0.基本操作 1.使用Clion开发Rust 需要在系统的path里添加clion的bin路径,然后就可以通过命令行使用clion .来打开项目了。
2.使用cargo创建库项目 cargo new add –lib
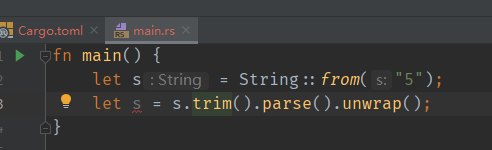
3.打印地址 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () { let o = Obj::new (1 , 2 , 3 ); let adr = &o as *const Obj as usize ; println! ("0x{:x}" , adr); } struct Obj { val1: u8 , val2: u8 , val3: u8 , } impl Obj { fn new (v1: u8 , v2: u8 , v3: u8 ) -> Obj { Obj { val1: v1, val2: v2, val3: v3, } } }
1 rust简介 1.1 基本特性 特性
运行时速度快
内存安全
并发
rust是一门安全的语言,表现在类型安全和内存安全(横向对比c/c++),同时性能也很好,因为没有GC(对比java),同时在设计的时候就考虑了多核处理器,支持并发,火狐公司的一个内核就是用rust写的,全并发执行。
rust采的命名方法是:蛇形命名法,也就是字母小写单词之间加下划线
rust的命令有rustc和rustup,rustc后面的c的意思是编译器。
1.2 命令行+vscode构建项目 步骤
mkdir hello_rust创建工程目录
cd h*进入目录
code .用vscode打开该工程
1 2 3 4 5 常用的windows cmd命令 1 . cd / --> 进入首盘,如c盘d盘2 . cd .. --> 进入上一级目录3 . dir --> 查看当当前目录下的文件 dir /a 是查看所有文件,包括隐藏文件4 . 可以用help cd查看cd的用法
1.3 编写hello world程序
fn表示函数声明
rust采用的缩进不是tab,而是四个空格
println!是rust的宏,也就是rust micro
rust是预先编译的语言,也就是先编译好,然后生成二进制文件,可直接交给别人使用,而无需rust环境
rustc只适用于简单的rust文件,用cargo
1.4 cargo创建工程 cargo是rust的创建及包管理工具
rust里代码的包称为crate
1 2 3 windows cmd 1 .rmdir xxx -- remove dir2 .del xxx -- delete file
cargo.toml文件
1 2 3 1 .toml是cargo的配置文件2 .前一部分是项目的信息,如项目名称,package,版本信息作者等3 .后部分是项目依赖
顶层目录可放置的信息
1 2 3 4 1 .README文件2 .许可信息3 .配置文件4 .其它与源程序无关的东西
当没有用cargo创建工程时,可以直接把文件拷贝到src下,然后再在顶层目录下编写一个cargo.toml文件即可
cargo.lock
1 2 1 .负责追寻项目依赖的准确版本2 .不需要去修改这个文件
使用cargo运行项目
1 2 1 .cargo run会编译当前工程的main.rs及相关文件,然后再运行生成的exe文件2 .如果源代码没有更改过的话,就不编译了,之既然运行exe
cargo check调试检查项目
一般在开发的时候都是用的这个命令来进行检查调试,因为更快。
只有要生成文件的时候才会使用run/build指令
如果要发布的话,使用cargo build --release,这样编译的时候时间更久,会进行优化,提高编译出来的程序的性能
2 rust基本语法 2.1 获取控制台输入 1.输入 std里提供了一个io,也就是标准输入输出,然后io里有一个关联函数叫stdin,是io里关于输入输出的输入那一部分,会返回一个句柄。然后stdin里有一个方法是read_line,读取命令行中的一行,这个方法可能抛出异常,所以该有一个except函数。
read_line会返回一个io::Result类型,也就是枚举类型,有两个值,一个是OK,另一个是Err,如果返回Err的话,就会中断当前程序,执行except那一部分。
1 std::io::stdin.read_line (&mut string).except ("exception message" );
关联函数类似于java中的静态方法。
rust会有一些默认的preclude的类型,预导入。要想使用其它的类型,需要使用use引入外部包。
use std::io 表示引入了标准库下的io这个包,该包下的所有类型都可以通过io::xxx来使用。
**io::stdin()**会返回一个句柄。句柄就是一个指针,可以是一个数或者其它内容,将OS或者数据库的某块内存关联起来,这是百度上的解释。下面是官方文档中的解释,可以结合参考。
1 2 3 A handle to the standard input stream of a process. Each handle is a shared reference to a global buffer of input data to this process. A handle can be lock’d to gain full access to BufRead methods (e.g., .lines()) . Reads to this handle are otherwise locked with respect to other reads.
2.输出 println!宏
1 println! ("这是一个数字:{}" , number);
{}中的就是number。
2.2 添加外部依赖包rand(修改toml文件) 在cargo.toml中添加bin结点。
1 2 3 4 5 6 7 8 9 10 11 12 13 [package] name = "guess_game" version = "0.1.0" edition = "2021" [[bin]] name = "guess_game" path = "src/test.rs" [dependencies] rand = "0.5.0"
然后cargo就会自动下载依赖包了。
为什么会自动下载包?
其实,是因为打开了rust server,这样就会自动去扫描toml里的依赖,检查版本并且及时下载对应的版本。
如果我们关闭这个server,那么更新toml中的依赖,工程文件中的包并不会更新,因为工程文件会去lock文件中去找到并使用对应的版本。这个时候不仅要修改toml,还要进行生级,也就是输入指令:cargo update。
但事实上使用这个指令需要换源,因为直接用的话,会提示超时,因为下载的源好像是github,需要用steam++加速或者换源。
cargo.lock文件是一个版本锁,锁住当前项目使用的包的版本。就算更新了toml文件,包也不会更新,除非使用cargo update
这里引入了一个Rng,是一个trait。若想使用类型A,A实现了trait B,那么需要同时use trait和类型。
这里就是引入了Rng和thread_rng()随机数生成器类型。
2.3 使用枚举进行比较 进行比较需要用到std下的cmp中的Ordering这个枚举类型。
进行枚举时需要注意一下两个问题:
1 2 3 4 5 6 7 let num1 : i32 = 1 ;let num2 : i32 = 2 ;match num1.cmp (&num2) { Ordering::Equal => println! ("=" ), Ordering::Greater => println! (">" ), Ordering::Less => println! ("<" ), }
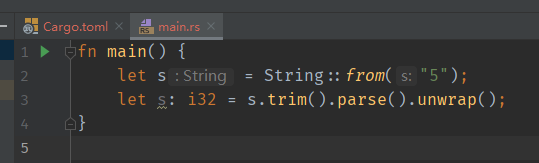
2.4 处理异常 前面我们使用的是except方法来处理异常,如parse将字符串转换成数字时,会返回一个Result,根据这个类型是OK还是Err来判断是否执行except中的内容。如果Result中判定为Err的话,会直接中断当前程序,然后程序结束(崩溃)。这样我们的程序一遇到非法输入就崩溃,并不健壮。
所以这里我们用了上一节中的match模式匹配来处理这个问题。如果是OK的话,就执行ok的代码块,如果是Rrr的话再做相应的应对措施(如提示用户重新输入)
1 2 3 4 5 6 7 let num : u32 = match num.trim ().parse () { Ok (num) => num, Err (_) => { println! ("{} is not valid input, try again" , num.trim ()); continue ; }, };
下面是完整的猜数字代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 use rand::{Rng, thread_rng};use std::io::stdin;use std::cmp::Ordering;fn main () { let ans = thread_rng ().gen_range (1 ..101 ); let hander = stdin (); loop { let mut guess = String ::new (); println! ("enter a num: " ); hander.read_line (&mut guess).expect ("unknown error" ); let guess : i32 = match guess.trim ().parse () { Ok (i) => i, Err (_) => { println! ("please enter a num" ); continue ; }, }; match guess.cmp (&ans) { Ordering::Equal => { println! ("right" ); break ; } Ordering::Greater => { println! ("greater" ); } Ordering::Less => { println! ("less" ); } } } }
3 变量及控制流 3.1变量 3.1.1 不可变变量 使用let关键字声明,将等号右边的值绑定到等号左侧。
3.1.2 可变变量 mutable,可变化的,还是使用let声明
1 2 let mut num = 1 ;num = num + 2 ;
3.1.3 常量 常量用const声明(constant的意思),常量必须显式声明数据类型,无法自动推断。
其实工程中大多数都是不可变类型的变量。
3.2 shadow机制 变量可以被隐藏。如下:
1 2 3 4 let string = "ssss" ;let string = string.len ();let string = string + 1 ;println! ("string is {}" , string);
此机制是为了避免以下情况:
1 2 String name_string = "jack" ;int name_length = name_string.length();
隐藏变量在在作用域外被定义,并绑定值后,在另一个作用域中被shadow后,出了此作用域,隐藏的变量会恢复。
1 2 3 4 5 6 7 8 fn main () { let s = "hello" ; { let s = 65535 ; } println! ("{}" , s) }
ps:shadow机制的实际意义是,重新创建了一个新的变量,这个变量可以有新的值,而它的意义就是既能够进行变量名称的复用 ,也能够不增加新的变量 。
3.3 标量类型 rust是静态数据类型,在编译时就需要所有变量的具体数据类型。并且rust提供了类型推断机制,根据值的类型和具体的使用情况,可以推断出变量的类型。若是不能推断出,编译器便会报错,需要我们给出更多的信息(一般是需要显示声明了就)。如下:
无法推断出字符串会转换成什么类型。所以需要我们显示声明:
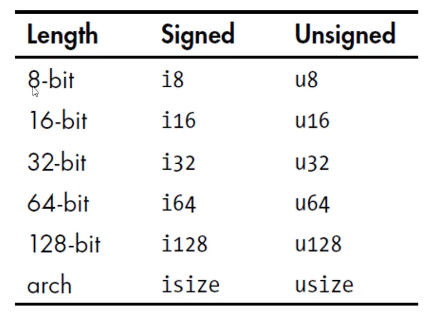
3.3.1 整数 整数的类型:
其中isize和usize和机器的位数有关,一般不用。
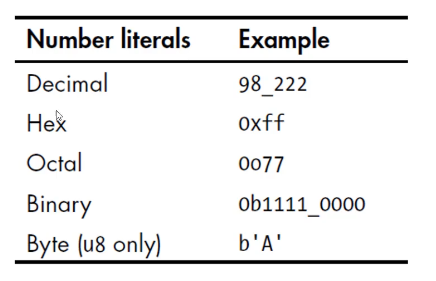
整数的字面量表示:
1 let adr = 0x1234_5678u64
整数的默认类型一般是i32,比较快。
下面是整数溢出的情况:
调试模式下:会发生panic(恐慌)
发布模式:不发生panic,选择环绕操作,即256=0
3.3.2 浮点 两种类型:
一般是采用f64
3.3.3 bool类型 true或者false。
占用大小一个Byte
为什么不用一个bit?因为如果用一位的话不利于存储,会产生内存碎片。
3.3.4 字符类型 char
1 2 let yeye = '👴';println! ("{}" , yeye);
3.4 复合类型 3.4.1 元组Tuple 每个位置对应一个类型,类型不必相同。
1 2 let tp = (1 , "sss" , "S" );println! ("{}{}{}" , tp.0 , tp.1 , tp.2 );
元组赋值
1 2 3 4 let tp = (1 , "sss" , "S" );let (x, y, z) = tp;println! ("{}{}{}" , x, y, z);
3.4.2 数组 和其他语言类似
1 2 let a = [1 , 2 , 3 , 4 ];println! ("{}" , a[1 ]);
3.4.5 Vector 大小可变,用的更多。
3.5 函数 函数声明,函数名,参数列表,返回值。这是声明函数的全过程。
代码块里的最后一行没加分号,代表是返回值。
1 2 3 4 5 6 7 fn main () { println! ("{}" , add (32 , 2 )) } fn add (x: i32 , y: i32 ) -> i32 { x + y }
或者这样也行:
1 2 3 fn add (x: i32 , y: i32 ) -> i32 { return x + y; }
3.6 if-else 第一种用法:
1 2 3 let cdt = true ;let num = if cdt { 1 } else { 2 };println! ("{}" , num);
第二种:
1 2 3 4 5 6 7 8 let cdt = true ;let num ;if cdt { num = 1 ; } else { num = 2 ; } println! ("{}" , num);
如果ifelse嵌套太多,使用模式匹配吧。
1 2 3 4 5 6 let cdt = false ;let num = match cdt { true => 1 , false => 2 }; println! ("{}" , num);
3.7 循环 3.7.1 loop 1 2 3 4 5 6 7 8 let mut count = 0 ;loop { count = count + 1 ; println! ("{}" , count); if count >100 { break ; } }
3.7.2 while 1 2 3 4 5 let mut count = 0 ;while count < 100 { count = count + 1 ; println! ("{}" , count); }
3.7.3 for - each 1 2 3 4 let arr = [1 , 2 , 3 , 4 , 5 ];for a in arr { println! ("{}" , a); }
1 2 3 4 let arr = [1 , 2 , 3 , 4 , 5 ];for a in arr.iter () { println! ("{}" , a); }
60s倒计时
1 2 3 for e in (1 ..61 ).rev () { println! ("{}" , e); }
4 所有权 rust采用所有权系统来管理内存。并且,是在编译时检查,这样就不会减慢程序运行的速度。无运行时开销。
4.1 栈内存与堆内存
堆栈:LIFO,last in first out,后进先出
堆:OS给用户在heap上找到一块足够大的区域,标记为在用,然后返回给用户。这就是在堆上分配内存。
堆是通过分配来得到内存,而栈不同,栈是直接将数据存放到那一个格子就行了,不需要分配。
栈上分配的内存是固定不变的,如数组。而堆上分配的内存可以动态变化,也就是可变数组,像C语言里的动态内存分配,就是在堆上分配空间,然后返回一个指针给用户(malloc函数返回指针)。而这个指针由于是固定大小,所以可以存到栈上去。
在堆上分配空间更慢,因为OS需要找到一块足够大的空间。而在栈上就比较快了,因为这个空间肯定在栈的顶端。
在堆上访问数据也慢,因为需要通过指针寻址来访问,是间接访问,需要跳转,从栈->堆,比较慢;而从栈上访问数据就不一样了,因为是栈->栈,所以快。
4.2 所有权规则
简化:在一个时间内,每个值有且只有一个变量,并且当所有者超出作用域时,所有者及其值将被删除。
4.3 初识String 之前的标量数据类型都是存储在stack上的,一旦离开作用域就会被弹出。
而String是一种存放在heap上的数据类型。
String可以代表std中复杂的数据类型,或者是我们自己创建的数据类型。
在程序运行中,有两种字符串:
字符串字面量:是不可变的。在程序运行之前,即在编译期间,就可以知道其内容了,所以直接硬编码到可执行文件中了。所以在运行期间就不需要额外的内存了,高效。
String类型:可变的,如获取用户的输入是,是不可预知的,用的就是String。String是在运行期间才会在heap上分配内存,通过from函数向OS申请内存。然后变变量超出作用域后,救会通过drop函数回收内存(自动的)。
1 let mut s = String ::from ("hello" );
下面解释一段程序:
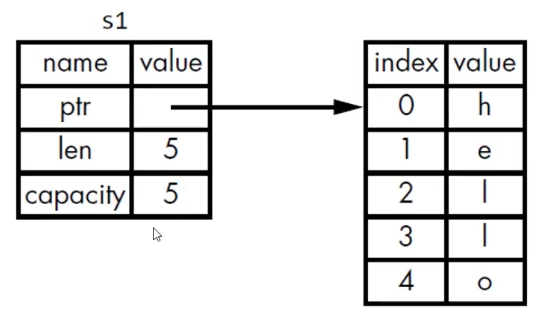
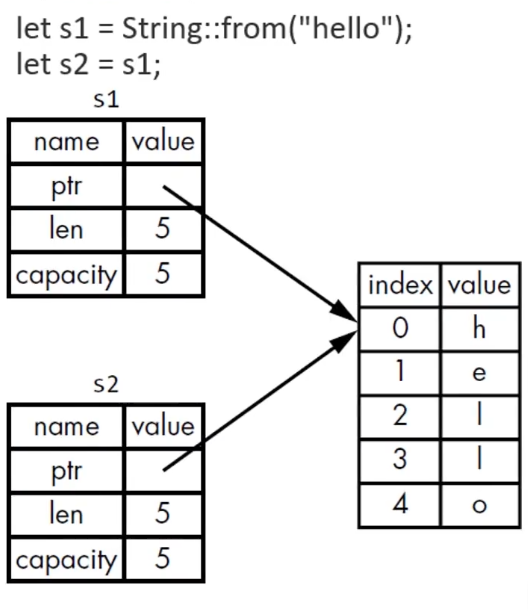
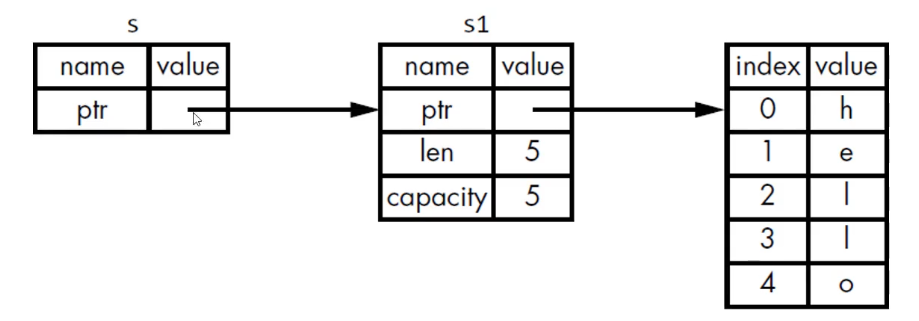
1 2 let s1 = String ::from ("hello" );let s2 = s1;
第一行向heap申请了一块内存。具体是如下:在堆上申请了一块空间,存放hello字符数组,然后返回这个字符数组的三个信息:起始地址,长度,容量。返回给s1接收。
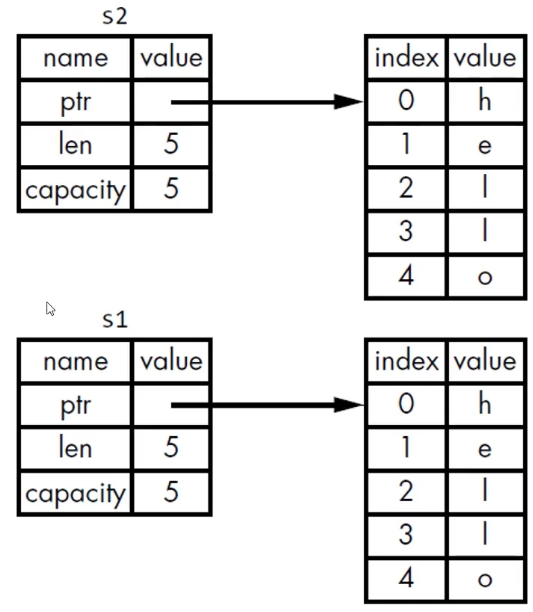
第二行是将s1的指针考培给了s2,包括heap指针,len和capacity。然后按照常规的思路,s1 s2都离开作用域时,都会进行drop回收内存。这样一块heap内存被回收了两次,是不安全的。
为了解决这个,在将s1指针拷贝给了s2后,也就是MOVE操作后,s1的内容被废弃,再次调用将出现报错。然后s1s2离开作用域后,只有s2指向的heap会被drop掉。
这样无疑更安全,也不会在堆上重新分配空间。
以上其实是一种浅拷贝,然是由于s1时失效了,于是创建了新的术语叫MOVE。
浅拷贝 – MOVE移动
深拷贝 – CLONE克隆
Rust所有的操作都是廉价的浅拷贝操作,不会开辟新的heap内存,除非是这样要求的。
下面的深拷贝,即克隆的操作。
而在栈上进行的MOVE,先前声明的变量就不会失效。
可以用下面两个概念来解释:
Copy trait(复制特性):实现了Copy trait的数据结构,在赋值后旧的变量仍然有效。
Drop trait(回收特性):实现了Drop trait的数据结构,不能再实现Copy trait
4.4 函数与所有权 将值窜给函数,要么会发生移动(Move),要么发生复制(Copy)
copy trait的数据类型被传入时(i32):传进去的时副本,在函数结束的时候,副本会被弹出stack
drop trait数据类型被传入时(String):传进去后,旧的变量丧失所有权,回收时不再使用drop清理heap内存。传进去的数据获得所有权,在函数结束时弹出堆栈并且使用drop回收堆内存
如果想即使用所有权,还能返回回来的话,可以使用元组
1 2 3 4 5 6 7 8 9 10 fn main () { let s1 = String ::from ("hello" ); let (s1, len) = get_len (s1); println! ("{} {}" , s1, len); } fn get_len (s: String ) -> (String , usize ) { let l = s.len (); (s, l) }
4.5 引用 引用:引用数据的值而不使用其所有权。&符号表示
引用分类:
不可变引用:不能修改指向堆上的数据
可变引用:可以修改指向堆上的数据
悬空引用:引用指向的数据已经被释放,而引用依然有效(Rust在编译期杜绝了这个问题)
有以下规则:
一个作用域内只能有一个可变引用
一个作用域内可以有多个不可变引用
同一个作用域内可变引用与不可变引用不能同时存在
可以看到:先声明了俩不可变的引用,然后声明了一个可变引用。如果不对不可变引用做操作的话,不会报错。如果在声明了可变引用后,还对不可变引用进行操作,这样就会报错。
4.5 切片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn main () { let mut s = String ::from ("ssss ssss" ); let indx = get_space_index (&s); s.clear (); println! ("{}" , indx); } fn get_space_index (s: &String ) -> usize { let p1 = s.as_bytes (); for (i, &item) in p1.iter ().enumerate () { if item == b' ' { return i; } } s.len () }
上面的代码是获取第一个空格所在的位置。
bug:当字符串被清空了后,得到的index不会发生改变,也就是同步性的问题。要保证:在字符串改变的同时,这个index也会同步改变。这很困难。
rust可以采用切片解决这个问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn main () { let s = String ::from ("ssss ssss" ); let indx = get_space_index (&s[..]); s.clear (); println! ("{}" , indx); } fn get_space_index (s: &str ) -> &str { let p1 = s.as_bytes (); for (i, &item) in p1.iter ().enumerate () { if item == b' ' { return &s[..i]; } } &s[..] }
因为函数里面采用了字符串切片,也就是不可变引用,所以修改时报错。
注意:字符串切片仅仅针对UTF-8的字符,两字节的汉字会报错。
还做了一个优化,把字符串引用修改成为了字符串切片,这样就能同时接收两种类型了(&String -> &str)。如字符串字面量(&str)和String类型。
数组也可以切片,和上面类似。
5 结构 5.1 结构定义 三类:
struct:普通结构
tuple struct:元组结构,当你想给元组起名字的时候,使用它。
Unit - like - struct:无任何字段的结构
普通结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct User { name: String , email: String , active: bool , id: u32 , } fn main () { let jack = get_user (String ::from ("jack" ), String ::from ("12222@qq.com" ), true , 1111 ); println! ("{}" , jack.active); } fn get_user (name: String , email: String , active: bool , id: u32 ) -> User { User { name, email, active, id, } }
元组结构
1 2 3 fn main () { struct Point (u32 , u32 , u32 ); }
5.2 结构实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #[derive(Debug)] struct rectangle { width: u32 , length: u32 , } fn main () { let r1 = rectangle{ width: 2 , length: 3 , }; println! ("{}" , get_area (&r1)); println! ("{:#?}" , r1); } fn get_area (rec: &rectangle) -> u32 { rec.length * rec.width }
Rust中有类似与java的toString方法,或者说是trait,但是默认没有实现,所以我们就用的是debug特性。
#[derive(Debug)]:实现debug trait
{:?}:输出结构的信息,不换行
{:#?}:输出结构的信息,换行
5.3 struct方法 两种:
方法:方法用impl定义的块去实现,需要传递它本身(或本身的引用)
关联函数:不需要传递本身,只是跟这个结构有关联,类似静态函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #[derive(Debug)] struct rectangle { width: u32 , length: u32 , } impl rectangle { fn area (&self ) -> u32 { self .width * self .length } fn can_hold (&self , other: &rectangle) -> bool { self .length >= other.length && self .width >= other.width } fn sqare (size: u32 ) -> rectangle { rectangle { width: size, length: size, } } } fn main () { let r1 = rectangle { width: 30 , length: 20 , }; let r2 = rectangle { width: 100 , length: 20 , }; let r3 = rectangle { width: 10 , length: 10 , }; println! ("{}" , r2.area ()); println! ("{}" , r1.can_hold (&r2)); println! ("{}" , r1.can_hold (&r3)); let r4 = rectangle::sqare (20 ); println! ("{:?}" , r4); }
6 枚举与模式匹配 6.1 定义枚举 rust的枚举很强大。可以自定义枚举并存储数据,不需要消耗额外的结构体。
1 2 3 4 5 6 7 8 9 enum IpAddrKind { V4 (u8 , u8 , u8 , u8 ), V6 (String ), } fn main () { let home = IpAddrKind::V4 (120 , 0 , 0 , 1 ); let r = IpAddrKind::V6 (String ::from ("::1" )); }
枚举也可以定义方法。与结构体相同使用impl
1 2 3 4 5 6 7 8 9 10 enum IpAddrKind { V4 (u8 , u8 , u8 , u8 ), V6 (String ), } impl IpAddrKind { fn express (&self ) { println! ("{}" , 1 ); } }
6.2 Option枚举 1 2 3 4 enum Option { Some (T), None , }
1 2 3 4 5 fn main () { let n = Some (5 ); let n1 = Some ("Sdssdffdsdsds" ); let n2 :Option <i32 > = None ; }
6.3 match math允许一个值与一系列的模式进行匹配,并执行匹配上的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 enum Week { Mon, Fir, Fun (String ), } impl Week { fn is_fun (one_day: &Week) -> bool { match one_day { Week::Fun (statement) => { println! ("{}" , statement); return true ; } Week::Mon => false , Week::Fir => false , } } } fn main () { let day = Week::Fun (String ::from ("no need to work!!!" )); Week::is_fun (&day); }
上面通过枚举存储了数据(String),并且通过模式匹配,将数据与statement绑定,重现了数据。
match必须列举所有的值进行匹配,若值太多了,使用_来代表其他的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 enum Week { Mon, Tue, Wed, Thi, Fir, Fun (String ), } impl Week { fn is_fun (one_day: &Week) -> bool { match one_day { Week::Fun (statement) => { println! ("{}" , statement); return true ; } Week::Mon => false , Week::Fir => false , _ => false , } } }
6.4 if-let语法糖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 enum Week { Mon, Tue, Wed, Thi, Fir, } fn main () { let day = Week::Fir; if let day = Week::Fir { println! ("{}" , "this is Firday" ); } else { println! ("{}" , "nonono" ); } }
等价于:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 enum Week { Mon, Tue, Wed, Thi, Fir, } fn main () { let day = Week::Fir; match day { Week::Fir => println! ("{}" , "this is Firday" ), _ => println! ("{}" , "nonono" ), } }
7 package crate module
7.1 定义 自顶向下:
Package:通过cargo可以创建一个新的包,位于最顶层。
Crate:cargo创建完包后,下面的.rs文件,有的会生成binary二进制文件(main.rs就是默认创建的binary文件,crate root),有的是产生library(其它的非main.rs文件)。Crate只能是以下两种类型:
Module:在一个.rs文件中,可以定义多个module。
Path:
还有一个概念叫crate root,是.rs源代码文件,编译器从这里开始组成我们的Module文件。
下面是Package的描述:
crate可以把相关的功能整合到一个作用域内,还可以避免命名冲突。
Module是在一个crate内,将代码进行分组,可以复用,并且可以控制代码的权限(pub or pri)。mod还是可以嵌套的。
7.2 权限
同级可以互相调用,父级不能调用子级的私有,子级可以调用所有父级的,无论暴露与否。外层mod加上了pub,里层的函数没加,函数依然是pri的。所以外面的mod里面的fn都需要加上pub才行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mod father { pub mod son_1 { pub fn fun1 () -> bool { false } } mod son_2 { fn fun2 () -> bool { true } } } fn testtt () { crate::father::son_1::fun1 (); crate::father::son_2::fun2 (); }
访问函数可以通过绝对路径和相对路径。建议绝对路径。
绝对路径:crate::father::son_1::fun1();
相对路径:
father::son_1::fun1();子级在调用父级的函数时,可以通过super关键字
7.3 结构的权限 结构默认为pri,并且结构的字段也是pri的,如果像设置乘公有的,加上pub
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 mod father { pub struct eat { pub time: (u16 , u8 , u8 , u8 , u8 ), pub food: String , } impl eat { pub fn to_eat (&self ) -> bool { println! ("is eating {} at {}.{}.{}.{}.{}" , self .food, self .time.0 , self .time.1 , self .time.2 , self .time.3 , self .time.4 ); true } } } pub fn testtt () { let jack = crate::father::eat { time: (2022 , 11 , 21 , 12 , 12 ), food: String ::from ("kaoji" ), }; jack.to_eat (); }
7.4 枚举的权限 枚举前面加上pub后,其里面的枚举变体自动变成公共的了。
7.5 use的使用 use 针对函数,use一般时引用它的上一级mod,而不是直接引入到函数本身,这样增强代码的可读性,避免函数冲突了。
而针对结构struct,enum的话,就是引入到本身,而不是父级条目。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pub mod father { pub mod son { pub struct eat { pub time: (u16 , u8 , u8 , u8 , u8 ), pub food: String , } pub fn cry () -> bool { println! ("wawawawa" ); true } } } use crate::father::son;use crate::father::son::eat;fn testtttt () { let s = eat { time: (2020 , 11 , 11 , 11 , 11 ), food: String ::from ("sasa" ), }; son::cry (); }
对于有同名的数据结构,有以下两种做法:
像函数一样,引入到父级条目下就停止,不到该数据结构。
可以使用别名,用as,指定一个别名。
可以看到报错了。
可以写成如下:
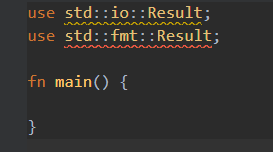
1 2 3 4 5 6 7 use std::io::Result as IoResult;use std::fmt::Result as FmtResult;fn main () { let p1 = IoResult::Ok (3 ); let p2 = FmtResult::Ok ; }
pub use 使用use导入mod后,这个mod对内部作用是可见的。而对如果外部去调用这个函数,对这个mod是没有访问权限的。所以这个时候可以使用pub use,这样这个模块对外部也是可见的了。
pub use 意思是重导出。
7.6 特殊的use使用
1 2 3 4 5 6 7 use std::io::Result as IoResult;use std::fmt::Result as FmtResult;--------> use std::{ io::Result as IoResult, fmt::Result as FmtResult, };
1 2 3 4 5 6 7 use std::io::Result ;use std::io;--------> use std::io::{ Result , self , };
通过通配符*引入全部的包(不建议经常使用),一般用于 以下情况
测试:将所有的公共条目引入测试test模块
预导入
7.7 引入自己写的mod 1 2 3 4 mod my_lib;fn main () { my_lib::father::son::cry (); }
如果mod的嵌套太多,可以创建一个新的同名文件夹,然后里面建立子mod的同名.rs文件。
可以用mod和use一起作用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 mod my_lib;use my_lib::father::son as son;fn main () { son::cry (); } pub mod father;pub mod son { pub struct eat { pub time: (u16 , u8 , u8 , u8 , u8 ), pub food: String , } pub fn cry () -> bool { println! ("wawawawa" ); true } }
树形结构:
1 2 3 4 5 src main.rs my_lib.rs my_lib father.rs
8 集合 集和是建立在heap上的数据,因此在编译时不需要去确定大小,在运行时会自动变化。
8.1 Vector 1.创建 有两种方式创建Vector
通过关联函数,这种情况需要显示的指明类型。
通过已有的值来创建
1 2 3 4 fn main () { let v1 : Vec <i32 > = Vec ::new (); let v2 = vec! [String ::from ("first" )]; }
rust有上下文推断机制,如果前面没有明确Vec的类型,这时会报错;然后后面添加了元素,又能够自动推断出类型了,报错会消失。
2.更新 我们使用第一种方式创建Vector,并且向里面添加元素。
1 2 3 4 fn main () { let mut v = Vec ::new (); v.push (1i64 ); }
3.清理 一般而言,离开作用域后,Vector就会被OS调用drop给清理掉。
4.获取 两种方法:
索引:得到的是数据本身
get方法:得到的是Some(T)或者None,其中T是不可变引用。
get更安全,可以对得到的数据进行类型判断,如果是Some就取出,是None就不取出,提示错误。
而索引的话,就会出现panic,程序恐慌。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 fn main () { let mut v = Vec ::new (); for num in (1 ..30i32 ).rev () { v.push (num); } let res : i32 = match v.get (10000 ) { Some (n) => { println! ("get it: {}" , n); *n }, None => { println! ("error" ); -1 }, }; println! ("{}" , res); }
因为Vec在heap上,所以有所有权的借用,用get得到的是引用,用索引的到的是本身。但是借用两边并不会报错(i32),说明是存放在栈上的,copy和move都一样 。这个地方是错误的,因为i32实现的是copy trait,所以使用等号时会在栈上压栈一个相同的数据。自然不会有所有权的问题。
1 2 3 4 5 6 7 8 9 fn main () { let mut v = Vec ::new (); for num in (1 ..30i32 ).rev () { v.push (num); } let n1 = v[0 ]; let n2 = v[0 ]; }
下面修改成String类型的试试。
1 2 3 4 5 6 7 8 fn main () { let mut v = Vec ::new (); v.push (String ::from ("hello" )); v.push (String ::from ("hello" )); let n1 = v[0 ]; }
错误信息如上。String没有实现copy trait,而是drop trait,如果操作成功,原来Vec里面对应位置的数据就会失效,所以只能采用借用,也就是用引用来获取。
而get默认的就是得到一个引用,用索引的话需要加上引用符号。
下面我们先通过索引加引用符号得到一个不可变引用,然后再添加一个元素进去,最后再打印这个不可变引用指向的值。
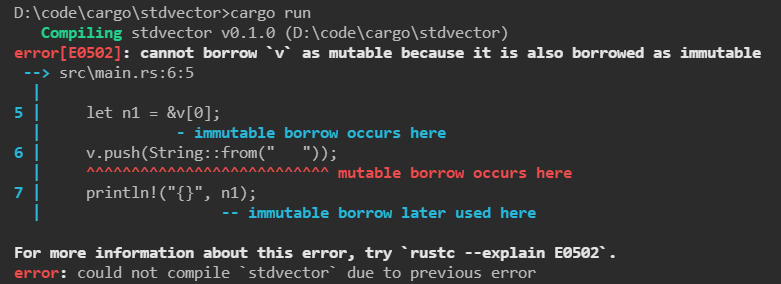
1 2 3 4 5 6 7 8 fn main () { let mut v = Vec ::new (); v.push (String ::from ("hello" )); v.push (String ::from ("hello" )); let n1 = &v[0 ]; v.push (String ::from (" " )); println! ("{}" , n1); }
原因是什么呢?
不可变引用与可变引用不能同时存在。
Vec的机制,因为在堆上分配的空间,所以空间可能不足,需要重新分配空间,然后进行一个数据的迁移,最后释放掉原来那部分的空间。如果发生这种情况,上面获取的不可变引用,它的指向是不会改变的,这样就指向了一片空的内存,是不安全的。所以编译器不允许这样的情况发生。
然后再次试了一下使用Vector存放i64,放很多数据。然后发生了栈溢出。
1 2 3 4 5 6 7 8 9 10 11 12 13 fn main () { let mut v = Vec ::new (); v.push (1i64 ); v.push (2i64 ); let n1 = v[0 ]; for num in (1 ..1000000000000000000i64 ) { v.push (num); } println! ("{}" , n1); }
换成String也会发生溢出。
然后查阅了相关资料,确定Vec是存放在栈上的。
5.遍历 通过for循环遍历,通过解引用*更新。
1 2 3 4 5 6 7 8 9 fn main () { let mut v = vec! [1 , 2 , 3 ]; for num in &mut v { *num = *num + 50 ; } for num in &mut v { println! ("{}" , num); } }
8.2 enum & vector 存放时直接存放就行,取出时需要根据类型取出。
1 2 3 4 5 6 7 8 9 10 11 12 13 enum InputKind { Int (i32 ), Float (f64 ), Text (String ), } fn main () { let v = vec! [ InputKind::Int (32 ), InputKind::Float (3.22222 ), InputKind::Text (String ::from ("hhhh" )), ]; }
8.3 String类型 1.创建字符串 两种方法:
字符串有初值:
1 let s = String ::from ("hhh" );
1 let s = "hhh" .to_string ();
2.更新
3.访问 不支持索引访问,只能用切片来访问。
原因有两个:
UTF8编码,一个Unicode值对应的字节数不是固定的。
索引操作应该消耗O(1)的时间复杂度,但是String无法保证。
1 2 3 4 5 fn main () { let s = "Hello_world" .to_string (); let p = &s[0 ..1 ]; println! ("{}" , p); }
4.内部表示 String时对Vec的包装,也就是一个可变字节数组。
有一个len方法返回的是它的字节数。
String有一个大坑,String里面存储的是字节,但是字符都有它的Unicode标量值,一个Unicode值不一定就是一个字节。如下:
汉字:1 Unicode – 3 Byte
英语:1 Unicode – 1 Byte
印度:1 Unicode – 2 Byte
这个时候我们访问,用字符串切割也要看响应的场景了。
Rust里有三种看待字符串的方式(自底向上):
1 2 3 4 5 6 7 fn main () { let s = "नमस्ते" .to_string (); for i in s.bytes () { print! ("{} " , i); } }
1 2 3 4 5 6 7 8 fn main () { let s = "हेलो बास्टियन" .to_string (); for i in s.chars () { print! ("{} " , i); } }
5.字符串切片的坑 使用[min..max]来进行切片,从[min, max - 1]
如果切割的不是完整的Unicode编码,不会报错,但会发生恐慌
1 2 3 4 5 fn main () { let s = "नमस्ते" ; let q = &s[0 ..1 ]; }
6.遍历 遍历在内部表示中提及。
8.4 HashMap 1.创建及插入
1 2 3 4 5 use std::collections::HashMap;fn main () { let mut map = HashMap::new (); map.insert (String ::from ("001" ), String ::from ("qcy" )); }
HashMap是同构的,所有的key是一种类型,value也是一种类型
上面是常规的创建方法,还可以使用tuple来创建。
1 2 3 4 5 6 use std::collections::HashMap;fn main () { let name = vec! ["qcy" , "qqccuy" ]; let age = vec! [12u8 , 13u8 ]; let map : HashMap<_, _> = name.iter ().zip (age.iter ()).collect (); }
先创建两个Vector,然后用一个vec生成一个迭代器,再跟另外一个vec的迭代器进行一一映射。然后再用collect方法打包返回一个hashmap。
那个<_, _>是会自动推断的,但是不可以省去。
向HashMap中插入数据时,如果数据是实现了copy trait的话,数据会被复制一份。如果是是西安了drop trait的话,数据会被一觉,所有权也会转移,源数据也会失效。
但如果插入的是引用,就不会发生所有权的移交了。
下面是通过get获取map中的值。
1 2 3 4 5 6 7 8 9 10 11 12 use std::collections::HashMap;fn main () { let name = vec! ["qcy" , "qqccuy" ]; let age = vec! [18u8 , 18u8 ]; let map : HashMap<_, _> = (&name).iter ().zip ((&age).iter ()).collect (); let res = map.get (&name[0 ]); match res { Some (r) => println! ("{}" , r), None => println! ("error" ), }; }
1 2 3 4 5 6 7 8 9 10 11 12 use std::collections::HashMap;fn main () { let name = vec! ["qcy" , "qqccuy" ]; let age = vec! [18u8 , 18u8 ]; let map : HashMap<_, _> = (&name).iter ().zip ((&age).iter ()).collect (); let res = map.get (&"hhh" ); match res { Some (r) => println! ("{}" , r), None => println! ("error" ), }; }
2.遍历 使用元组tuple和for-each进行遍历
1 2 3 4 5 6 7 8 9 use std::collections::HashMap;fn main () { let name = vec! ["qcy" , "qqccuy" ]; let age = vec! [18u8 , 18u8 ]; let map : HashMap<_, _> = (&name).iter ().zip ((&age).iter ()).collect (); for (k, v) in map { println! ("{} {}" , k, v); } }
3.更新 当向map中插入数据时,可能有三种情况:
数据不存在,直接插入即可。
数据存在
忽略原来的数据v,用新的v替换掉它 – insert()方法就是这样的
1 2 3 4 5 6 7 8 9 use std::collections::HashMap;fn main () { let mut m = HashMap::new (); let s = String ::from ("qcy" ); m.insert (&s, 0u8 ); m.insert (&s, 99u8 ); println! ("{:?}" , m); }
保留现在的v,忽略新的v – 使用entry来判断是否存在,用or_insert(v)方法来插入,如果k不存在,执行;存在,不执行。
1 2 3 4 5 6 7 8 9 10 use std::collections::HashMap;fn main () { let mut m = HashMap::new (); let s1 = String ::from ("qqcy" ); let s2 = String ::from ("qcwdfg" ); m.insert (&s1, 1u8 ); m.entry (&s2).or_insert (122u8 ); println! ("{:?}" , m); }
合并旧的v和新的v – 还是使用or_insert(v),来判断,若k存在会返回一个k的可变引用,可以对k进行修改。
1 2 3 4 5 6 7 8 9 10 11 12 use std::collections::HashMap;fn main () { let mut map : HashMap<String , u32 > = HashMap::new (); let text = String ::from ("h h h h h a a x c v b g r e qw s f gf g h h " ); let res = text.split_whitespace (); for i in res { let num = map.entry ((*i).to_string ()).or_insert (0 ); *num += 1 ; } println! ("{:?}" , map); }
4.Hash函数 一般默认情况下:
可抵御Dos攻击 – 良好的安全性
并不是最快的 – 性能一般
若是觉得性能不好,可以修改trait
9.错误处理 1.不可恢复的错误与panic!宏 大多编程语言在错误处理这方面提供了异常机制,没有对可恢复错误与不可恢复错误进行区分,而Rust没有异常机制,但他对错误处理进行了分类:
可恢复错误:如文件找不到,可再次尝试
不可恢复错误:如Vec越界访问
针对不可恢复的错误,我们有两种处理,展开或终止(abort)调用栈。
展开调用栈:Rust沿着调用栈往回走,清理遇到每个函数中的数据。
终止调用栈:直接终止程序,不进行清理。但是需要由OS来清理。
若想二进制文件更小,需要将默认的展开改成终止。
具体就是在cargo.toml中设置profile。
1 2 3 4 5 6 7 8 9 10 11 [package] name = "paniccccccc" version = "0.1.0" edition = "2021" [dependencies] [profile.release] panic = 'abort'
main.rs
1 2 3 fn main () { panic! ("hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh" ) }
or
1 2 3 4 5 6 fn main () { let v = vec! [0 , 1 , 2u8 ]; v[999 ]; }
顺便再次复习一下,v.get(999)并不会报错,得到的返回值是None
2.Result枚举与可恢复的错误 执行文件操作会返回一个Result的枚举变体,操作成功为Ok(T),失败为Err(E)
1 2 3 4 5 6 7 8 9 10 use std::fs::File;fn main () { let f = File::open ("xxx.txt" ); let res = match f { Ok (file) => file, Err (error) => { panic! ("{:#?}" , error); } }; }
下面是针对不同的错误,通过match做的一些处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 use std::{ fs::File, io::ErrorKind, }; fn main () { let f = File::open ("xxx.txt" ); let f = match f { Ok (file) => file, Err (error) => match error.kind () { ErrorKind::NotFound => match File::create ("xxx.txt" ) { Ok (msg) => msg, Err (msg) => panic! ("{:#?}" , msg), }, OtherError => panic! ("{:#?}" , OtherError), }, }; }
3.unwrap与expect替换match 上面我们用了很多match,代码的可读性还行,但太臃肿了。
下面提供一种unwrap()方法。
使用unwrap打开文件
1 2 3 4 use std::fs::File;fn main () { let f = File::open ("xxx.txt" ).unwrap (); }
使用unwrap创建文件
1 2 3 4 use std::fs::File;fn main () { let f = File::create ("xxx.txt" ).unwrap (); }
但是有一个缺点,unwrap无法定位错误信息(所有unwrap返回的错误信息都是一样的),所以下面介绍expect
expect与unwrap一样,单数可以控制输出的错误信息,精确的定位到处错在哪一行。
1 2 3 4 use std::fs::File;fn main () { let f = File::open ("xxx.txt" ).expect ("出错啦" ); }
4.通过函数将错误返回 将函数的返回值设置为一个Result枚举类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 use std::fs::File;use std::io;use std::io::Read;fn main () { let s = read_text (String ::from ("xxx.txt" )); match s { Ok (res) => println! ("{}" , res), Err (e) => panic! ("{:#?}" , e), } } fn read_text (path: String ) -> Result <String , io::Error> { let f = File::open (path); let mut f = match f { Ok (f) => f, Err (e) => return Err (e) }; let mut s = String ::new (); match f.read_to_string (&mut s) { Ok (_) => Ok (s), Err (e) => Err (e), } }
5.语法糖:”?” ?:执行一个操作
如果是Ok的话,就把Ok里的值作为结果绑定到变量。
如果是Err的话,就直接返回错误(注意main函数没有返回值,所以如果要使用”?”的话,需要加东西)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 use std::fs::File;use std::io;use std::io::Read;fn main () { let s = read_text (String ::from ("xxx.txt" )); match s { Ok (res) => println! ("{}" , res), Err (e) => panic! ("{:#?}" , e), } } fn read_text (path: String ) -> Result <String , io::Error> { let mut f = File::open (path)?; let mut s = String ::new (); f.read_to_string (&mut s)?; Ok (s) }
删掉注释后效果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 use std::fs::File;use std::io;use std::io::Read;fn main () { let s = read_text (String ::from ("xxx.txt" )); match s { Ok (res) => println! ("{}" , res), Err (e) => panic! ("{:#?}" , e), } } fn read_text (path: String ) -> Result <String , io::Error> { let mut f = File::open (path)?; let mut s = String ::new (); f.read_to_string (&mut s)?; Ok (s) }
非常精简。
然后再进行链式调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 use std::fs::File;use std::io;use std::io::Read;fn main () { let s = read_text (String ::from ("xxx.txt" )); match s { Ok (res) => println! ("{}" , res), Err (e) => panic! ("{:#?}" , e), } } fn read_text (path: String ) -> Result <String , io::Error> { let mut s = String ::new (); File::open (path)?.read_to_string (&mut s)?; Ok (s) }
6.main函数中如何使用”?”运算符 main的返回类型是(),也可以修改为Result,T对应的是(),E对应的是任意可能的错误类型(其实是一个trait对象7.)。
1 2 3 4 5 6 7 use std::error::Error;use std::fs::File;fn main () -> Result <(), Box <dyn Error>> { File::open ("xxx.txt" )?; Ok (()) }
7.何时使用panic! 总体原则如下:
尽量使用Result!将错误返回到代码的调用者,让他们决定如何去处理,如果我们觉得这个错误除了panic!,没有其它的解决办法,就直接使用panic!吧
10.泛型,trait,生命周期 1.泛型 Rust对类型的命名采用的是驼峰命名而非蛇形命名。
泛型的声明
1 2 3 4 pub struct Good <X, Y> { name: X, msg: Y, }
枚举(Option 和 Result<T, E>)
1 2 3 4 5 6 7 8 9 enum Option <T> { Some (T), None , } enum Result <T, E> { Ok (T), Err (E), }
注:针对具体的方法,impl后不需要接收泛型。如果是泛型方法,那么就需要
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fn main () {}pub struct Good <X, Y> { name: X, msg: Y, } impl <X, Y> Good<X, Y> { pub fn new (name: X, msg: Y) -> Good<X, Y>{ Good{ name, msg, } } } impl Good <String , String > { pub fn speak (self ) { println! ("{} {}" , self .name, self .msg); } }
使用泛型并不会影响性能。因为Rust使用了单态化
2.trait
类似于接口,告诉编译器哪些类型可以具有相同的功能。
还有一个trait bound的特性:要求传进来的泛型参数必须实现了对应的trait
trait的产生和接口是类似的,有些不同的类型会实现相同的方法。所以我们就把这些方法提取出来,实现一个trait。
1.定义 如下,只有方法签名,无具体实现。
1 2 3 4 pub trait Behavior { fn eat (self ); fn get_money (self ) -> i32 ; }
2.实现 my_lib.rs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 pub mod my_struct { use crate::my_trait::Text; pub struct Man { pub name: String , pub age: i8 , pub money: i32 , } pub struct Boy { pub name: String , pub age: i8 , } impl Text for Man { fn write (&self ) -> String { format! ("name is {}, age is {}, get money {}" , self .name, self .age, self .money) } } impl Text for Boy { fn write (&self ) -> String { format! ("i am {}, age is {}" , self .name, self .age) } } } pub mod my_trait { pub trait Text { fn write (&self ) -> String ; } }
main.rs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 use fanxingggggg::my_struct::{ Man, Boy, }; use fanxingggggg::my_trait::Text;fn main () { let m = Man { name: String ::from ("father" ), age: 40 , money: 100 , }; let b = Boy { name: String ::from ("boy" ), age: 18 , }; println! ("{}" , m.write ()); println! ("{}" , b.write ()); }
trait也可以使用默认实现,也就是在trait的定义时就实现trait。如果结构对trait的默认实现进行了重写的话,就不能再调用默认实现了。
3.将trait作为参数
1 2 3 4 5 6 7 8 9 10 11 12 13 pub mod my_struct { use crate::my_trait::Text; use std::fmt::Display; pub fn fun1 (object: impl Text + Display) { } } pub mod my_trait { pub trait Text { fn write (&self ) -> String ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 pub mod my_struct { use std::fmt::Display; use crate::my_trait::Text; pub fn fun <T: Text + Display>(o: T) { } } pub mod my_trait { pub trait Text { fn write (&self ) -> String ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 pub mod my_struct { use std::fmt::Display; use crate::my_trait::Text; pub fn fun <T>(o: T) -> String where T: Text + Clone + Display, { String ::new () } } pub mod my_trait { pub trait Text { fn write (&self ) -> String ; } }
3.生命周期 定义:让引用保持有效的作用域。
Rust有一个东西叫做借用检查器。会在编译的时候比较两个引用的生命周期的长短。
1.简单使用 当你写了一个函数时,向里面传了多个引用,然后对其进行一系列操作,最后返回一个引用时。需要用到生命周期。
因为编译器需要确保传进来的生命周期,与传出去的生命周期一样,或者说大于。
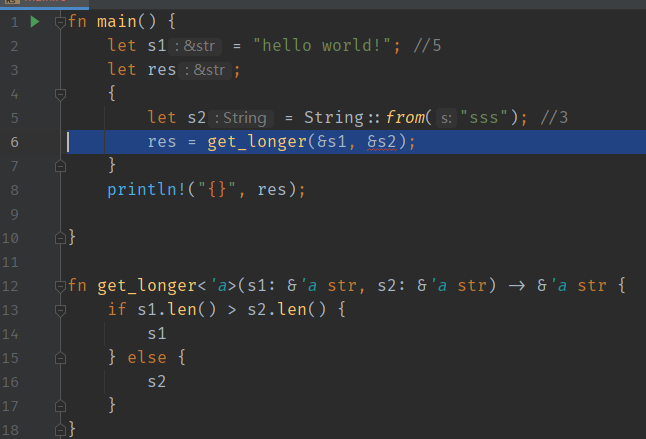
1 2 3 4 5 6 7 8 9 10 11 12 13 14 fn main () { let s1 = "hello world!" ; let s2 = String ::from ("sss" ); let res = get_longer (&s1, &s2); println! ("{}" , &res); } fn get_longer <'a >(s1: &'a str , s2: &'a str ) -> &'a str { if s1.len () > s2.len () { s1 } else { s2 } }
目的检查非法调用。
实际返回结果的生命周期是两个参数中生命周期较小的那一个。
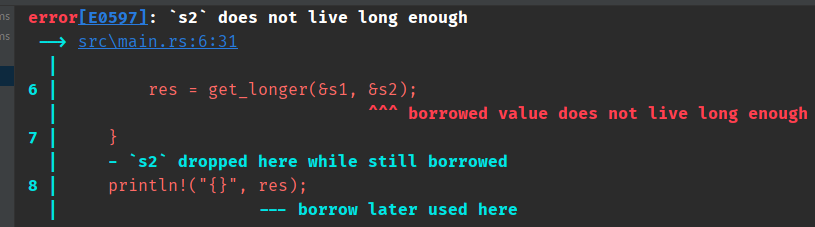
我们看下面这个错误调用。
通过函数,res的生命这些周期被缩短到和s2一样了。这样在外部继续调用的话,就会发生错误。
再试试Java里的效果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.example.reptile;public class TestD { public static void main (String[] args) { String s1 = "s" ; String res; { String s2 = "sss" ; res = s2; } System.out.println(res); } }
res的值和s2是一样的,这意味着s2并没有被GC回收掉。
2.函数的生命周期 函数的返回值的生命周期跟输入的参数的生命周期有关。
如果要返回一个引用,需要确保这个引用不会被回收(即不是本地变量)。
1 2 3 4 fn fun <'a >(s1: &'a str , s2: &'a str ) -> &'a str { let s = String ::from ("hello" ); &s }
返回的引用指向的堆已经被drop掉了,所以不行。这个引用叫悬垂指针。在Rust里,只要提供了足够的信息(生命周期),就不会发生这种情况。
如果想要使用在函数里的变量,建议返回一个String,移交所有权,而不是返回一个引用。
1 2 3 4 5 6 7 8 9 10 11 12 13 pub fn new (arg: &Vec <String >) -> Result <Config, String > { if arg.len () != 3 { return Err (format! ("arguments counts not good, find {}, need 2" , arg.len () - 1 )); } let p1 = &arg[1 ]; let p2 = &arg[2 ]; Ok ( Config { query: p1, file_path: p2, } ) }
3.struct的生命周期 与函数类似:
1 2 3 struct Man <'a > { name: &'a str , }
这里生命周期的意思是:字段存活的时间必须比结构久,不然的话字段先被回收了,结构还在,就会发生内存泄漏。
即绑定给name的数据的生命周期的存活时间必须要覆盖这个结构的生命周期。
4.生命周期省略的规则
每个引用类型的参数都有自己的生命周期
如果只有一个输入生命周期参数,那么这个生命周期参数将被赋给输出生命周期参数
如果有多个输入生命周期参数,但是其中之一是&self or &mut self,那么self的生命周期将被赋给输出生命周期参数。
5.静态生命周期 静态生命周期用`static,表示,意思是比那辆的存活时间和程序的存活时间是一致的。也就是说编译器在编译的时候就把这一部分作为二进制值写进去了。
只有实现了copy trait的变量才可以声明static
11.测试 测试三个步骤,3A
1.编写测试 在函数的上方加上 属性(aattribute)#[test]
1 2 3 4 #[test] fn fun () { println! ("hello world" ); }
2.运行测试 使用cargo test命令
3.断言的作用 1.assert! 断定此处为true!
可以接收一个bool类型,true通过,false则panic
1 2 3 4 5 #[test] fn ppp() { let f = false; assert!(f); }
2.assert_eq! 断定两个同类型的变量相等!
比如下面的assert_eq!,就是表明括号里面传入的参数肯定相等,不然就会报错。
1 2 3 4 5 6 7 8 #[cfg(test)] mod tests { #[test] fn it_works () { let result = 2 + 2 ; assert_eq! (result, 4 ); } }
还可以接收字符串。
1 2 3 4 5 #[test] fn it_works () { let result = String ::from ("hello" ); assert_eq! (result, String ::from ("hello" )); }
3.assert_ne! 与assert eq相反,ne的意思是not eq
4.给断言添加自定义消息 其实assert宏还有另外一个参数,可以传递字符串,而事实上这个字符串最终会传递给format宏。所以这个字符串里面可以添加占位符{},并且后面可以带参数。
1 2 3 4 5 6 #[test] fn it_works () { let i1 = 2 ; let i2 = 12 ; assert_eq! (i1, i2, "{} is not eq {}" , i1, i2); }
4.属性should_panic 在测试下面,函数上面再添加一条属性(attribute),叫#[should_panic]
表示下面的测试函数应该恐慌,不恐慌测试就不会通过。
1 2 3 4 5 #[test] #[should_panic] fn ggg () { panic! ("hello should_panic" ); }
可以通过在should_panic(expected = “”)添加参数,让测试更加精确一点。如添加了字符串参数,然后如果恐慌信息里包含了这个expected参数,那么就测试通过;反之,如果不包含,那么测试失败。
1 2 3 4 5 #[test] #[should_panic(expected = "hello" )] fn ggg () { panic! ("hello should_panic" ); }
5.使用Result枚举来进行测试 无需panic。
1 2 3 4 5 6 7 #[test] fn ggg () -> Result <(), String > { if 1 == 1 { return Ok (()) } Err (String ::from ("not eq" )) }
12.命令行项目 实现这样的功能:通过命令行,向程序中输入参数,一个是字符串,一个是文件绝对路径。然后找到这个绝对路径中跟字符串内容匹配的部分,并且打印出来。
1.接收命令行参数 使用std::env下的args接收参数,并调用collect方法,返回一个Vec
1 2 3 4 5 fn main () { let v : Vec <String > = env::args ().collect (); println! ("{:#?}" , v); }
2.读取文件内容 使用std::fs下的read _to_string 来读取,会返回一个result,所以我们调用except来处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 use std::env;fn main () { let v : Vec <String > = env::args ().collect (); let target = &v[1 ]; let path = &v[2 ]; let content = std::fs::read_to_string (path).expect ("read error" ); println! ("{}" , content); }
3.代码重构 遵循一个函数一个功能的原则,main函数现在太臃肿了。
选择将main.rs拆分成main.rs和lib.rs,将业务逻辑的实现放在libl里。
具体如下:
在main.rs里编写全部功能,可以忽略重构,忽略错误处理,只考虑理想情况。
将实现功能的业务逻辑抽取出来,独立成单个的函数。
在函数中进行错误处理,或者返回一个Result让main去处理。
最后将抽取出来的函数移动到lib里去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 use std::{env, fs, process};use std::error::Error;use cmdddddd::{Config, run};fn main () { let v : Vec <String > = env::args ().collect (); let config = Config::new (&v).unwrap_or_else (|error_msg| { println! ("problem happened: {}" , error_msg); process::exit (1 ); }); match run (&config) { Ok (()) => (), Err (err) => { println! ("got some problem; {:#?}" , err); process::exit (1 ); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 use std::error::Error;use std::fs;pub fn run (config: &Config) -> Result <(), Box <dyn Error>> { let query = config.query (); let path = config.file_path (); let content = fs::read_to_string (path)?; println! ("{}" ,content); Ok (()) } pub struct Config <'a > { query: &'a str , file_path: &'a str , } impl <'a > Config<'a > { pub fn new (arg: &Vec <String >) -> Result <Config, String > { if arg.len () != 3 { return Err (format! ("arguments counts not good, find {}, need 2" , arg.len () - 1 )); } let p1 = &arg[1 ]; let p2 = &arg[2 ]; Ok ( Config { query: p1, file_path: p2, } ) } pub fn query (&self ) -> &'a str { self .query } pub fn file_path (&self ) -> &'a str { self .file_path } }
4.使用TDD在lib里进行查错 TDD:test driver development,测试驱动开发
测试部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #[cfg(test)] mod tests { use super::*; #[test] fn to_test () { let content = "\n hi,\n rust-langn demo demo dododododod\n hello \n hhh\n s\n hhh\n hhh hanpi\n en\n" ; let query = "hhh" ; assert_eq! (vec! ["demo demo dododododod" ], search ("demo" , content)); } }
被测试的函数:
1 2 3 4 5 6 7 8 9 10 pub fn search <'a >(query: &str , content: &'a str ) -> Vec <&'a str > { let mut res = Vec ::new (); let lines = content.lines (); for line in lines { if line.contains (query) { res.push (line); } } res }
以后使用TDD来进行测试。测试样例与功能实现分离开。
5.使用环境变量进行选择 方法如下:
程序中:
1 let flag = std::env::var ("IGNORE_CASE" );
命令行中:IGNORE_CASE = 1 cargo run
这样就可以在程序中读到环境变量了。
6.进行错误信息定向输出 我们可以使用cargo run > output.txt 运行使得通过println!输出的内容定向到output.txt里面。
但是这样错误信息也输出到output里了。
可以使用eprintln!,将错误信息定向到控制台输出。
13.迭代器 闭包 1.闭包 1 闭包的定义 定义:可以捕获其所在环境的匿名函数。
闭包是一个匿名函数,他是将一个函数的定义存放在一个变量中去,而不是函数的执行结果。这个闭包只有在遇到向里面传输参数的时候,才会去执行函数,得到返回结果。
闭包并不需要显式声明它的参数和返回值类型。因为闭包是在当前作用域内工作的,范围狭小,不是作为接口去调用的。
1 2 3 4 5 6 7 8 #[test] fn ggg () { let bi_bao = |num| { println! ("the num is {}" , num); num }; assert_eq! (3 , bi_bao (3 )); }
将闭包绑定给变量后,变量的类型就是:variable bi_bao: fn(<unknown>) -> <unknown>
2用结构来存储闭包 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 struct Cashe <T> where T: Fn (u32 ) -> u32 , { calculation: T, value: Option <u32 >, } impl <T> Cashe<T> where T: Fn (u32 ) -> u32 { fn new (calculation: T) -> Cashe<T> { Cashe { calculation, value: None , } } fn value (&mut self , num: u32 ) -> u32 { match self .value { Some (n) => n, None => { let res = (self .calculation)(num); self .value = Some (res); res } } } } fn main () { let mut s = Cashe::new (|num| num + 1 ); println! ("{}" , s.value (32 )); println! ("{}" , s.value (92 )); }
上面结构中的calculation,是一个泛型参数T,并且加上了限制,要求这个泛型参数是实现了Fn trait的一个闭包。
但是只能存储一次。
可以用hashmap来进行改进。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 use std::collections::HashMap;struct Cashe <T> where T: Fn (u32 ) -> u32 , { calculation: T, value: HashMap<u32 , u32 >, } impl <T> Cashe<T> where T: Fn (u32 ) -> u32 { fn new (calculation: T) -> Cashe<T> { Cashe { calculation, value: HashMap::new (), } } fn value (&mut self , num: u32 ) -> u32 { let map = &mut self .value; match map.get (&num) { Some (res) => *res, None => { let res = (self .calculation)(num); map.insert (num, res); res } } } } fn main () { let mut s = Cashe::new (|num| num + 1 ); println! ("{}" , s.value (32 )); println! ("{}" , s.value (92 )); }
3.使用闭包捕获外部变量 闭包可以捕获和他定义于同一个作用域的变量。这是闭包独有的功能,而函数是没有的。
但是会产生额外的内存开销。
4.闭包的trait
Fn 不可变借用
FnMut 可变借用
FnOnce 取得所有权
可以使用move关键字将闭包外的所有权强行移动到闭包内。
1 2 3 4 5 fn main () { let v = vec! ["" ]; let bb = move ||v; println! ("{:#?}" , v); }
2.迭代器 1.iterator trait 实现next方法即可。
2.几个迭代api
iter:在不可变引用上创建迭代器
into_iter:创建的迭代器会获取所有权 – 用一个数据引出迭代器,并且夺取了元数据的所有权。
iter_mut:迭代可变的引用 – 可以通过解引用修改其中的值。
3.消耗/产生 迭代器 1.消耗(消耗性适配器) 消耗迭代器:当调用迭代器的next方法时,会消耗迭代器,迭代器中的元素会被一个一个消除掉,这就是叫消耗的原因。rust里有些方法(针对于实现了iterator trait的类型),会自主调用next,从而消耗迭代器。
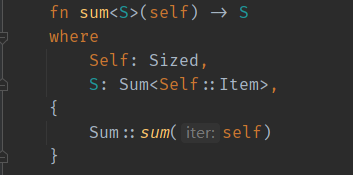
1 2 3 4 5 6 fn main () { let mut v = vec! [1 , 2 , 3 ]; let iterator = v.iter (); let res : i32 = iterator.sum (); println! ("{}" , res); }
要调用sum这个方法,self必须实现Sizd这个trait,并且泛型参数必须实现了Sum这个trait。
2.产生(迭代器适配器) 将一个迭代器转换成另一个迭代器。
1 2 3 4 5 6 7 8 9 fn main () { let mut v1 = vec! [1 , 2 , 3 ]; let iter1 = v1.iter (); let map = iter1.map (|num| { format! ("{}" , num) }); let mut v2 : Vec <_> = map.collect (); let iter2 = v2.iter (); }
map()方法:一个泛型方法,接收两个泛型参数,目的是将传进来的类型T更改成传出去的类型F。接收两个参数,第一个是self,要求实现了Sized这个trait。第二个参数是T,要求实现FnMut这个trait,也就是一个闭包,并且是可变引用,因为要对参数进行修改。
调用map方法后,迭代器的所有权被Move。
3.迭代器+闭包 捕获环境 使用filter()这个方法,一个迭代器适配器。接收一个闭包,这个闭包必须返回bool类型。若是返回true,则元素被加到迭代器里,最终作为这个方法的返回值。
1 2 3 4 5 6 7 8 9 10 fn main () { let mut v = Vec ::new (); for i in (1 ..100 ).rev () { v.push (i); } let i1 : Vec <_> = v.iter ().filter (|num| -> bool { **num > 90 }).collect (); println! ("{:?}" , i1); }
传进闭包后,要用collect进行收集,返回一个集合,不然闭包是不会执行的
4.构建自定义的迭代器 实现Iterator trait即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 fn main () { let mut e1 = Elem::new (); println! ("{}" , e1.next ().unwrap ()) } struct Elem { val: i32 , } impl Elem { fn new () -> Elem { Elem { val: 0 } } } impl Iterator for Elem { type Item = i32 ; fn next (&mut self ) -> Option <Self ::Item> { Some (0 ) } }
迭代器比for循环遍历要快一点。
用filter方法。
14.发布 15.智能指针 1.Box< T > Rust中所有的类型在编译时都会知道大小。
考虑C语言中的链表的实现,如下:
1 2 3 4 struct Node { int value; Node* next; }
有两个类型,一个是int,一个是指针。这实际就是一个递归,只不过递归的是指针,并不是结构,如果是结构的话,就永远无法知道声明一个struct的时候应该分配多少大小了。所以用的是指针。指针存放在栈上,就是一个地址而已。
rust也是类似的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fn main () { let l = Node { value: 1 , next: Some (Box ::new (Node { value: 2 , next: None , })) }; println! ("{:#?}" , l); } #[derive(Debug)] struct Node { value: i32 , next: Option <Box <Node>> }
Box这个类型就是一个智能指针,实现了两个trait,deref的目的是确保Box可以被当成一个引用实现;drop则是确保Box在离开作用域时,其指针(栈内存)和指向的数据(堆内存)都会被释放。
2.deref trait 1.用法 实现这个trait后,可以确保类型被当成引用来使用。
1 2 3 4 5 6 fn main () { let n = 3 ; let m = Box ::new (n); assert_eq! (3 , n); assert_eq! (3 , *m); }
2.实现Deref trait 给结构实现deref trait即可。
具体的话,就是指定一下类型,然后实现deref方法即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 use std::ops::Deref;fn main () { let m = 3 ; let n = MyBox::new (3 ); assert_eq! (m, *n); } struct MyBox <T>(T);impl <T> Deref for MyBox <T> { type Target = T; fn deref (&self ) -> &Self ::Target { &self .0 } } impl <T> MyBox<T> { fn new (value: T) -> MyBox<T> { MyBox (value) } }
3.deref coercion 假设实现了deref trait,然后传入的是引用,那么编译器就会自动调用deref方法,将&Box -> &T。
如下:
1 2 3 4 5 6 7 8 fn main () { let a = MyBox::new (String ::from ("hello" )); fun (&a); } fn fun (s: &str ) { println! ("{}" , s); }
首先将&MyBox -> &String,由于String类型实现了deref trait,所以 &String -> &str,所以参数就匹配了。
并且,所有的这些操作,都是在编译期完成的,不会产生额外的运行时性能开销。
3.drop trait 变量在离开作用域时,会自动调用drop方法,来释放相关的资源。
不可以提前调用drop trait的drop方法,但是可以提前释放资源,使用另外一个drop方法。
1 2 3 4 5 fn main () { let s = String ::from ("hello" ); drop (s); let s = String ::new (); }
4.Rc< T > 引用计数智能指针
1 2 3 4 5 6 7 fn main () { let s1 = Rc::new (String ::from ("hello" )); let s2 = Rc::clone (&s1); println! ("{}" , Rc::strong_count (&s1)); let s3 = Rc::clone (&s1); println! ("{}" , Rc::strong_count (&s1)); }
为什么要有Rc?
把Box传进去之后,Box会夺取T的所有权,所以如果还想复用T的话,或者是在别的地方传入Box,那么就会报错,因为T已经被移动了。
使用Rc就不一样了,如果函数接收的是Rc,那么传入Rc::clone(&T)就可以了,这个clone函数并不会深拷贝,只是增加引用计数,返回一个Rc。
使用了Rc,就相当于单个值有了多个所有者。
Rc使用的是不可变引用,如果是可变引用就会违反引用规则。并且,Rc只能在单线程下使用。
5.RfCell< T >
16.并发 1.多线程 创建线程的两种方式:
通过OS的api来创建 – 运行时小 – 1 : 1
语言自己实现的线程 – 运行时大 – M : N
Rust提供的是1:1线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 use std::thread;use std::time::Duration;fn main () { thread::spawn (|| { for i in 1 ..10 { println! ("thread: {}" , i); thread::sleep (Duration::from_millis (1000 )); } }); for i in 1 ..5 { println! ("main: {}" , i); thread::sleep (Duration::from_millis (1000 )); } }
这样写,一旦主线程结束了,我们创建的线程也就停止了。可以通过join方法来阻塞主线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 use std::thread;use std::time::Duration;fn main () { let j = thread::spawn (|| { for i in 1 ..10 { println! ("thread: {}" , i); thread::sleep (Duration::from_millis (1 )); } }); for i in 1 ..5 { println! ("main: {}" , i); thread::sleep (Duration::from_millis (1 )); } j.join ().unwrap (); }
可以使用move将主线程里的值的所有权强制移动到分线程。
1 2 3 4 5 6 7 8 9 10 11 use std::thread;fn main () { let v = vec! [1 , 2 , 3 ]; let j = thread::spawn (move || { for i in v { println! ("{}" , i); } }); j.join ().unwrap (); }
2.通过channel实现线程通信 通过mpsc的一个关联函数可以构造一个元组(send, receive)
mpsc的意思:多个生产者,一个消费者。multiple producer, single consumer
可以通过克隆来实现多个发送者。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 use std::sync::mpsc;use std::thread;fn main () { let (send, receive) = mpsc::channel (); let send1 = send.clone (); let j = thread::spawn (move || { let ss = ["hello" , "world" , "!" , "from" ]; for s in ss { send.send (s).unwrap (); } }); let j1 = thread::spawn (move || { let ss = ["111hello" , "111world" , "!" , "111from" ]; for s in ss { send1.send (s).unwrap (); } }); for r in receive { println! ("{}" , r); } j.join ().unwrap (); j1.join ().unwrap (); }
3.Mutex< T >共享内存 Mutex就是一个互斥锁,使用数据前需要先获取锁,然后使用完后需要释放锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 use std::sync::{mpsc, Mutex};use std::thread;fn main () { let n = Mutex::new (5 ); { let mut num = n.lock ().unwrap (); *num = 7 ; } println! ("{:?}" , n); }
mutex可能会产生死锁
4.Arc< T >原子引用计数 在外面克隆引用,然后把克隆的引用传进去。
1 2 3 4 5 6 7 8 9 10 11 12 13 use std::sync::{Arc, mpsc, Mutex};use std::thread;fn main () { let n = Arc::new (Mutex::new (5 )); let l1 = Arc::clone (&n); let handle = thread::spawn (move || { let mut num = l1.lock ().unwrap (); *num += 999 ; }); handle.join ().unwrap (); println! ("{:?}" , n); }
ceshi: