
从背景、问题、方法、结论、创新点、相关工作、评价等几个方面做论文笔记
1、研究动机是什么
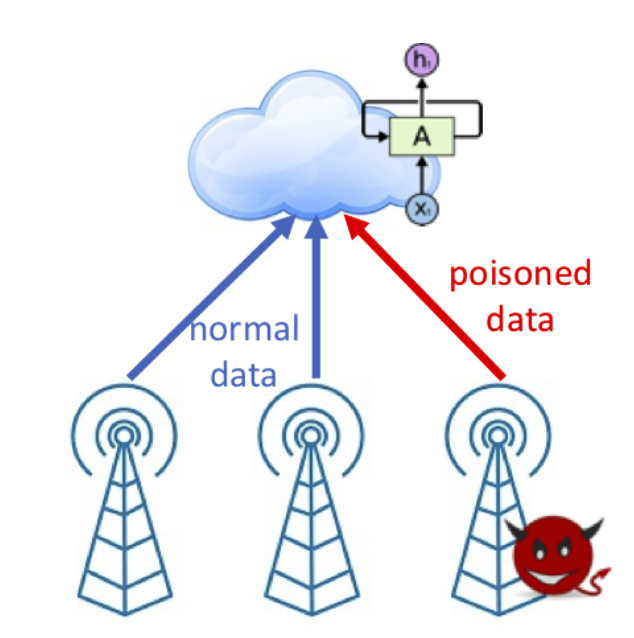
poisoning attack这个问题在CV领域已经有人做了,但在WTP领域还是空白。
2、主要解决了什么问题
作者提出了两种攻击方式,分别是在集中式和分布式场景下,对训练阶段进行中毒攻击;并提出了两种防御方法,验证了其有效性。
3、所提方法是什么
集中式场景–数据中毒攻击–数据清洗;
分布式场景–模型中毒攻击–异常检测。
4、关键结果和结论是什么
5、创新点在哪里,这篇论文到底有什么贡献?
在WTP领域提出两种中毒攻击并且提出了解决方法。
在WTP这是一个全新的问题。
6、有值得阅读的相关文献吗
有很多,可以列成树了都,比如在这篇文章中作者做了很多假设,而有的假设是existing work,有的则不是,作者文章中选择了稍微简单一点的假设,便于处理,但从本文中还是可以看到很多别的方向的。
- 集中式场景下,假设malicious client智能知道自己的数据
- 分布式场景下,malicious client也是独立的
- 分布式场景下,malicious client上传增量模型用于更新事,假设模型不会发生碰撞
- …
7、综合评价如何?
看数据的话是好的,中毒后,MSE飙升;使用了提出的防御方法后,MSE又降下来了。
8、用于定量评估的数据集是什么?代码有没有开源?
两个数据集,在Google Drive中可下载;
代码开源了部分
9、下一步呢?有什么工作可以继续深入?
如问题6
摘要
本文的工作:
- 在无限流量预测领域,针对训练阶段的脆弱性,提出了2种攻击方式
- 扰动掩盖策略
- 调优和缩放方法
- 针对攻击,提出了两种防御方法
- 数据清洗
- 异常检测
本文对集中式和分布式的场景都进行了实验。
介绍
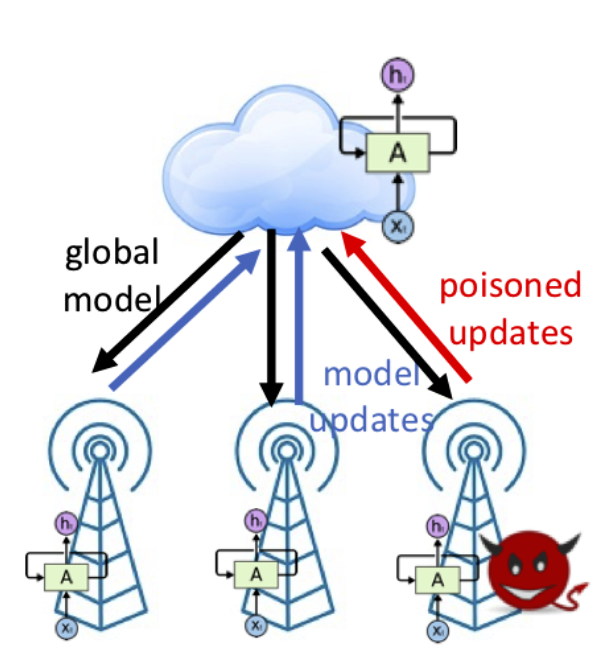
作者不光吹捧了下已有的工作,还进行了对比,提升了多少多少(优点),然后指出这些工作用的是DL,但是都是在非对抗环境下完成的,如果是对抗环境可能情况完全不一样(malicious client)。然后就是针对不同场景,阐述对抗环境下模型训练的潜在危害:集中式场景下,恶意客户端可以将有毒数据混入数据集上传给云服务器;分布式场景下,则是可能会将中毒模型增量上传到云服务器。
作者表示,人为导向的预测只需要少量的有毒数据即可。举的例子有信息安全(AES的加密)、推荐系统、以及向深度学习的模型中植入后门。
但是在无限流量预测这个领域,中毒攻击还没有被探索。作者做了好几个假设:
- 集中式场景下,恶意客户端只能访问他自己的流量数据
- 分布式场景下,恶意客户端提交模型增量更新的时候不会发生碰撞,同时也不能一起合作。
基于这几个假设,作者提出了扰动掩盖策略:利用有限的数据,来模仿集中式模型的优化过程。大概做法是,将本地的数据集分为两部分:10(1-p)%的干净数据以及100p%的加了扰动的数据,将这些数据扔给本地的代理模型进行训练、优化,使得这些扰动看起来更加普遍;调优和缩放方法则是运用于分布式场景下,这个看不太懂,等下看公式。
然后针对这两个attack,作者测试了以前的防御方法(数据消毒和随机平滑),但是性能不是很好。然后这里作者有提出了一个假设:在两个相邻时间点之间,无线流量的量很少变化很多,然后定义了一个adjacent distance,将这个距离最大的点移除(数据消毒)。另外,还实现了一些健壮性的回归方法。(existing work)
作者做了一些实验,用的数据集是“wireless traffic data from Telecom Italia”,然后使用的模型是LSTM、ConvLSTM……实验结果显示中毒攻击可以使训练好的model的MSE提高很多。然后对比之下,使用刚刚提到的数据消毒以及异常检测方法,
背景以及真正的工作
符号及表示
用$x_t$代表时刻t之前的一部分流量数据,$y_t$表示t时刻的流量,模型用$f_{\theta}(.)$表示,预测结果$y^{-}t=f{\theta}(x_t)$,数据集由k个客户端创建:$D_k={x_i^k,y_i^k}$
existing work是这样训练模型的:使得其MSE最小。
本文中的攻击,会在自变量和因变量上加上扰动:$x_i^k+\delta_{x_i^k}$,$y_i^k+\delta _{y_i^k}$
数据中毒攻击–DL
数据中毒攻击的一假设是:攻击者只能参与数据的准备阶段,不能干扰模型的优化以及推导过程。
至于中毒攻击,无论是数据中毒还是模型中毒:
- 有目的性的数据中毒攻击会误导模型的预测结果
- 无目的性的数据中毒攻击则是降低模型的性能
模型中毒攻击–FL
模型中毒攻击能够直接修改上传的模型更新,这种中毒有着很好的攻击性能。但是一些先进的回归算法能够识别并且丢弃掉这些中毒更新,因此本文的工作之一是:将模型中毒看成一个优化问题–得到最优的中毒更新。
问题规划
DL based WATP
集中式
问题场景:
抽象为优化问题:
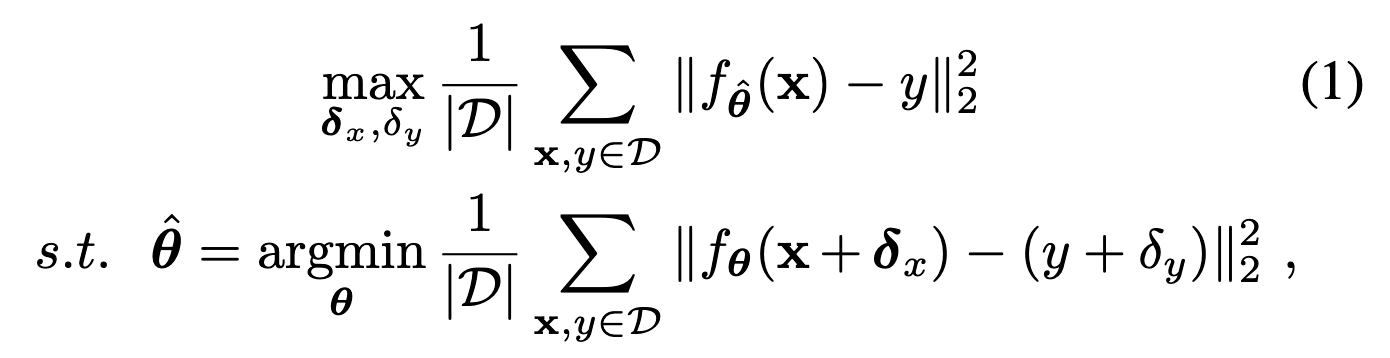
- 这两个式子的右边都是MSE loss的形式。
- 意思是:使得perturbation data的loss最小,求出参数$\theta$,然后使得clean data的MSE最大
- 这样虽然不能干涉调优过程,但是mislead了调优方向,从而mislead了output
分布式
问题场景
抽象为优化问题
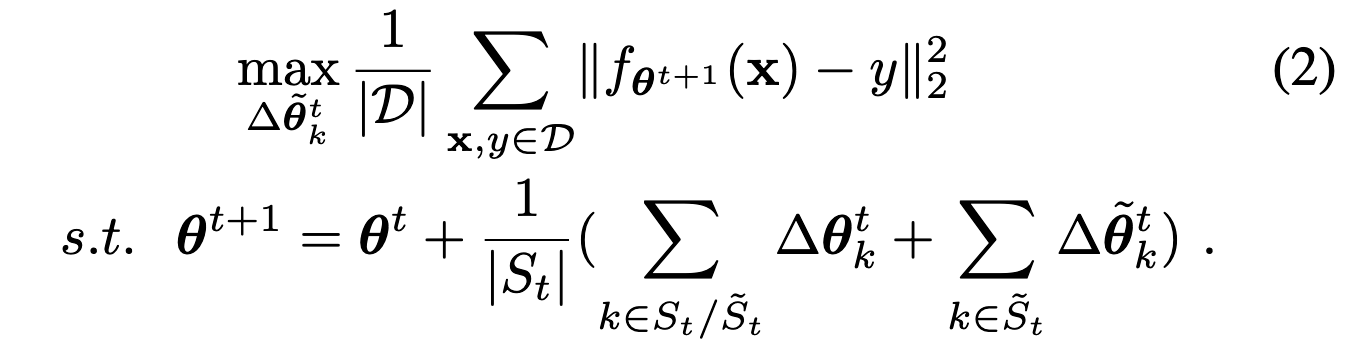
解读:下式是模型参数更新,使得更新后的模型的loss最大,从而降低performance
威胁模型
攻击者的目标
本文中主要是非目的性攻击,也就是单纯的降低模型的性能。
攻击者的认知
集中式场景下,攻击者只有自己的数据,并且不知道中心结点的服务器的神经网络架构。因此攻击者只能选择其他的架构,并初始化一个模型,并在上面做中毒数据的调整。
分布式场景下,假设攻击者每一个回合都能接收到服务器发来的权重,并且权重是没有加密的/或者是用一个普通的密钥来进行加密(若是每个client的密钥都不一样,那对于服务器的管理、客户端的解密都是非常麻烦的),即使没有接收到最新的模型权重,也可以用历史模型权重来代替它。
攻击者的能力
集中式场景下,会对perturbation加以限制;分布式场景下恶意客户端不会碰撞。
- 碰撞会给恶意客户端之间带来额外的沟通开销
- 碰撞会让恶意客户端提交更新延迟一点,这会让服务器产生怀疑
攻击算法
集中式
由于本文假设的是恶意客户端只有他自己的数据(这是全局数据的一个子集),因此用现有的方法可能会造成次优攻击(sub-optimal attack),意思就是掌握的信息不够多,可能发起的不是最优的攻击。
因此作者提出掩盖扰动策略:在有限的数据下,尽可能使得扰动数看起来正常。

分布式
普通的client是最小化loss,而malicious client是最大化loss(调优),然后对参数更新进行一个放缩。

防御
下面介绍几种潜在的防御方法。
只介绍了有用的两个,其他两个后面会作为反面教材进行测试。
数据消毒
有一种数据消毒方法为(existing work):先估计全部数据集的数据,找出数据的形心(data centroid),然后将距离这个中心最远的点移除。最简单的做法是,直接算出均值,作为形心的近似值。这种方法对于本文中考虑的场景并不适用。因此作者提出了adjacent distance:
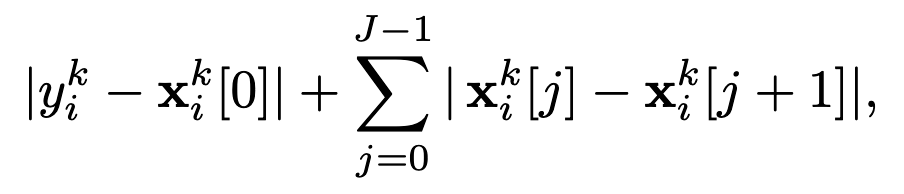
对所有的样本都计算出adjacent distance,然后把100p%的discard,p代表的是我们认为的潜在的malicious client的部分。
异常检测
- 计算出所有model update的$L_2$范数,取中位数记为$\mu _t$
- 将所有的$L_2$范数和$\mu _t$进行相除,取中位数,记$\sigma _t$
- 规定,所有model update的最大$L_2$范数不超过$c_1\mu _t$;并且不超过$\mu _t+c_2\sigma _t$
这个阈值是动态的,在本文的实验中,$c_1=40,c_2=400$比较好
