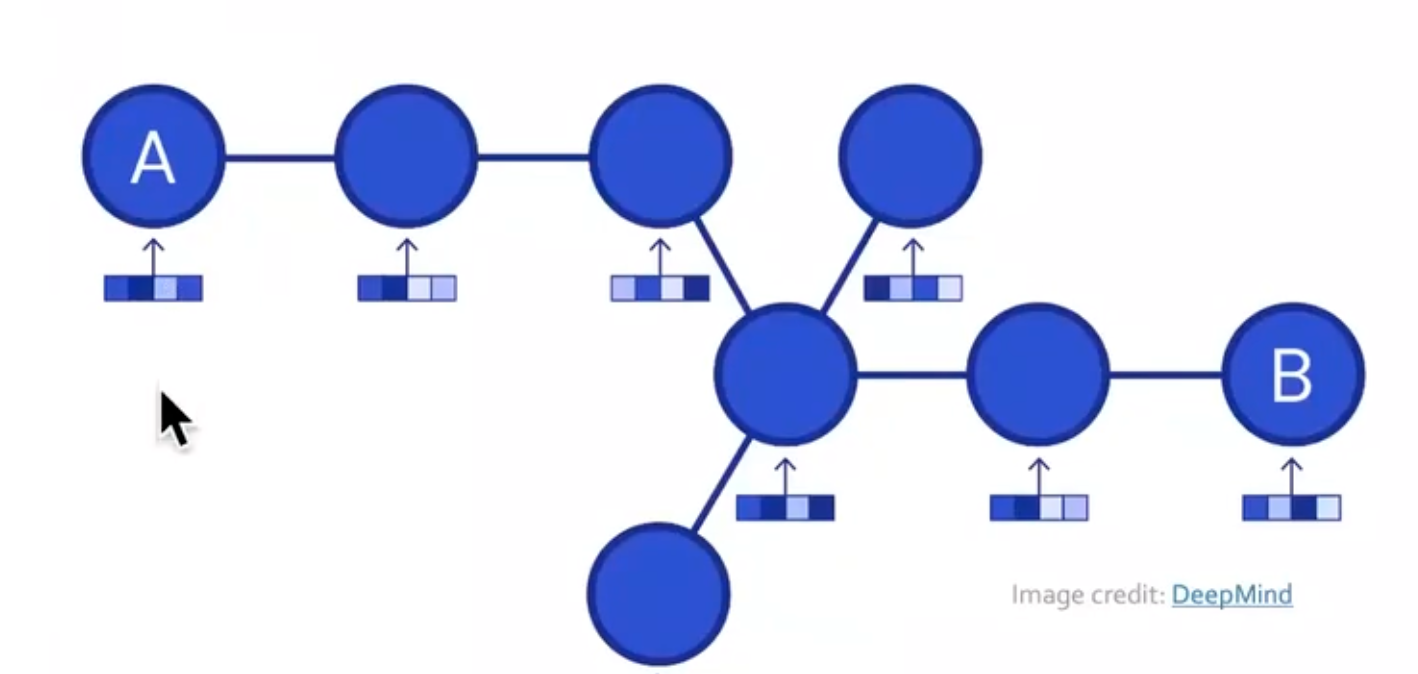
node代表的是路段,edge代表的是两段路之间的边缘,也就是两段路是不是连接的。
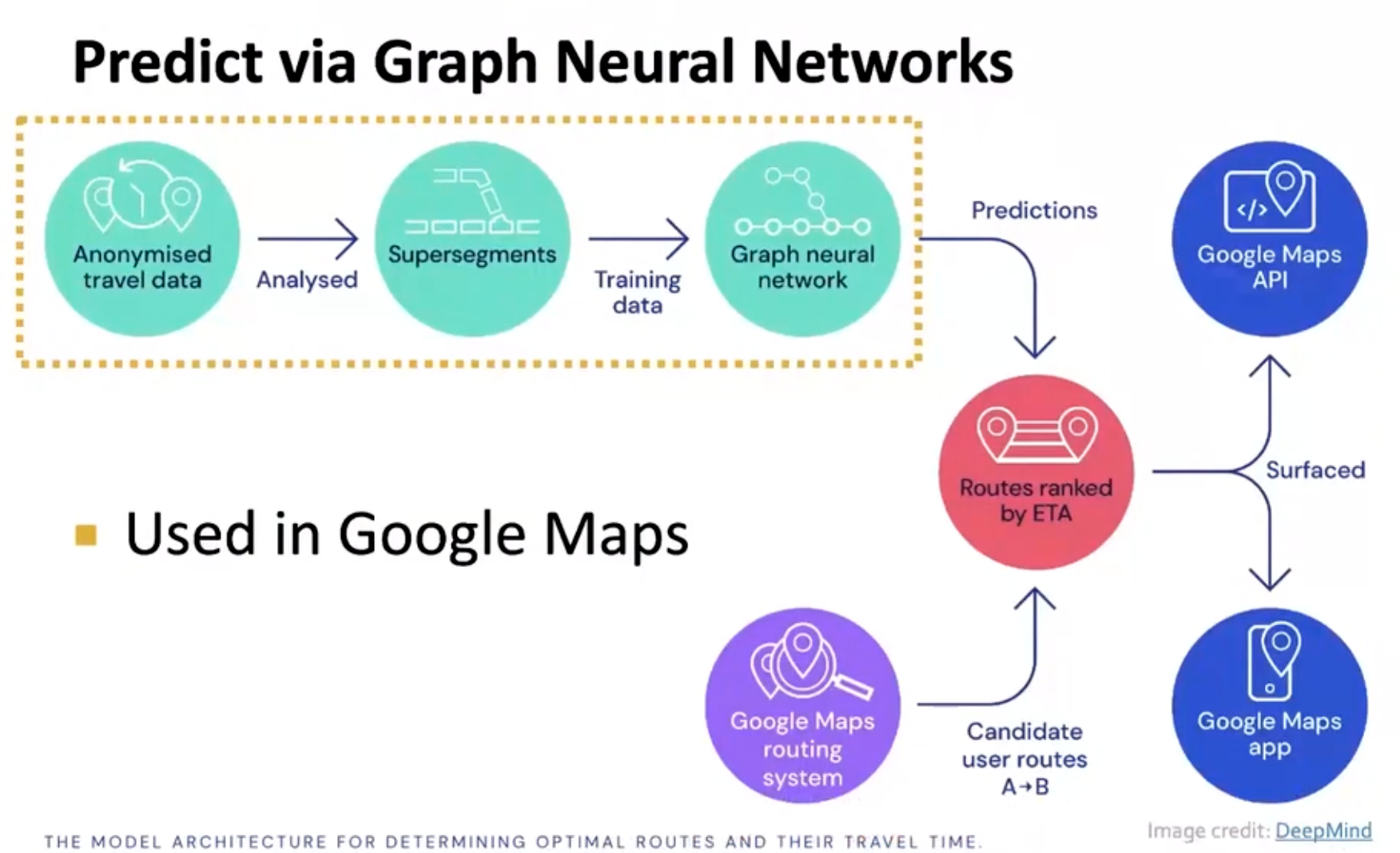
并且GNN是根据每段路的路况、长度等因素训练而成的。
1.3 choice of graph representation
选择什么是边、结点很重要,有时是独一无二的,不然会影响到最终的模型的性能。
介绍了一下图的基本定义,这里有一个不熟悉的点:
bipartite graph:
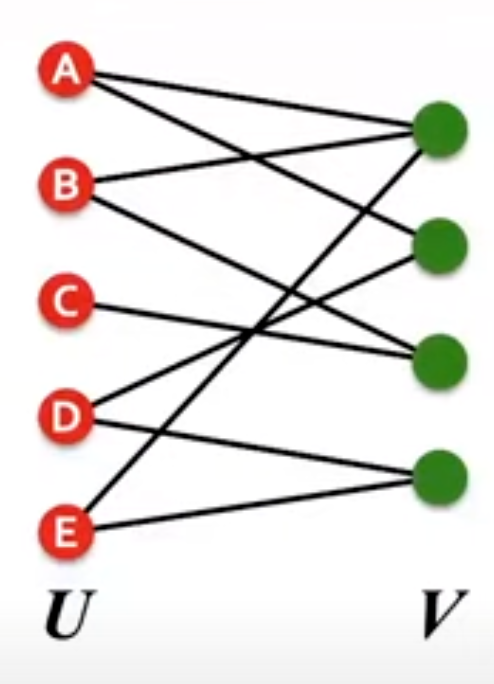
bipartite graph有两类结点,两类结点之间互相会link,同一个部分的各个节点并不会interact。
下面是举例:

由bipartite graph,可以演变出fold network,例如作者合作网络,左边是作者,右边是书,1、2、3共同写了一本书A,2、5共同写了B,那么可由中间演变出左边的fold network
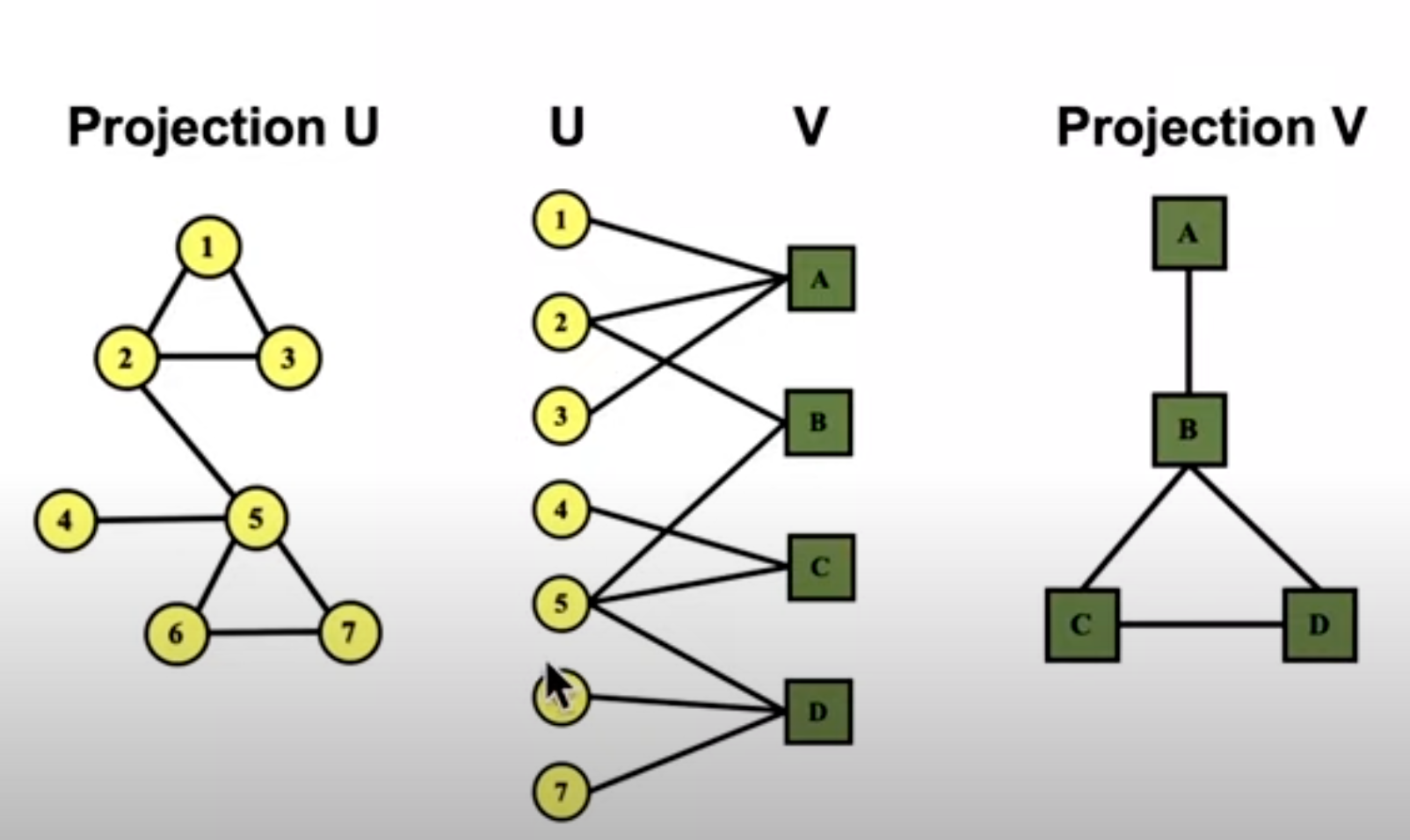
反过来,也可以由书推到作者,生成上面右边的fold network
下面开始将如何去represent graph
adjacent metric
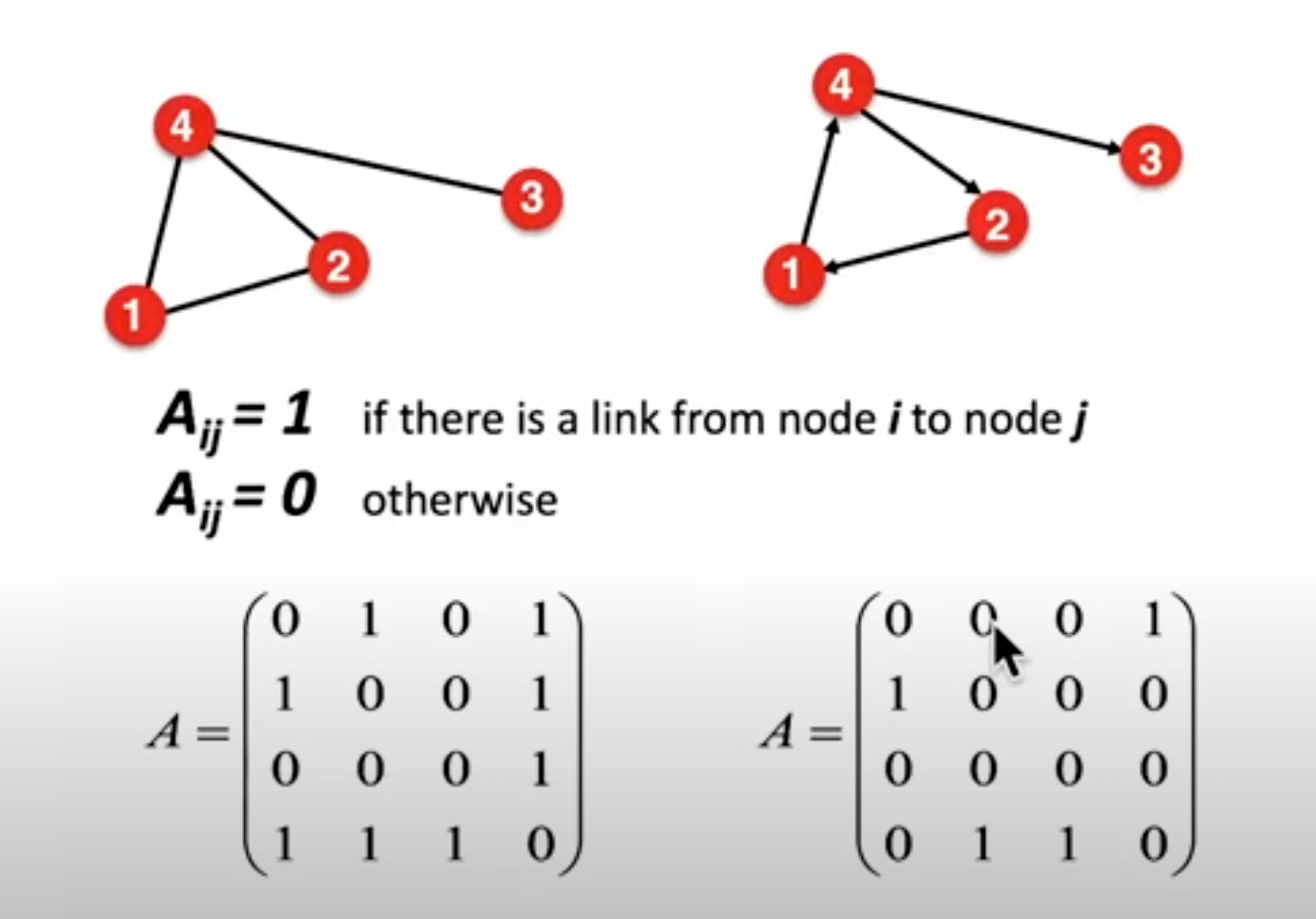
adjacent metric的缺点就是其太稀疏(sparse)了,以人类为例子,画一张图,我们每个人的out degree也就那几十几百个,不会是几百万个,所以这张图中有很多元素是0
edge list
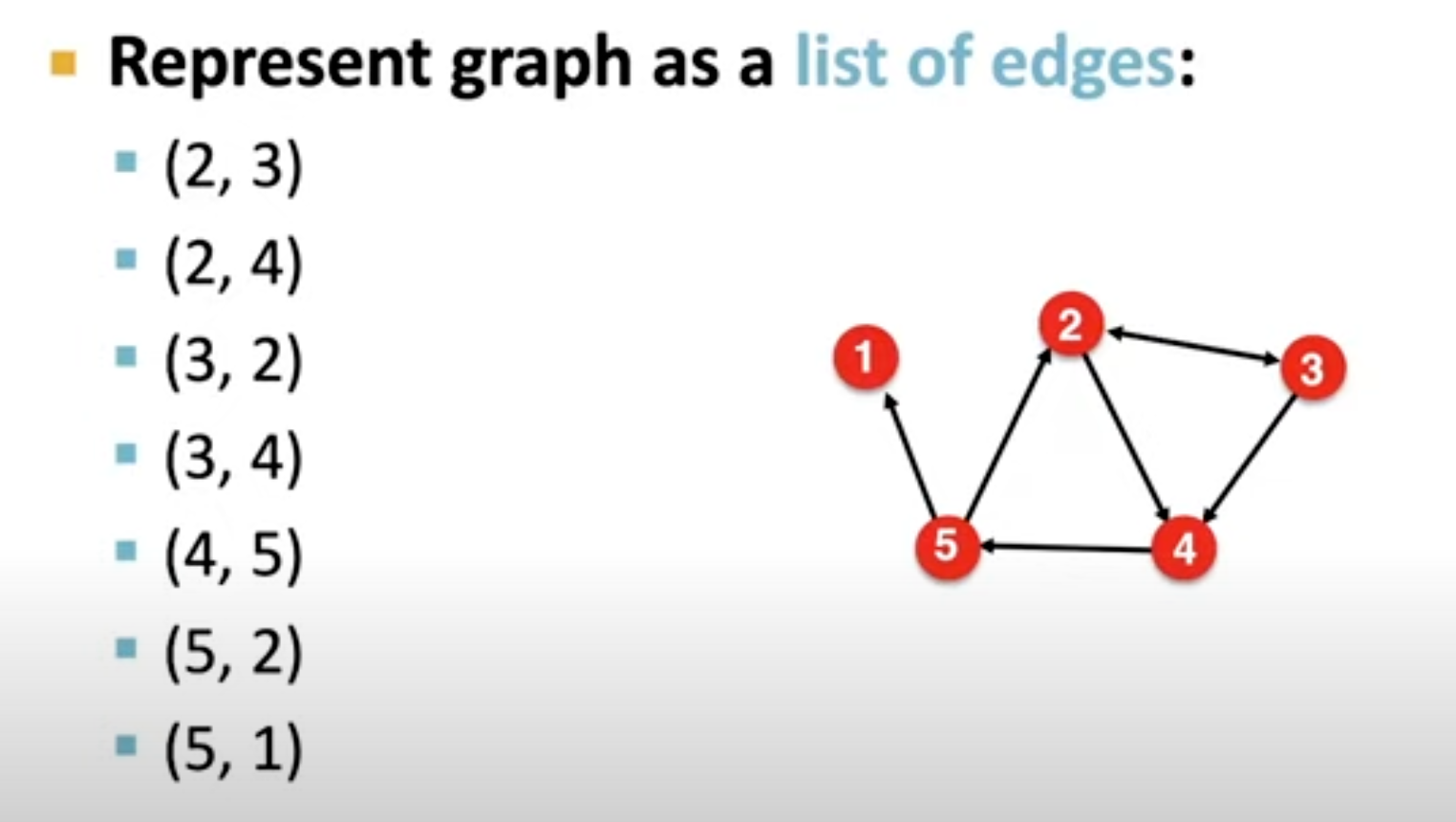
这样的表示存储起来就小多了,但是其问题在于,很难对图进行操作,例如想算一个node的out degree,比较麻烦。
adjacent list
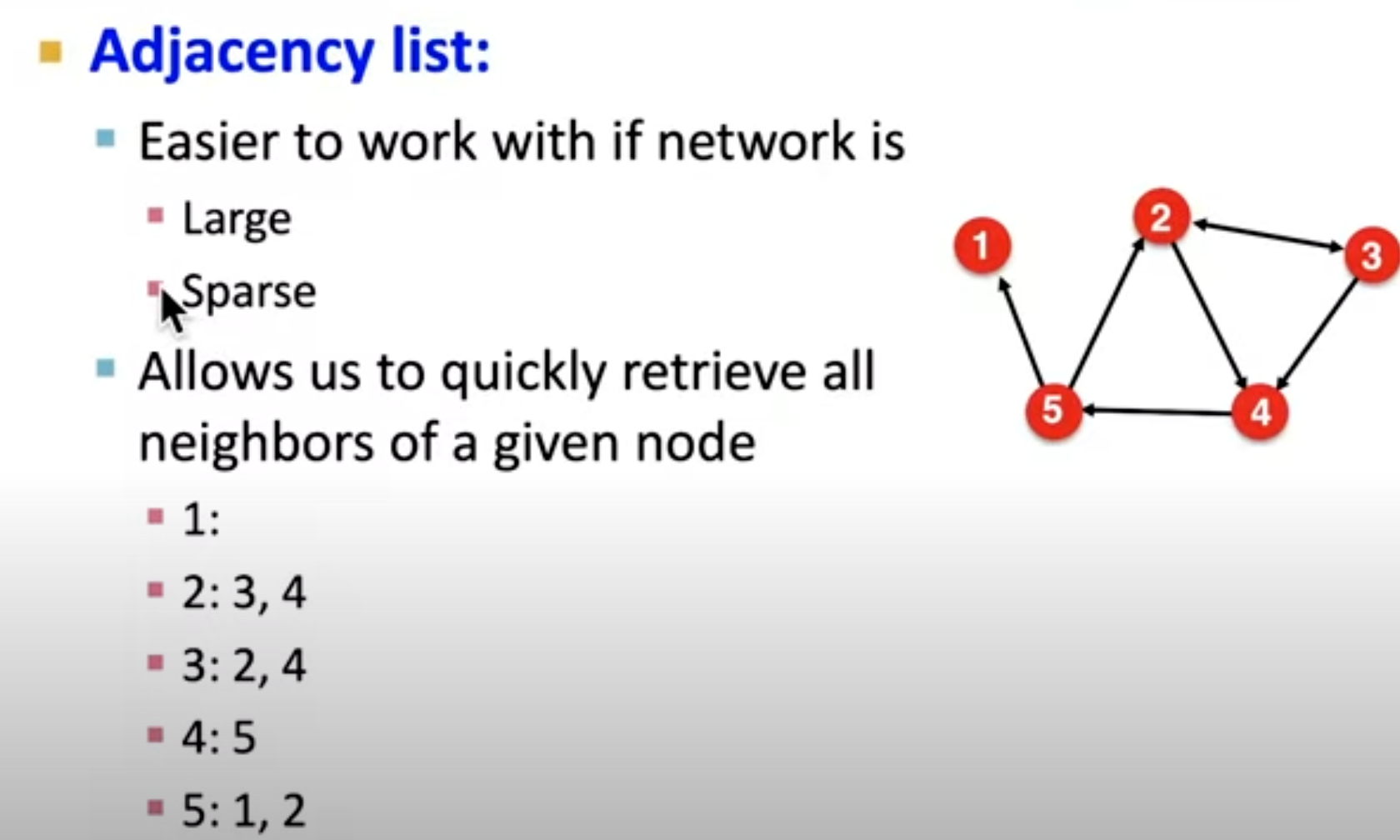
相对而言这是一种比较折中的存储结构了。
